|
|
Статистические методы в языкознании
- методы использования счета и измерений для изучения языка
и речи.
Объектом применения
статистических методов обычно является письменный текст (в
первую очередь его лексический состав). |
Статистика электронного документа в MS Word
|
Текстовый процессор MS Word анализирует свойства
создаваемых в нем документов (название, автор, тема,
ключевые слова, дата последнего изменения), которые служат
для упрощения поиска документов.
MS Word
регистрирует и автоматически обновляет статистические данные
документа:
Доступ к просмотру
статистики документа:
-
Файл/Свойства/Статистика
-
Сервис/Статистика
Текстовый процессор
MS
Word позволяет после проверки правописания получить
статистику удобочитаемости документа
(характеризующую проверенный текст с точки зрения того,
насколько текст легко читается и насколько должен быть
подготовлен читатель для его прочтения).
Для ее просмотра должен
стоять флажок в позиции "статистика удобочитаемости" в окне
Правописание (Сервис/Параметры/Правописание).
Статистика
удобочитаемости включает:
-
Уровень
образования - показатель основан на образовательном
индексе
Флеша-Кинсайда и показывает, каким уровнем
образования должен обладать читатель проверяемого документа.
Подсчет показателя делается на основе вычисления среднего
числа слогов в слове и слов в предложении. Значение
показателя варьируется от 0 до 20. Значения от 0 до 10
означают число классов школы, оконченных читателем.
Следующие пять значений — от 11 до 15 — соответствуют курсам
высшего учебного заведения. Высшие пять значений относятся к
сложным научным текстам. Рекомендуемый диапазон значений
этого показателя: от 8 до 10.
-
Легкость чтения - показатель
основан на индексе легкости чтения Флеша. Показатель
подсчитывается по среднему числу слогов в слове и слов в
предложении и варьируется от 0 до 100. Чем выше значение
показателя, тем легче прочесть текст. Рекомендуемый интервал
значений для обычного текста: от 60 до 70.
-
Число сложных фраз -
показатель показывает в процентах, какое количество сложных
фраз содержится в проверенном тексте. Сложными считаются
фразы с относительно большим количеством знаков препинания,
перегруженные союзами, местоимениями, прилагательными и так
далее. Нормальным количеством сложных фраз можно считать 10
— 20 процентов.
-
Благозвучие - показатель
указывает на удобочитаемость текста с фонетической точки
зрения. Подсчет показателя основан на вычислении среднего
количества шипящих и свистящих согласных. Интервал изменения
показателя: от 0 до 100. Рекомендуемый диапазон значений: от
80 до 100. Этот индекс указывает на удобочитаемость текста с
фонетической точки зрения.
|
Цены на перевод для русского языка
Союз переводчиков (Беларусь, Минск)
17.01.2010
|
|
Язык |
Цена, BR* |
Язык |
Цена, руб* |
|
Азербайджанский |
66 000 |
Нидерландский |
42 000 |
|
Английский |
17 000 |
Норвежский |
60 000 |
|
Арабский |
48 000 |
Польский |
21 000 |
|
Армянский |
24 000 |
Португалький |
24 000 |
|
Белорусский |
17 000 |
Румынский |
42 000 |
|
Греческий |
48 000 |
Сербский (Хорватский) |
22 000 |
|
Грузинский |
42 000 |
Словацкий |
21 000 |
|
Иврит |
48 000 |
Турецкий |
66 000 |
|
Испанский |
22 000 |
Украинский |
21 000 |
|
Итальянский |
20 000 |
Французский |
18 000 |
|
Китайский |
42 000 |
Чешский |
21 000 |
|
Латышский |
30 000 |
Шведский |
60 000 |
|
Литовский |
24 000 |
Эстонский |
42 000 |
|
Молдавский |
42 000 |
Японский |
42 000 |
|
Немецкий |
17 000 |
|
*цена
указана за 1 расчётную страницу или за 1 стандартный документ
1 страница = 1 800 знаков полученного
текста включая пробелы
Минимальная стоимость заказа 1 страница
Срочный тариф - в 2 раза дороже
Сложный текст (медицинский, технический
и иной специализированный) - в 2 раза дороже
Дополнительные услуги:
-
Нотариальное заверение копии документа
-
Нотариальное заверение подлинности подписи переводчика
-
Проставление Апостиля (Apostille)
-
Легализация документа.
|
Статистика документа для переводчика
|
Переводчик или бюро
переводов осуществляют анализ объема текста в зависимости от
документа.
