|
Определение
словарного запаса |
|
Статистические методы в языкознании
- методы использования счета и измерений для изучения языка
и речи.
Объектом применения
статистических методов обычно является письменный текст (в
первую очередь его лексический состав). |
|
Вокабула
(от лат. vocabulum «слово, имя, название»):
-
основное определяющее
слово (словосочетание) в заголовке словарной статьи,
-
отдельно взятое слово для
заучивания наизусть при первоначальном обучении языкам.
Вокабулярий
(от лат. vocabularium «лексика»):
-
список вокабул в словарях,
-
совокупность слов в
тексте, которые не входят в словарный запас читателя
(являются непонятными),
-
словарный запас человека.
Словарный запас
(лексикон) — набор слов, которыми владеет человек.
Активный словарный
запас — набор
слов, которые человек использует в устной речи и письме.
Пассивный словарный
запас
— набор слов, которые
человек узнаёт при чтении или на слух, но не использует их
сам.
Пополнение словарного запаса —
одна из основных составляющих обучения иностранному языку.
Эффективное пополнение словарного запаса учитывает:
-
наличный словарный запас (лексикон),
-
частотность слов для запоминания
(walk
vs perambulate);
-
простоту слов для запоминания
(process vs
outgrowth);
-
цели пополнения словарного запаса (специфичность
лексики).
Для эффективного изучения
новых слов и поддержания в памяти старых важно уметь
определять словарный запас (лексикон) ученика.
Традиционный
подход в определении словарного запаса заключается в интуитивном определении объема
лексикона учителем на основе общения и тестов. Такой подход,
однако, полностью опирается на опыт и квалификацию
преподавателя и не может быть объективно проконтролирован.
|
WordMash
|
WordMash инструмент
определения словарного запаса
(от компании Skyeng)
WordMash
основан на предположении, что из всех слов
языка можно составить упорядоченный по сложности список:
-
в начале
списка идут «простые слова», например те, что выучивают
дети в самом начале жизни: «мама», «папа», «хороший»,
«плохой» и т.д.
-
конце списка находятся «сложные» слова —
профессиональная лексика, архаизмы, локальные наречия и т.д.
-
в упрощенном случае предполагается, что если человек знает
некоторое слово в этом упорядоченном списке, то он знает и
все предыдущие слова в этом списке; если же человек не знает
некоторое слово, то и последующие слова он тоже не знает.
В идеальном случае для оценки словарного
запаса человека требуется определить положение границы его
знания: номер последнего слова, которое он знает.
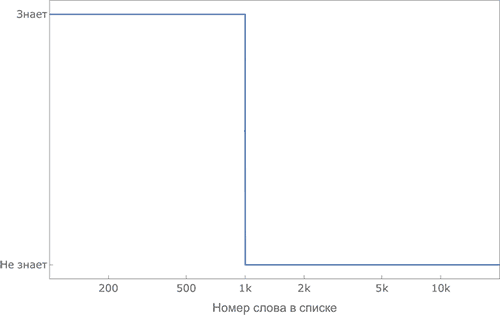
В реальности
изучение
слов происходит не по списку, не по
порядку,
лексикон разных людей отличается.
Чтобы использовать усредненное упорядочивание слов (без
четкой границы), слова в ранжированном по сложности списке
разбиваются на интервалы (например, по 100 слов) и для
каждого интервала определяется процент слов из этого
интервала, который ученик знает. В результате получается
относительно гладкая кривая, с помощью графика которой можно
увидеть, с какой вероятностью ученик знает слово. Роль
аналога границы (характеризующей численным образом словарный
запас ученика) играет медиана функции распределения (такие
номера слов, что количество неизвестных слов до них равно
количеству известных после.
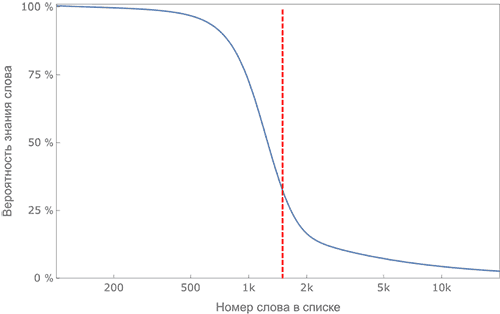
Красная
линия - медиана
распределения (зависимостиь вероятности знания слова от
его номера)
Проблема: подготовить упорядоченный по
сложности список слов... |
Анализ частотности по BNC
|
Эмпирически установлено:
Следствие:
|
Лингвистический корпус:
-
репрезентативная (соответствующая
представляемой функционирования
языка) совокупность текстов,
-
собранных в соответствии с определёнными
принципами (соответствующими задаче),
-
размеченных (снабженных аннотациями),
-
обеспеченных специализированной поисковой
системой.
|
Для
WordMash
был проведен частотный анализ
тех подкорпусов Британского
Национального Корпуса (British National Corpus), в
которых представлены:
-
письменные тексты (книги,
статьи, документы),
-
разговорные (транскрипции
бесед, записей, фильмов)
-
цитаты из докладов,
обращений и выступлений.
