ПАРСИНГ
Parsing
(синтаксический анализ, разбор, парсинг):
процесс сопоставления линейной
последовательности лексем (слов, токенов) естественного или
формального языка с его формальной грамматикой.
автоматический
разбор текста (предложения)
на языке программирования высокого уровня во время его
компиляции,
выявление структуры предложения
формального языка (formal language )
автоматический синтаксический анализ текста на естественном
языке.
автоматический анализ сайтов по заданным параметрам на основе
системы регулярных выражений.
При парсинге входной текст
преобразуется в структуру данных, обычно древовидную
(синтаксическое дерево),
которая отображает подразумеваемую иерархию элементов этого текста и
пригодна для дальнейшей обработки.
Парсинг (синтаксический анализ) в
сложных системах автоматической обработки текста связан с
лексическим и семантическим анализом. Например:
технология ABBYY
Лексический
Лексический анализ
Лексический анализатор
Токены
Объекты и области применения парсинга
Объектами парсинга (автоматического
синтаксического анализа) может быть всё имеющее «синтаксис»:
Области применения
парсинга:
Языки программирования — разбор
исходного кода языков программирования, в процессе трансляции (компиляции
или интерпретации);
Структурированные данные — данные,
языки их описания, оформления и т. д. Например, XML, HTML, CSS,
ini-файлы, специализированные конфигурационные файлы и т. п.;
Построение индекса в поисковой
системе;
SQL-запросы (DSL-язык);
Математические выражения;
Регулярные выражения (которые, в
свою очередь, могут использоваться для автоматизации
лексического анализа);
Формальные грамматики;
Лингвистика — человеческие языки.
Например, машинный перевод и другие генераторы текстов.
Parser
Parser
(синтаксический анализатор, па́рсер) — это программа или часть
программы, выполняющая синтаксический анализ.
Существует
множество различных парсеров:
для разных
объектов
для разных
целей
для разных
языков и т.д.
Существует
особый класс программного обеспечения предназначенного для
автоматического создания парсеров - генераторы парсеров.
Например:
ANTLR
— генератор парсеров
gppg
— генератор парсеров для языка C#
JavaCC
— генератор парсеров для языка Java
PEG.js
— генератор парсеров для Javascript
Jison
— генератор парсеров для Javascript
Xerces
— генератор XML-парсеров
AGFL
— генератор парсеров естественного языка
Алгоритмы парсинга
Нисходящий парсер (top-down parser)
— продукции грамматики раскрываются, начиная со стартового символа,
до получения требуемой последовательности токенов:
Метод рекурсивного спуска
LL-анализатор
Для каждого нетерминального символа
K
строится функция, которая для любого входного слова
x:
находит
наибольшее начало
z
слова
x, способное быть началом выводимого
из
K
слова
определяет,
является ли начало z выводимым из
K
Пример
нисходящего парсера:
LL parser
(синтаксический LL-анализатор) —
нисходящий синтаксический анализатор для подмножества
контекстно-свободных грамматик. Он анализирует входной поток
слева направо, и строит левый вывод грамматики. Класс грамматик,
для которых можно построить LL-анализатор, известен как
LL-грамматики.
Восходящий
парсер (bottom-up parser) —
продукции восстанавливаются из правых частей, начиная с токенов и
кончая стартовым символом:
LR-анализатор
GLR-парсер
Восходящие парсеры
LR-parser
LR(k)-парсер
(Left-to-right
Rightmost derivation parser)
—
синтаксический анализатор для исходных кодов программ
(написанных на многих языках программирования), который
читает входной поток слева (Left) направо и производит наиболее
правую (Right) продукцию контекстно-свободной грамматики
(см. Два оператора).
k
- количество непрочитанных символов предпросмотра во входном потоке, на основании которых принимаются
решения при анализе. Обычно k равно 1 и часто опускается.
Синтаксис многих
языков программирования может быть определён грамматикой, которая
является LR(1). Если
k равно 1, указание на него опускается.
LR-парсер основан на алгоритме,
приводимом в действие таблицей анализа, структурой данных, которая
содержит синтаксис анализируемого языка.
LR-парсеры сложно создавать вручную и
обычно они создаются:
генератором синтаксических анализаторов
(из контекстно-свободной грамматики программой)
компилятором компиляторов.
В зависимости от того, как была создана таблица анализа, эти
анализаторы могут быть названы:
простыми LR-парсерами (SLR),
LR-парсерами с предпросмотром (LALR)
каноническими LR-парсерами.
LALR-парсер имеют большую распознавательную способность, чем
SLR-парсеры, однако требуют больше памяти для хранения большей
таблицы анализа;
Канонические
LR-парсеры — большую распознавательную способность, чем LALR-парсеры,
однако также требуют большей памяти.
Детерминированный контекстно-свободный язык —
это язык, для которого существует какая-либо LR(k) грамматика.
Контекстно-свободная грамматика классифицируется как LR(k), если
существует LR(k)-анализатор для неё, как определено генератором
анализаторов.