Если это обычный текст
в формате MS Word, то можно воспользоваться функцией подсчета статистики.
Цена
перевода вычисляется из числа расчётных страниц
1 страница = 1 800 знаков полученного
текста включая пробелы
Весь вопрос в том,
как подсчитать число знаков
|
Для подсчета слов в других, более сложных документах, требующих последующего анализа, могут использоваться как программы для подсчета слов, так и переводческие программы.
При таком разнообразии методов подсчета слов, оценки стоимости перевода, предоставляемые разными бюро, могут содержать разные данные о количестве слов в тексте.
|
Условия
выполнения заказа на письменный перевод
выдержки
|

Данные условия не распространяются на перевод художественной литературы.
ОСНОВНЫЕ ПОНЯТИЯ
Формат. Текст для перевода/переведенный текст представляется в формате MS Word, Excel, PowerPoint, HTML или ином формате по согласованию сторон. Во избежание несовместимости версий программного обеспечения сторонам рекомендуется согласовывать формат представления текста с указанием номера версии.
Нормативная выработка – 6 расчетных страниц переведенного текста в день при выполнении заказа на перевод в рабочие дни.
Полноценный перевод
– исчерпывающая передача смыслового содержания подлинника и максимально возможное функционально-стилистическое соответствие ему. Вместо термина «полноценный перевод» может употребляться термин «адекватный перевод» или «эквивалентный перевод».
Расчетная страница равна любой единице измерения, как правило, для текста перевода – 1680 знаков с пробелами или 250 слов.
Сложность – степень трудоемкости выполнения заказа на перевод. За единицу сложности принимается текст в формате MS Word. К повышенной сложности относятся тексты, представляемые заказчику по его требованию в иных форматах, например, Excel, PowerPoint, HTML и др.
ОБЩИЕ УСЛОВИЯ
3. Как правило, расчет объема работы производится по тексту перевода. Исходный текст служит основой для ориентировочного расчета, либо – когда заказчику надо заранее определиться с суммой оплаты и только по взаимному согласию сторон – для окончательного расчета.
5. Заказчик заблаговременно предоставляет переводчику необходимые для выполнения перевода справочные материалы и оказывает консультации по специфической терминологии.
7. Искусственное увеличение количества пробелов в переведенном тексте не допускается. При подсчете суммы вознаграждения избыточные пробелы из текста удаляются и в общий подсчет не включаются.
|
Особенности подсчета слов
в MS Word
|
1
|
Microsoft Word считает словами все, что находится между двумя пробелами
и при подсчете слов учитываются числительные и символы,
которые переводческие программы не включают в подсчет, так
как переводить их не требуется.
Пример:
1 2 3 @# + 4:
Вопрос
о том, следует ли учитывать при подсчете числительные и
символы спорный:
Позиция
1: раз их не нужно переводить, то и в подсчете их учитывать не следует,
Позиция
2: переводчику все равно приходится просматривать и проверять каждое числительное и символ, а значит, они должны быть включены в подсчет, особенно, если в документе содержится большой объем подобных данных.
|
|
2 |
MS Word не включает в подсчет текст в текстовых блоках, автоформах, колонтитулах и комментариях.

Для документов, где текстовых блоков много, это серьезно отразится на подсчете слов.
В практике могут быть получены документы на перевод, где из-за специфики проекта весь текст представлен в текстовых блоках
и отсутствие технологии адекватного способа подсчета слов может послужить причиной убыточности проекта.
|
|
3 |
Статистика MS Word не включает в подсчет текст во внедренных OLE-объектах
(листы Excel, внедренные в документ Word; диаграммы с текстом и т.п.).
В документе с множеством данных, содержащихся во внедренных листах Excel, низкие цифры статистики MS Word, могут иметь критическое значение.

OLE
(Object
Linking and Embedding)
- технология связывания и внедрения объектов для обмена
данными между отдельными приложениями. |
|
4 |
В случае HTML-файлов текст, содержащийся в выпадающих меню, в статистику MS Word не включается, особенно это касается файлов со встроенными раскрывающимися списками.
Заголовки HTML-страниц, названия кнопок и текст в мета-тегах статистика MS Word также не учитывает.