Эти три подкорпуса различаясь
объемами, обладают одинаковой важностью для анализа живого
языка, поэтому при подсчете частотности их «вес» в общем
результате был уравнен.
Далее были рассчитаны
частотности и проведена нормализация по подкорпусам
(усреднены три результата).
Фрагмент
полученного списка и график зависимости частотности от
номера слова:
|
Номер слова |
Слово |
Частотность (на 1 000 000
000 слов) |
|
1 |
the |
61 674 367 |
|
2 |
be |
35 206 532 |
|
470 |
leader |
2 420 806 |
|
5
175 |
millennium |
11 433 |
|
49
818 |
negligibly |
67 |
График зависимости
частотности слова от его номера в списке хорошо описывается законом
Ципфа (красная прямая):
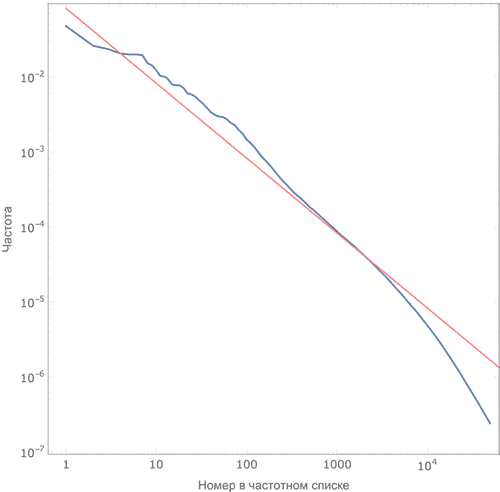 |
Ранжирование списка
|
Соответствие частотности слов в корпусе текстов и
относительной упорядоченностью лексикона справедливо для
группы активных читателей и создателей текстов (грамотных
носителей языка) и проблематично для иноязычных учащихся.
Например, проблемой являются слова схожей формы в английском
и русском языках, позволяющие угадать значение незнакомого
слова , что положительно влияет только на размер пассивного
словаря(если это не «ложный
друг переводчика»).
Для сортировки словаря, основанной на субъективном
восприятии сложности отдельных лексических единиц реальными
людьми из двух предложенных системой
WordMash
слов пользователь выбирает наиболее, на его взгляд, простое.
При этом для упорядочивания списка применяется система рейтингов
Эло (чем выше рейтинг – тем
сложнее его поднимать и легче потерять).
Начальный рейтинг рассчитывался как логарифм частотности:
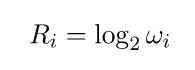
После сравнения i-го слова с j-ым:
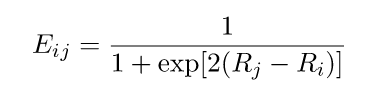
Вычисляется новый рейтинг слова:
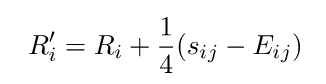
Подобная методика при некотором размере базы пользователей
оказалась устойчива к шуму результатов (достоверность
рейтинга слов, полученного на основе ответов растущего
количества участников программы повышалась).
Была построена метрика качества сортировки: количество
перестановок, которое нужно совершить в списке слов, чтобы
кривая стала монотонной (чем меньше перестановок, тем
лучше).
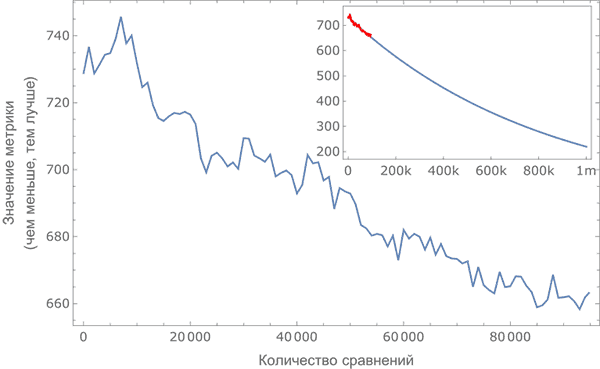
На графике показана зависимость метрики от количества
проведенных сравнений. |
Использование
WordMash
|
Результаты работы инструмента WordMash используются для
подбора учебных материалов на основе определения объема
лексикона ученика:
-
на первом этапе (словарный опрос, логарифмически
равномерно покрывающий весь диапазон ранжированного
списка) определяется приблизительная граница медианным
методом.
