|
Статистические
методы обработки текста |
Статистические методы
обработки текста
—
методы использования счета и измерений для изучения языка
и речи на материале текстов.
Объектом применения
статистических методов обычно является письменный текст (в
первую очередь его лексический состав).
Предметом
статистических
методов
обработки текста являются статистические (числовые)
закономерности текстов.
Применение статистических методов в языкознании
становится целесообразным только на значительном по
объему текстовом материале, что предполагает
и делает необходимым автоматизацию измерений и
счета.
Наибольшую эффективность статистические методы в языкознании
получают в контексте
Bid Data.
Статистические методы
являются важнейшим компонентом
квантитативных методов (как более широкого набора
методов).
Статистические методы
широко используются в компьютерном моделировании.
|
Компетентное мнение
 Игорь Милославский
(профессор МГУ): Игорь Милославский
(профессор МГУ):
-
Идеи и методы
математики по отношению к русскому языку эффективно используются уже
более полувека. Язык - это сложный многоаспектный
код, в единицах которого "зашифрованы" разными способами наши
представления об окружающей действительности.
-
Данное от рождения и
воспитания более или менее бессознательное умение пользоваться этим
кодом - совсем не то же самое, что строгое, объективное знание о том,
как он устроен и работает.
-
Но только на основе именно такого знания
можно осуществлять автоматический анализ и синтез текстов, делать
машинный перевод.
-
Представление о том, что пренебрегающий математикой
школьник может стать в будущем хорошим ученым в области гуманитарных
наук, в частности лингвистики, безнадежно устарело.
-
Будучи филологом,
я полностью соглашаюсь с утверждением: "Математики не может быть много".
|
Области
использования
Статистические методы обработки текста используются для:
-
Математически точного
различения стилей и жанров
(статистическая стилистика);
Так, в немецкой художественной литературе среднее число
слогов в слове 1,5-1,9 (англ. 1,3-1,5), в научной
1,9-2,3 (англ. 1,5-1,8). По авторам: самые скупые на
слоги Рильке, Хемингуэй, Диккенс, самые щедрые К.Маркс и
А. Гумбольдт. По чередованию ударных и безударных слогов
определяется величина метрической связи, которая
возрастает о научных текстов к поэзии. Здесь лидеры:
Байрон, Данте, Рильке, Пушкин, Шекспир, Гете, Брехт,
Гомер, Вергилий, Овидий, К Маркс, Ю.Цезарь.
-
Проведения атрибуции
текстов
(установление авторства анонимных текстов в
историческом языкознании и т.д.) на основании
неповторимого сочетания статистических параметров
авторского текста;
-
05.01.2016
Многие разработчики программного обеспечения, по
разным причинам желают сохранить свою анонимность. С
помощью построения абстрактных синтаксических
деревьев на основе разбора исходного текста удалось
выделить устойчивые отличительные признаки при
написании кода, которые трудно скрыть даже
целенаправленно. Используя машинное обучение и набор
эвристик, удалось добиться точности средней точности
определения авторства в 94% среди выборки из 1600
программистов Google Code Jam.
-
В своей новой работе, исследователи
продемонстрировали, что деанонимизация возможна и
через анализ уже скомпилированных бинарных файлов в
отсутствии исходных кодов. Исходные коды 600
участников Google Code Jam были скомпилированы в
исполняемые файлы, а потом подвергались разбору.
Задания на соревнованиях были одинаковы для всех и
разница файлов заключалась в значительной степени
именно в стиле программирования, а не в алгоритме.
Изначально, при сборке бинарных файлов отключались
оптимизации компилятора и не применялась обфускация
исходных кодов. Но отличительные признаки
сохраняются и при применении этих способов сокрытия
авторства, снижая точность деанонимизации до 65%.
-
Марина
Серова
(выпускница юрфака МГУ.
Работала в Генеральной прокуратуре. С 1987 года по настоящее
время - сотрудник одной из специальных служб. Участвовала в
боевых операциях и оперативных мероприятиях...): писатель-фикция;
торговая марка, под которой работает коллектив книггеров под
руководством литагента Сергея Потапова.
-
Описания поведения
языковых единиц
(букв, морфем, слов) в тексте
(их распределение, сочетаемость, частота употребления);
-
Измерения информативности
текстов
(количества информации содержащейся в тексте и
его составных частях) Так в соответствии с формулой
Клода Шеннона (1948)
[1]
количество информации которую несет одна буква русского
алфавита равна 3,01 бита, английского - 3,1,
французского 2,83 бита. Траты информации на ритм и рифму:
в классическом четырехстопном ямбе 10 и 7 бит, в
современном четырехдольнике 5 и 8 бит. Ослабление
ритмических ограничений в современной поэзии усилило
ограничения по рифме: практически исчезли простые
грамматические рифмы (окном-пером, стоять-лежать и т.п.)