Каждый тег считается как
отдельное слово, из-за чего подсчет слов будет неточным.
tag
(тег)
1)
признак, хранящийся вместе со словом) , дескриптор; 2)
неотображаемый текст разметки документа в HTML-формате. |
PractiCount
and Invoice
|
Программа
PractiCount
and Invoice
— предназначена для фрилансеров, бюро переводов,
специалистов по переводу медицинских и юридических текстов,
писателей, руководителей проектов и других отраслевых
профессионалов, которым необходимо рассчитывать стоимость
работ по переводу текстов и документации и выставлять счета.
|
PractiCount
and Invoice
— quoting and
billing software solution for freelance
translators and translation agencies. The
program counts text in Word, Excel, PowerPoint,
WordPerfect, HTML and PDF files in batch mode
and generates detailed reports. Built-in client
database allows to make invoices with a click.
PractiCount comes with a free 15-day trial
period.
You can
download the trial version from www.practiline.com. |
PractiCount and Invoice
позволяет подсчитать:
-
Количество слов
-
Количество знаков с пробелами и без
-
Количество строк и символов в строках (с пробелами и без)
-
Количество символов в абзацах, сносках и колонтитулах
-
Количество страниц и символов на каждой странице
-
Количество печатных полос
-
Количество японских, китайских или корейских иероглифов
PractiCount and Invoice
поддерживает приложения и
форматы:
-
Microsoft Word (doc, rtf)
-
Microsoft Excel (xls, csv)
-
Microsoft PowerPoint (ppt, pps)
-
Corel WordPerfect (wpd)
-
HTML (htm, html, shtml)
-
XML, SGML, PHP, ASP
-
Adobe Acrobat (PDF)
-
Adobe Framemaker (mif)
-
файлы помощи (Help files) — cnt, hhc, hpj, hhk, hhp
Дополнительные функции
PractiCount and Invoice:
-
Вывод на печать
-
Экспорт результатов в Word
-
Экспорт результатов в Excel
-
Экспорт новых данных в уже существующие файлы
-
Подстановка данных в другие приложения
-
Редактирование отчётов
-
Импорт из csv и txt, экспорт статистики в csv, txt, html
и xls.
|
Статистика программ перевода
|
Wordfast
– это переводческая программа, которая при анализе объема
текста учитывает колонтитулы, сноски и примечания, считает
каждую группу внутренних тэгов за одно слово, что иногда
правильно, так как переводчику приходится работать с тегами.
Trados –
дополнительно включает в подсчет еще и несвязанные текстовые поля, чего не делает Wordfast,
при анализе объема текста игнорирует все теги.
Wordfast и Trados не включают в подсчет связанные поля и внедренные объекты.
Преимущество использования переводческой программы для подсчета слов состоит в том, что она позволяет посчитать и количество повторов в документе, благодаря чему можно соответственно снизить тариф на перевод.
В среднем, статистика Trados и Wordfast и PractiCount показывает
больше слов в файле, чем MS Word.
|
Анализ подсчета слов
|
|
Числительные и символы |
Ссылки и примечания |
Колонтитулы |
Текстовые блоки |
Внедренные OLE-объекты |
Теги |
|
MS Word |
да |
нет |
нет |
нет |
нет |
да |
|
Trados |
нет |
да |
да |
да |
нет |
нет |
|
WordFast |
нет |
да |
да |
да |
нет |
да |
|
PractiCount
and Invoice |
да |
да |
да |
да |
да |
да |
Частотные словари
|
Частотный словарь
- пронумерованный список слов
(словоформ, словосочетаний)
текста (множества текстов) с указанием абсолютной частоты
употребления этого слова в тексте.
Частотные словари приводят числовые характеристики
употребительности слов какого-либо языка.
Частотные словари
составляются по текстам отдельных авторов, произведений,
предметных областей.
Частотные словари
являются основой для создания электронных словарей,
компьютерных переводчиков, систем семантического поиска,
автореферирования и автоаннотирования текстов, автоматизации
изучения стилистических особенностей отдельных авторов и т.п.
Частотные словари дают возможность сравнить численные
закономерности в структуре словаря и текста.Эти словари
полезны во многих отношениях и представляют большую ценность
для преподавателей, методистов и лексикографов. Сведения о
наиболее частотных и коммуникативно важных словах того или
иного языка значительно расширяют возможности как успешного
преподавания иностранного языка, так и более глубокого
овладения родным языком.
Примеры
частотных словарей
-
Иоссельсон Г. [Josselson, H.] Словарь русского языка.
Детройт, 1953.