-
на втором этапе граница уточняется на основе опроса
вокабул в окрестности приблизительной границы.
График роста объема словарного запаса, служит мотивирующим
фактором и показателем эффективности обучения.
На сонове инструментария определения словарного запаса
ученика созданы сервисы
Прототип инструмента Wordset Generator с результатом
обработки «Автостопом по Галактике» Дугласа Адамса
|
WordSet Generator
|
Для заучивания слов,
имеющих непосредственное отношение к поставленной задаче (встречающиеся именно
в заданном контексте)
Skyeng предлагает использует инструмент
Wordset Generator, создающий
упорядоченный список слов для запоминания из текста или набора текстов, которые
хочет прочитать ученик.
Wordset Generator
создан на основе инструментов ранжирования слов и определения словарного
запаса конкретного ученика.
Алгоритм
Wordset Generator:
-
составляется список всех использованных в тексте слов, с
указанием количества вхождений.
-
отсекаются (отправляются в отдельный список) все слова,
отсутствующие в нашем словаре. Как правило, это выдуманные
автором слова, имена, названия.
-
определяется «тематичность» каждого слова в списке, для
чего сравнивается частота вхождения слова в анализируемом
тексте с частотой вхождения этого слова в корпусе текстов
английского языка (его распространенности). Число означает,
во сколько раз чаще слово присутствует в анализируемом
тексте.
-
проводится полуавтоматическая подстройка списка под
конкретные нужды (с помощью заданных параметров или
перемещения ползунков).
-
задается уровень знания ученика («сложность»). При этом
отсекаются слова, с которыми ученик, скорее всего, уже
знаком.
-
выбираются веса тематичности и локальной частотности.
Тематичность важна в том случае, если мы готовим список
профессиональных терминов для использования по работе. В
случае анализа художественной литературы важнее частотность.
-
вычисляется вероятность того, что
конкретное слово в данном тексте является именем собственным
(в веб-версии такие слова подсвечиваются разной
интенсивности красным цветом). Ползунок «Имена собственные»
позволяет удалять такие слова в соответствии с заданной
вероятностью; в большинстве случаев здесь требуется ручное
вмешательство, особенно если речь идет о художественной
литературе.
Применение
Wordset Generator:
-
Наиболее очевидное применение инструмента Wordset Generator
для учащихся – создание списков слов для заучивания
под конкретные книги, фильмы, события, терминосистемы.
-
Анализ художественной литературы помогает готовить рекомендационные списки для каждого уровня учеников.
Чем меньше «сложных» слов выдает программа – тем доступнее
текст для учащихся, находящихся в середине пути изучения
языка. Для высоких же уровней такие тексты не представляют
трудности и не несут образовательной пользы – им надо
подыскивать более богатые лексически произведения. Например,
в произвольно выбранном детективе Агаты Кристи (After the
Funeral) «сложных» слов менее 300; в «Улиссе»
Джеймса Джойса - больше 2000.
От учителя, использующего
Wordset Generator,
требуется:
-
подготовить корпус текстов
(современных и "живых"), из
которых будут извлекаться слова.
-
настроить (ручным
перетаскиванием ползунков) правильные параметры
сложности, тематичности и проч.
-
обработка полученного набора
слов (выяснение точного значения слова в данном
контексте и др.)
-
подбор ко всем словам
смысловых иллюстраций...
Прототип
Wordset Generator: http://tools.skyeng.ru/sandbox/wordset-generator/
(ограничение на размер
текста — до 80 000 знаков, включая пробелы и переносы
строк).
Это
внутренний инструмент
Skyeng, не предназначенный для широкой
публики (потому и интерфейс его аскетичен).
По умолчанию
предложен результат парсинга первой главы “Автостопом по Галактике” Адамса.
Полученные
слова можно добавить в приложение вручную с помощью встроенного словаря.
Можно создать собственный список слов
(экспортировать
его в CSV).
Приложение Aword
(загрузить приложение для Android и iOS можно бесплатно, но работает Aword по
принципу подписки: первые три дня – тестовый режим и ... платить)
После
пополнения словарного запаса можно начать общаться с учителем по Skype с
помощью
сервиса.
|
kmp |