За счет передачи смысла через ритм, рифму, звуковую
инструментовку поэзия, как правило, информационно богаче
прозы. Но, информационная плотность “Поединка” Куприна,
вдвое больше заурядных стихов с отрывного календаря (сопоставление
кафедры теории вероятностей МГУ).
-
Восстановления текстов и
языков по их фрагментам
(описания структуры текста и языка на основании очень
ограниченной исходной информации (в сочетании с
дистрибутивным анализом, изучающим окружение отдельных
единиц текста без использования сведений о его полном
лексическом составе);
-
Определения уровня родства, скорости языковых изменений
и времени разделения различных языков
(глоттохронология);
-
Определения типологии языков
(их сравнительное соотношение и изучение независимо от
характера генетических отношений) (квантитативная
типология) и т.д.
[1]
Формула для измерения
информации о событиях, происходящих с разной вероятностью.
|
Частотные
словари
|
Основой статистической обработки текста является частотный словарь.
Частотный словарь
(или
частотный список) — набор слов
(словоформ, словосочетаний)
текста (множества текстов,
языка, подъязыка) вместе с
информацией о частоте их встречаемости.
Частотные
словари:
-
практический результат статистического изучения лексики.
-
приводят числовые характеристики
употребительности слов (словоформ, словосочетаний) какого-либо языка.
-
составляются по текстам отдельных авторов, произведений,
предметных областей.
-
являются основой для создания электронных словарей,
компьютерных переводчиков, систем семантического поиска, автореферирования и автоаннотирования текстов, автоматизации
изучения стилистических особенностей отдельных авторов и т.п.
-
дают возможность сравнить численные
закономерности в структуре словаря и текста.
Частотные словари
полезны во многих отношениях и представляют большую ценность
для преподавателей, методистов и лексикографов. Сведения о
наиболее частотных и коммуникативно важных словах того или
иного языка значительно расширяют возможности как успешного
преподавания иностранного языка, так и более глубокого
овладения родным языком.
Словарные единицы
в частотных словарях
располагаются
Частотные словари характеризуются следующими параметрами:
|
Частотные
словари: история создания
|
Первым частотным словарем был словарь Кединга (1898).
Первым частотным
словарем русского языка был словарь Г. Йоссельсона (США, Детройт, 1953).
В
СССР первый частотный словарь русского языка был составлен Э.
Штейнфельд (1963).
В 1977 г. вышел в свет «Частотный словарь русского языка»
под редакцией Л.Н. Засориной. Создан на основе выборки в один
миллион словоупотребленийиз четырех жанров (художественная проза,
драматургия, научная публицистика, газетно журнальные материалы). В нем
около 40 тыс. слов. Самое частотное слово — предлог в (во), далее идут
служебные слова и местоимения (и, не, на, я, быть, что, он, с, а, как,
это). Самое частотное существительное — год.
В 90 х годах XX в. в Швеции вышел в свет «Частотный словарь современного
русского языка» (Уппсала, 1993).
Современные
частотные словари создаются на основе лингвистических корпусов.
О.
Н. Ляшевская, С. А. Шаров,
Частотный словарь современного русского языка
(на материалах Национального корпуса русского языка). М.:
Азбуковник, 2009.
http://dict.ruslang.ru/freq.php?
|
Примеры
частотных словарей
|
-
Иоссельсон Г. [Josselson, H.] Словарь русского языка.
Детройт, 1953.
-
Штейнфельдт Э. А. Частотный словарь современного
русского литературного языка. Таллин, 1963.
-
Полякова Г. П. И Солганик Г. Я. Частотный словарь языка
газеты. М., 1971.
-
Частотный словарь общенаучной лексики / Под общ. ред. Е.
М. Степановой. М., 1970.
-
Грузберг А. А. Частотный словарь русского языка второй
половины XVI - начала XVII века. Пермь, 1974.
-
Оливерус Зденек Ф. Морфемы русского языка: Частотный
словарь. Praha, 1976.
-
Частотный словарь русского языка: Около 40 000 слов /
Под ред. Л. Н. Засориной. М., 1977.
-
Денисов П. Н. и др. Комплексный частотный словарь
русской научной и технической лексики: 3074 слов. М.,
1978.
-
Частотный словарь романа Л. Н. Толстого «Война и мир» /
Сост. Великодворская З. Н., Галкина Г. С. и др. Тула,
1978.
-
Караулов Ю. Н. Частотный словарь семантических
множителей русского языка / Отв. ред. С. Г. Бархударова.