-
Штейнфельдт Э. А. Частотный словарь современного
русского литературного языка. Таллин, 1963.
-
Полякова Г. П. И Солганик Г. Я. Частотный словарь языка
газеты. М., 1971.
-
Частотный словарь общенаучной лексики / Под общ. ред. Е.
М. Степановой. М., 1970.
-
Грузберг А. А. Частотный словарь русского языка второй
половины XVI - начала XVII века. Пермь, 1974.
-
Оливерус Зденек Ф. Морфемы русского языка: Частотный
словарь. Praha, 1976.
-
Частотный словарь русского языка: Около 40 000 слов /
Под ред. Л. Н. Засориной. М., 1977.
-
Денисов П. Н. и др. Комплексный частотный словарь
русской научной и технической лексики: 3074 слов. М.,
1978.
-
Частотный словарь романа Л. Н. Толстого «Война и мир» /
Сост. Великодворская З. Н., Галкина Г. С. и др. Тула,
1978.
-
Караулов Ю. Н. Частотный словарь семантических
множителей русского языка / Отв. ред. С. Г. Бархударова.
М., 1980.
-
Сводный словарь современной русской лексики: В 2 т. /
Под ред. Р. П. Рогожниковой. Л., 1991. (Этот словарь
отчасти частотный; в большей степени он носит
справочно-библиографический характер.)
-
Лённгрен Л. Частотный словарь современного русского
языка. Uppsala, 1993.
|
Закон Ципфа
|
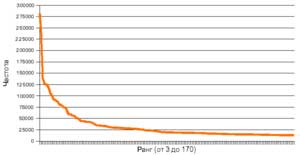 Закон Ципфа
— эмпирическая закономерность распределения частоты слов естественного языка:
если все слова языка (или достаточно
большого текста) упорядочить по убыванию частоты их использования, то частота n-го слова в таком списке окажется приблизительно обратно пропорциональной его порядковому номеру n (рангу
этого слова). Закон Ципфа
— эмпирическая закономерность распределения частоты слов естественного языка:
если все слова языка (или достаточно
большого текста) упорядочить по убыванию частоты их использования, то частота n-го слова в таком списке окажется приблизительно обратно пропорциональной его порядковому номеру n (рангу
этого слова).

Например: второе по используемости слово встречается примерно в два раза реже, чем первое, третье — в три раза реже, чем первое, и т. д.
Закон носит имя своего первооткрывателя — американского лингвиста
Джорджа Ципфа (George Kingsley Zipf) из Гарвардского университета.
Американский биолог
Ли Вэньтянь
пытаясь опровергнуть
закон Цифпа, строго доказал, что случайная последовательность символов подчиняется закону Ципфа.
Закон Ципфа, гипотетически, является чисто статистическим феноменом, не имеющим отношения к семантике текста. |
Философия
частотного словаря
|
УЧЕНИЕ ЯКОВА АБРАМОВА
(1893 - 1966)
Выдержки
"О мире мыслят не только философы, но и самые обыкновенные
люди. Они не доискиваются первоначала, а просто и здраво
рассуждают о множестве конкретных вещей, употребляя
необходимые им слова. Но благодаря этому обыкновенный язык и
приобретает необходимые им слова.
...В самых употребительных словах выражены самые устойчивые,
изначальные свойства бытия - те, глубже которых не может
пойти язык. Ведь мышление не может пойти дальше языка, в
границах которого себя выражает. Ни один философ, пишущий на
том или ином языке, не должен воображать, что он мудрее
самого языка, - и если его философия хочет выразить себя,
она должна принять за основу то, что считает основным сам
язык. На самом деле получается иначе: философы искажают
картину мира, данную в языке, всячески растягивая и
деформируя ее в разных направлениях, преувеличивая значение
одних понятий, преуменьшая значения других, - но язык
выносит это насилие, следы которого остаются мелкими рубцами
в его тысячелетней истории.
С точки зрения языка, "материя" и "сознание", "природа" или
"идея", которые многими философами клались в основу всего
сущего, - это понятия второстепенные, специальные,
возникающие лишь в процессе дробления и уточнения каких-то
более глубоких и всеобъемлющих свойств мироздания.
