|
Machine Learning
|
Машинное обучение (Machine Learning)
— раздел искусственного интеллекта, моделирующих алгоритмы обучения
(оптимизации) искусственных нейронных сетей на выявление
закономерностей в данных.
|
Нейронные сети учатся совсем не так как люди.
Для нейронных
сетей "обучение = оптимизация"
Оптимизация (обучение) нейронной сети — градиентный спуск по
функции потерь, где переменными аргументами
являются веса слоёв.
|
Машинное обучение
образовалось
в результате разделения науки о нейросетях на:
Обучение искусственных нейронных сетей
- процесс настройки (для
эффективного решения поставленной задачи):
Хорошая простая сетевая книга (на
английском):
Neural Networks and Deep Learning.
Хорошая сложная книга:
В.В.Вьюгин
МАТЕМАТИЧЕСКИЕ ОСНОВЫ ТЕОРИИ МАШИННОГО ОБУЧЕНИЯ И ПРОГНОЗИРОВАНИЯ
|
ML и Big data
Невозможно описать все логические шаги, необходимые, чтобы
ходить или распознавать кошек!
В машинном обучении, вместо
написания правил, статистическому алгоритму дают (огромное) множество
примеров, и этот алгоритм (сам) генерирует модель, которая
различает категории.
Предлагается
(нейронной сети) 1
000 0000 картинок,
помеченных как «кошка», и 100 000 картинок, помеченные «нет
кошки». Обученная на этих данных нейросеть "распознает" (выделяет) картинки с кошкой на новых
(не помеченных) изображениях.
Машинное обучение заменяет задаваемые вручную логические этапы
автоматически моделируемыми паттернами (шаблонами) в данных и
эффективно работает
в широком классе задач (каждый раз - только
для конкретных узких задач из этого широкого класса).
Машинное обучение — технология общего назначения, но приложения на ее основе, не универсальны
- умеют делать что-то одно.
Стиральная машина умеет стирать одежду, а не мыть посуду или
готовить еду.
Система машинного перевода текста не распознает кошек.
Больше данных
Ú более точная модель
Ú более качественный продукт
Ú
больше пользователей
Ú больше данных...
Все
преимущества у больших корпораций и государств с «разрешительным» отношением к
централизованному использованию данных.
Крупные корпорации могут предоставлять открытый (частично) доступ к
части своих данных и ...
скупают коллективы исследователей, занимающихся глубинным обучением
целыми лабораториями.
Данные для обучения (как и сами статистические алгоритмы обучения) относятся к конкретной узкой
проблеме (телеметрические данные с газовых турбин, поисковых
запросы, параллельные тексты, фотоизображения людей или ...., данные о мошенничестве с
кредитными картами).
Предпринимаются попытки сделать так, чтобы алгоритмы машинного
обучения могли переключаться с одного набора данных на другой.
Обученные нейронные сети успешно работают на относительно небольших наборах
данных.
|
Столица европейского AI
)
03.09.201 7
«Столица европейского AI»: полная карта ИИ-проектов Беларуси
07.12.2018
В Стэнфорде конференция "AI и будущее
общества".
Основные тезисы:
-
AI – новое электричество:
за десятилетия полностью трансформирует экономику и общество.
-
Данные – это новая нефть, КНР – новый ОПЕК. Накопление большого
объема данных критично для развития AI.
-
Число рабочих мест не уменьшится – но работа будет совсем другой. Креатив, эмпатия, стратегия – главное
в человеке
-
Главный вызов AI: придется постоянно быстро переучиваться.
-
Европа
"пролетает" и ей нужно срочно определяться с ролью в грядущем мире AI.
15.01.2019
IDC - объем глобального
рынка ИИ
в 2018 - $24 млрд, в 2022-м - $77,6
млрд.
Frost & Sullivan: Объем рынка
технологий ИИ
в 2018 - $17,8 млрд. Прогноз ан 2022 - $52,5 млрд
Tractica: объем рынка
ПО ИИ
в 2018 - $8,1 млрд. К 2025 году - $105,8
млрд.
http://www.tadviser.ru/a/425392
5 самых популярных областей использования ПО ИИ:
-
видеонаблюдение,
-
системы мониторинга и управления ИТ-сетями и операциями,
-
клиентское обслуживание и маркетинг,
распознавание голоса и речи,
автогенерация текста и поддержания
диалога
обнаружение и распознавание объектов техникой...
BCC Research: объем рынка технологий распознавания речи
в 2016 - $104 млрд, в 2021 (прогноз) - $184,9 млрд.