М., 1980.
-
Сводный словарь современной русской лексики: В 2 т. /
Под ред. Р. П. Рогожниковой. Л., 1991. (Этот словарь
отчасти частотный; в большей степени он носит
справочно-библиографический характер.)
-
Лённгрен Л. Частотный словарь современного русского
языка. Uppsala, 1993.
О. Н. Ляшевская, С. А. Шаров,
Частотный словарь современного русского языка
(на материалах Национального корпуса русского языка).
М.: Азбуковник, 2009.
http://dict.ruslang.ru/freq.php?
|
Закон Ципфа
|
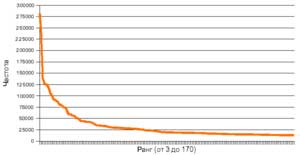 Закон Ципфа
— эмпирическая закономерность распределения частоты слов естественного языка:
если все слова языка (или достаточно
большого текста) упорядочить по убыванию частоты их использования, то частота n-го слова в таком списке окажется приблизительно обратно пропорциональной его порядковому номеру n (рангу
этого слова). Закон Ципфа
— эмпирическая закономерность распределения частоты слов естественного языка:
если все слова языка (или достаточно
большого текста) упорядочить по убыванию частоты их использования, то частота n-го слова в таком списке окажется приблизительно обратно пропорциональной его порядковому номеру n (рангу
этого слова).

Например: второе по используемости слово встречается примерно в два раза реже, чем первое, третье — в три раза реже, чем первое, и т. д.
Закон носит имя своего первооткрывателя — американского лингвиста
Джорджа Ципфа (George Kingsley Zipf) из Гарвардского университета.
Американский биолог
Ли Вэньтянь
пытаясь опровергнуть
закон Цифпа, строго доказал, что случайная последовательность символов подчиняется закону Ципфа.
Закон Ципфа, гипотетически, является чисто статистическим феноменом, не имеющим отношения к семантике текста. |
Философия
частотного словаря
ЯКОВА АБРАМОВА
(1893-1966)
Выдержки
...В самых употребительных словах выражены самые устойчивые,
изначальные свойства бытия - те, глубже которых не может
пойти язык. Ведь мышление не может пойти дальше языка, в
границах которого себя выражает.
Ни один философ, пишущий на
том или ином языке, не должен воображать, что он мудрее
самого языка, - и если его философия хочет выразить себя,
она должна принять за основу то, что считает основным сам
язык.
С точки зрения языка, "материя" и "сознание", "природа" или
"идея", которые многими философами клались в основу всего
сущего, - это понятия второстепенные, специальные,
возникающие лишь в процессе дробления и уточнения каких-то
более глубоких и всеобъемлющих свойств мироздания.
Слово "материя" делит места с 2172 по 2202 по частоте
употребления в русском языке, наряду со словами "самовар"
и "конференция", "партизан"
и др. Таким образом, по свидетельству языка
понятие "материи" примерно столь же важно для объяснения
мироустройства, как понятия "самовара" или "партизана". Даже если сложить
вместе частоты таких однокоренных слов, как "материя", "материальный",
"материализм", "материалистический", данная металексема
получит ранг примерно 370, где-то среди слов "база", "палец",
"станция", "офицер" - почтенных, но никак не претендующих на
метафизическую важность.
Еще одно важнейшее понятие, положенное в основу многих
философских систем - это "бытие" или "существование". "Быть"
- важное, но не основное слово: в русском языке оно занимает
по частоте 6 место, в английском - четвертое, во французском
- четвертое.
Другие категории, например, "разум" и "познание"
/у рационалистов/, "чувство" и "ощущение"/у сенсуалистов/, "польза"
и "деятельность" /у прагматиков и бихевиористов/, "воля" /у
Шопенгауэра/, "жизнь" /у Ницше/, также отвергается языком,
всей суммой его употребления, в качестве основополагающих. (Металексема
"делать - дело - действовать - деятельность" - 35-ое место,
"жить - жизнь" - 45-ое, "воля" - 65-ое. ).
Более существенны понятия "я" и "ты", выдвинутые М. Бубером, - они принадлежат к самым употребительным в любом
языке, и никакое объяснение мира не может без них обойтись.
Бубер назвал местименную пару "я - ты" "основным словом",
определяющим диалогическое отношение как центральное в
мироздании; но если судить по словарю, отводящему этой
мелаксеме 3-е место в русском и английском языках, он
все-таки ошибся, хотя и ненамного.
Что же есть первоначало мира? - по
мнению языка, которое может мыслителем разъясняться и
обосновываться, но не оспариваться.
"Разум" - а я схожу с ума от любви.