Слово "материя" делит места с 2172 по 2202 по частоте
употребления в русском языке, наряду со словами "самовар", "конференция",
"партизан" и др. Таким образом, по свидетельству языка
понятие "материи" примерно столь же важно для объяснения
мироустройства, как понятия "самовара" или "партизана" -
вывод, неутешительный для материалистов. Даже если сложить
вместе частоты таких однокоренных слов, как "материя", "материальный",
"материализм", "материалистический", данная металексема
получит ранг примерно 370, где-то среди слов "база", "палец",
"станция", "офицер" - почтенных, но никак не претендующих на
метафизическую важность.
К огорчению спиритуалистов, металексема "дух - духовный"
отмечена, по крайней мере в словаре русского языка советской
эпохи, примерно таким же или даже чуть более низким рангом;
правда, совместно с металексемой "душа - душевный" она
передвигается примерно на 163 место, в ряд таких слов, как "между",
"входить", "ничто", "второй", "понять", "всегда", гораздо
более существенных для постижения основ бытия.
Еще одно важнейшее понятие, положенное в основу многих
философских систем - это "бытие" или "существование". "Быть"
- важное, но не основное слово: в русском языке оно занимает
по частоте 6 место, в английском - четвертое, во французском
- четвертое. Другие категории, например, "разум" и "познание"
/у рационалистов/, "чувство" и "ощущение"/у сенсуалистов/, "польза"
и "деятельность" /у прагматиков и бихевиористов/, "воля" /у
Шопенгауэра/, "жизнь" /у Ницше/, также отвергается языком,
всей суммой его употребления, в качестве основополагающих. (Металексема
"делать - дело - действовать - деятельность" - 35-ое место,
"жить - жизнь" - 45-ое, "воля" - 65-ое. ).
Более существенны понятия "я" и "ты", выдвинутые М.
Бубером, - они принадлежат к самым употребительным в любом
языке, и никакое объяснение мира не может без них обойтись.
Бубер назвал местименную пару "я - ты" "основным словом",
определяющим диалогическое отношение как центральное в
мироздании; но если судить по словарю, отводящему этой
мелаксеме 3-е место в русском и английском языках, он
все-таки ошибся, хотя и ненамного.
Что же есть первоначало мира? - не по мнению мыслителя, а по
мнению языка, которое может мыслителем разъясняться и
обосновываться, но не оспариваться: приговор вынесен до
нашего рождения. Каким смертным унынием повеяло бы от этого
приговора, если бы он выразился существительным,
прилагательным, глаголом, - одним из тех знаменательных
слов, которыми философы знаменуют торжество своей системы
над действительностью. "Разум" - а я схожу с ума от любви.
"Дух" - а я копаюсь в песке или трогаю листья деревьев.
"Материя" - а я, кроме как в шелке или ситце, никогда ее не
трогал. "Быть" - а меня еще и нет, я только возможен.
"Знать" - а я и не знаю, что я знаю...
На фоне этих железных клеток - как легко парят, обдавая
невнятным, но чистым птичьим щебетом и ветерком, самые
первые слвоа из частотного списка: "в", "и", "не", "на",
"я"... Слова, чей смысл ни к чему не привязывает, никуда не
теснит, проходя через мысль как трепет самых первых, самых
робких и чистых прикосновений к действительности.
Вот без каких слов не могут обойтись люди в каждодневном
своем общении, в тысячах мыслей и высказываний о том и
другом - вот без каких начал не мог бы начаться сам мир:
если б не было "в", не было "и", не было самого "не".
Предлоги, союзы, частицы... И во главе их - по благодати,
которой удостоены не все языки - самые служебные из всех:
артикли.
Определенный артикль - наиболее употребительное слово в тех
языках, где он имеется, а на этих языках создана едва ли не
самая богатая и разнообразная словесность в мире: иврит,
греческий, арабский, английский, немецкий, французский,
испанский, итальянский, все скандинавские...
Если когда-нибудь сверхмашина создаст всемирный частотный
словарь, нет сомнения, что первое место в нем займет
определенный артикль.
Так, в английском языке из пяти миллионов словоупотреблений
"тче" используется 373123 раза, а следующее за ним по
частоте "ор" только 146001 раз.
Каждое 13-14-ое слово в английском тексте - это определенный
артикль. И даже в тех языках, где он отсутствует, его
различительную функцию отчасти берут на себя местоимения и
частицы, прежде всего указательные, от которых он
исторически образовался, - "этот", "тот", "такой", "вот",
"вон", а также определительные, ограничительные - "самый",
"который", "только", "лишь", "же" и др. - их суммарная
частота, например, в русском языке, приближает этот
"собирательный" или "несобранный" артикль к рангу второго
слова.