Каждая
LR(k) грамматика
может быть автоматически преобразована в грамматику LR(1) для того
же языка
LR(0) грамматки
для некоторых языков может не существовать. LR(0)-языки являются
собственным подмножеством детерминированных.
Два
оператора парсинга
Выделение подстроки слева.
Оператор left
Формат вызова
^left[строка;длина_подстроки]
Аргументы
строка —
строка, левую часть которой нужно получить.
длина_подстроки — количество символов в выделяемой левой части.
Описание
Оператор
возвращает указанное количество первых символов строки. Если
длина строки меньше, возвращается вся исходная строка.
Пример:
Вызов
^left[И
он к устам моим приник и вырвал грешный мой язык]
вернет
И он к
устам моим приник и вырвал
Выделение
подстроки справа. Оператор right
Формат вызова
^right[строка;длина_подстроки]
Аргументы
строка —
строка, правую часть которой нужно получить.
длина_подстроки — количество символов в выделяемой правой части.
Описание
Оператор
возвращает указанное количество последних символов строки. Если
длина строки меньше, возвращается вся исходная строка.
Пример
Вызов
^right[перестройка;7]
вернет
стройка.
G
GLR парсер
(параллельный
парсер)
впервые описан
Масару Томита
(Masaru Tomita) в 1984 году с
целью добиться быстрого и эффективного
распознавания текстов, написанных на
естественном языке.
GLR алгоритм
может (в отличие от
LR-парсера)
разрешать недетерминированности и
неоднозначности естественных языков.
GLR-алгоритм
аналогичен алгоритму
LR,
но
обрабатывает
все возможные трактовки входной последовательности, используя поиск
в ширину:
Генераторы
GLR парсеров преобразуют исходную грамматику в таблицы парсера,
точно так же, как и генераторы LR парсеров.
Если
таблицы LR парсера допускают только один переход состояния (определенное
исходным состоянием парсера и входным терминальным символом),
таблицы GLR парсера допускают множество результирующих состояний.
В результате
GLR алгоритм допускает конфликты сдвиг/свертка и свертка/свертка.
Когда
возникает конфликт, стек парсера (магазинная память)
разветвляется на два или больше параллельных стека, верхнее
состояния которых соответствуют каждому возможному переходу.
В дальнейшем
следующий входной символ используется, чтобы определить
следующие переходы на верхних состояниях каждой ветви стека.
Если же для
какого-либо верхнего состояния и входного символа не существует
ни одного перехода (в таблице парсера), то эта ветвь стека
считается ошибочной и отбрасывается.
По сравнению с
другими алгоритмами, способными обработать весь класс
контекстно-свободных грамматик (алгоритм Эрли,
алгоритм
Кока — Янгера — Касами), алгоритм GLR более производительный.
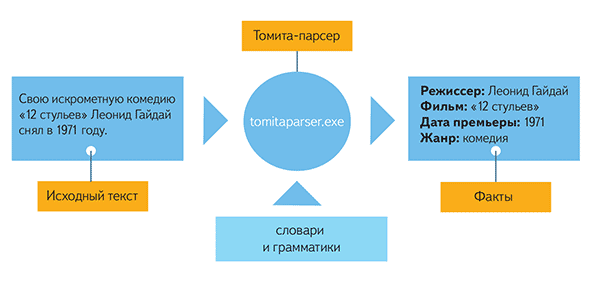
Tomita-parser
Томита-парсер
создан на основе
GLR-парсера специально для
упрощение работы с алгоритмом.
Томита-парсер имеет:
несложный синтаксис для
создания словарей и грамматик,
оптимизацию алгоритмов обработки морфологии русского и
украинского языков.
В минимальной
конфигурации парсеру на входе отдается:
анализируемый
текст,
словарь
грамматика.
Объем словаря и сложность грамматики
зависят от целей анализа.
Грамматики Томита-парсера
Файл грамматики состоит из шаблонов, написанных на внутреннем
языке/формализме Томита-парсера.
Эти шаблоны описывают в обобщенном виде
цепочки слов, которые могут встретиться в тексте.
Грамматики
определяют, как именно нужно представлять извлеченные факты в итоговом
выводе.
Пример простой грамматики:
#encoding "utf-8"
Словари Томита-парсера
В словарях
Томита-парсера
содержатся ключевые слова, которые используются в процессе
анализа грамматиками.
Каждая статья этого словаря задает множество слов и
словосочетаний, объединенных общим свойством. Например, «все школы Бреста».
Затем в грамматике можно использовать свойство «является школой Бреста».
Пример простого словаря: //для каждой статьи
обязательно должен быть указан тип (в данном случае genre),
название и ключ - содержание статьи
Может каждый!
Каждый
может подготовить
Томита-парсер для своих
целей:
при понимании устройства
русского языка
(особенно его синтаксиса),
знании основ регулярных выражений
настойчивости.
kmp |