"Дух" - а я копаюсь в песке или трогаю листья деревьев.
"Материя" - а я, кроме как в шелке или ситце, никогда ее не
трогал. "Быть" - а меня еще и нет, я только возможен.
"Знать" - а я и не знаю, что я знаю...
На фоне этих железных клеток - как легко парят, обдавая
невнятным, но чистым птичьим щебетом и ветерком, самые
первые слова из частотного списка: "в", "и", "не", "на",
"я"... Слова, чей смысл ни к чему не привязывает, никуда не
теснит, проходя через мысль как трепет самых первых, самых
робких и чистых прикосновений к действительности.
Вот без каких слов не могут обойтись люди в каждодневном
своем общении, в тысячах мыслей и высказываний о том и
другом - вот без каких начал не мог бы начаться сам мир:
если б не было "в", не было "и", не было самого "не".
Предлоги, союзы, частицы... И во главе их - по благодати,
которой удостоены не все языки - самые служебные из всех:
артикли.
Определенный артикль - наиболее употребительное слово в тех
языках, где он имеется, а на этих языках создана едва ли не
самая богатая и разнообразная словесность в мире: иврит,
греческий, арабский, английский, немецкий, французский,
испанский, итальянский, все скандинавские...
Если когда-нибудь сверхмашина создаст всемирный частотный
словарь, нет сомнения, что первое место в нем займет
определенный артикль.
Каждое 13-14-ое слово в английском тексте - это определенный
артикль THE
Это и
есть искомое слово слов,
выдвинутое самим языком на первое место среди бесчисленных
актов говорения о мире.
Мир должен быть понят прежде всего
через артикль - всесторонне артикулирован. Не онтология и
гносеология - учение о бытии и познании, но "артикулогия",
учение о выделенном, определенном - вот центральный раздел
философии.
Определенный артикль означает любую
вещь как эту, отличную от всех других вещей в мире, и это
свойство
"Этости" является начальным и всеопределяющим, как
доказывает многообразная практика языка.
"Данное мировоззрение можно назвать "the-ism" или "тэизмом",
вкладывая сюда двойной смысл - и тот, что закреплен за
каноническим понятием "theism", "теизм" как верой в
Бога-Личность, и тот, что привносится неканоническим
понятием "the" как определительным принципом мироздания.
В русском языке это определительное, артикулирующее начало,
вследствие отсутствия артиклей, выражено не столь резко, как
в европейских /романских и германских/.
На первое место
выдвигается другое фундаментальное свойство - "вмещенность".
Оно выражено предлогом "в", опережающем все другие слова в
частотном списке /43 000 на миллион словоупотреблений,
каждое 23-е слово в тексте/.
Все, что ни есть, вмещено во
что-то.
Ничто не может быть, не будучи в чем-то.
"В"-структура
определяет пребывание всякой вещи внутри другой: даже самое
малое что-то вмещает, даже самое великое чем-то объемлется.
Дом - в городе, город - в стране, страна - в мире, мир - в
сознании, сознание - в теле, тело - в доме... Все вмещено,
ничто не может выйти из окружения.
Русский язык берет мир в кольцо, представляя его
как систему оболочек, в которой все является облеченным и
облекающим.
"Все во всем" - этот древний закон, выведенный
Анаксагором, в русском языке выступает как синтаксическая
привычка.
Главное - не "это", а "в", через структуру
которого любая вещь предстает окруженной и окружающей,
притом, что эти круги входят друг в друга, наподобие звеньев
одной цепи: окружающее само окружается тем, что оно окружает.
Вселенная существует во времени, а время - во вселенной.
Мы
застаем свое "я" - в мире, а мир - в себе /своем восприятии
и осознании/. Вот и вся проблема "материального" и "идеального",
соотношения приобретенных ощущений и врожденных идей: одно
заключено в другом, как звено в звене.
Русский язык рассеян в отношении определенности вещей и
сосредоточен на их окруженности, пребывания внутри чего-то.
Вещь определяется не сама по себе, в отличие от другой вещи,
но через то большее, внутри чего она пребывает.
Вмещенность
не предполагает разграничения, а напротив, снятие
ограничений, включение их в объемлющее бытие и сознание.
Вещь заведомо дана не сама по себе, в "этости", а внутри
чего-то другого, как его включенное звено, через которое
вытягивается вся цепь.
Таково это мирообразующее в России
свойство свернутости и заключенности.
Вот почему так трудна
и так необходима в России не только теория, но и практика
Всеразличия - действенный тэизм, идущий от веры в
__________________________________
Все эти данные приводятся А. Пушниковым по "Частотному
словарю русского языка", под ред, Л.Н. Засориной, М., 1977.
|
|