Определенный артикль, THE, и есть искомое слово слов,
выдвинутое самим языком на первое место среди бесчисленных
актов говорения о мире. Мир должен быть понят прежде всего
через артикль - всесторонне артикулирован. Не онтология и
гносеология - учение о бытии и познании, но "артикулогия",
учение о выделенном, определенном - вот центральный раздел
философии. Первоначало мира возвещено самим языком -
мудрейшим из мудрецов. Определенный артикль означает любую
вещь как эту, отличную от всех других вещей в мире, и это
свойство "Этости" является начальным и всеопределяющим, как
доказывает многообразная практика языка. В какие бы
предметные сферы ни заходил язык, какими бы профанами или
специалистами, праведниками или подлецами они ни
использовался, без артикля как определяющего и различающего
элемента не обойтись в большинстве высказываний.
"Данное мировоззрение можно назвать "the-ism" или "тэизмом",
вкладывая сюда двойной смысл - и тот, что закреплен за
каноническим понятием "theism", "теизм" как верой в
Бога-Личность, и тот, что привносится неканоническим
понятием "the" как определительным принципом мироздания.
Самое распространенное слово в самом распространенном из
всемирно-международных языков вполне заслуживает
философского признания. Необычный дефис в слове или замена
"е" на "э" служит лишь указанием на этот второй смысл,
сочетающий в едином понятии греческое Theos и английское
The. "The-ism" содержит в себе чудесную философскую идею - о
том, что вера в личного Бога, "theism", есть одновременно
учение о всеобщей определенности всех вещей, заимствующее
свое название от определенного артикля - "the-ism".
Бог-Личность обнаруживается в каждом явлении как его
собственная различенность, древнейшее Тeос как современное
the /без всякой историко-этимологической связи, как
сущностное единство, выраженное и в русских словах "личность"
- "различие"/...
В русском языке это определительное, артикулирующее начало,
вследствие отсутствия артиклей, выражено не столь резко, как
в европейских /романских и германских/. На первое место
выдвигается другое фундаментальное свойство - "вмещенность".
Оно выражено предлогом "в", опережающем все другие слова в
частотном списке /43 тысячи на миллион словоупотреблений,
каждое 23-е слово в тексте/. Все, что ни есть, вмещено во
что-то. Ничто не может быть, не будучи в чем-то. "В"-структура
определяет пребывание всякой вещи внутри другой: даже самое
малое что-то вмещает, даже самое великое чем-то объемлется.
Дом - в городе, город - в стране, страна - в мире, мир - в
сознании, сознание - в теле, тело - в доме... Все вмещено,
ничто не может выйти из окружения.
Русский язык берет мир в кольцо, в блокаду, представляя его
как систему оболочек, в которой все является облеченным и
облекающим. "Все во всем" - этот древний закон, выведенный
Анаксагором, в русском языке выступает как синтаксическая
привычка. Главное - не "это", а "в", через структуру
которого любая вещь предстает окруженной и окружающей,
притом, что эти круги входят друг в друга, наподобие звеньев
одной цепи: окружающее само окружается тем, что оно окружает.
Вселенная существует во времени, а время - во вселенной. Мы
застаем свое "я" - в мире, а мир - в себе /своем восприятии
и осознании/. Вот и вся проблема "материального" и "идеального",
соотношения приобретенных ощущений и врожденных идей: одно
заключено в другом, как звено в звене.
Русский язык рассеян в отношении определенности вещей и
сосредоточен на их окруженности, пребывания внутри чего-то.
Вещь определяется не сама по себе, в отличие от другой вещи,
но через то большее, внутри чего она пребывает. Вмещенность
не предполагает разграничения, а напротив, снятие
ограничений, включение их в объемлющее бытие и сознание.
Вещь заведомо дана не сама по себе, в "этости", а внутри
чего-то другого, как его включенное звено, через которое
вытягивается вся цепь. Таково это мирообразующее в России
свойство свернутости и заключенности. Вот почеми так трудна
и так необходима в России не только теория, но и практика
Всеразличия - действенный тэизм, идущий от веры в Личность к
удостоверяющим ее различиям"/Александр Франк. "Theism" и
"The-ism"/.
Таково в самом общем виде учение Я.А. о перворазличии, о
Перволичности, о первослова.
__________________________________
Все эти данные приводятся А.Пушниковым по "Частотному
словарю русского языка", под ред, Л.Н. Засориной, М., 1977.
|
kmp
|