28.05.2019
Нейронную сеть от белорусского
стартап
Oyper Inc
признали лучшей в Европе на конкурсе R&B Next Awards
Disruptive Tech в Барселоне. Сверточная нейронная сеть определяет и классифицирует одежду на фотографиях и видео.
Это облачное решение, которое можно
встраивать в сайты онлайн-магазинов и видео провайдеров.
Подробнее:
https://dev.by/news/oyper
|
Математическая интерпретация обучения
нейронной сети
|
На каждой итерации алгоритма обратного
распространения весовые коэффициенты нейронной сети модифицируются так,
чтобы улучшить решение одного примера.
Таким образом, в процессе
обучения циклически решаются однокритериальные задачи оптимизации.
Обучение нейронной сети характеризуется
четырьмя ограничениями (выделяющими
ML
из общих задач оптимизации):
-
огромное число параметров,
-
необходимость высокого параллелизма
при обучении,
-
многокритериальность решаемых задач,
-
необходимость найти достаточно широкую
область, в которой значения всех минимизируемых функций близки к
минимальным.
В остальном проблема обучения,
как правило, формулируется как задача минимизации оценки.
На самом деле нам
неизвестны (и никогда не будут известны) все возможные задачи для
нейронных сетей.
|
Обучение по прецедентам
|
Обычно обучение
нейронной сети осуществляется на некоторой выборке (обучающей выборке,
совокупности прецедентов).
По мере процесса обучения,
который происходит по некоторому алгоритму, сеть должна все лучше и лучше
(правильнее) реагировать на входные сигналы.
Общая постановка задачи обучения по прецедентам:
-
Имеется
множество объектов (ситуаций) и множество
возможных
ответов (откликов, реакций).
-
Существует некоторая зависимость между ответами и
объектами, но она неизвестна.
-
Известна
конечная совокупность прецедентов — пар «объект, ответ», называемая
обучающей выборкой.
-
На
основе этих данных требуется восстановить зависимость
и построить
алгоритм, способный для любого объекта выдать приемлемо точный ответ.
Данная постановка является обобщением классических задач аппроксимации
функций, где объектами являются
действительные числа или векторы.
В реальных прикладных задачах входные
данные об объектах могут быть неполными, неточными, нечисловыми,
разнородными.
Эти особенности приводят к большому разнообразию методов
машинного обучения.
|
Алгоритмы
обучения нейронных сетей
|
Базовые виды нейросетей
(перцептрон и многослойный перцептрон) могут
обучаться:
с
учителем
(известны правильные
ответы к каждому входному примеру, а веса подстраиваются так, чтобы
минимизировать ошибку),
без
учителя
(позволяет распределить
образцы по категориям за счет раскрытия внутренней структуры и
природы данных),
с
подкреплением
(комбинируются два
вышеизложенных подхода).
Некоторые нейросети
и большинство статистических методов можно отнести только к одному из
способов обучения. Поэтому правильно классифицировать алгоритмы обучения
нейронных сетей.
Обучение с
учителем
— для каждого прецедента задаётся пара «ситуация, требуемое решение»:
Обучение без учителя
— для каждого прецедента задаётся только
«ситуация», требуется сгруппировать объекты в кластеры, используя данные
о попарном сходстве объектов, и/или понизить размерность данных:
Обучение с
подкреплением
— для каждого прецедента имеется пара «ситуация, принятое решение»:
Активное
обучение
— отличается тем, что обучаемый алгоритм имеет возможность
самостоятельно назначать следующую исследуемую ситуацию, на которой
станет известен верный ответ:
-
Обучение с частичным привлечением учителя (semi-supervised learning) —
для части прецедентов задается пара «ситуация, требуемое решение», а для
части — только «ситуация»
-
Трансдуктивное обучение (transduction) — обучение с частичным
привлечением учителя, когда прогноз предполагается делать только для
прецедентов из тестовой выборки
-
Многозадачное обучение (multi-task learning) — одновременное обучение
группе взаимосвязанных задач, для каждой из которых задаются свои пары
«ситуация, требуемое решение»
-
Многовариантное обучение (multiple-instance learning) — обучение, когда
прецеденты могут быть объединены в группы, в каждой из которых для всех
прецедентов имеется «ситуация», но только для одного из них (причем,
неизвестно какого) имеется пара «ситуация, требуемое решение»
|
Метод обратного
распространения ошибки
|
Существует большое число алгоритмов обучения, ориентированных на решение разных
задач.
Самый успешный:
Метод обратного распространения ошибки
(backpropagation) — метод обучения, который используется с
целью минимизации ошибки работы и получения желаемого выхода.
Основная идея метода:
В итоге каждый нейрон способен
определить вклад каждого своего веса в суммарную ошибку сети.
Простейшее правило
обучения соответствует методу наискорейшего спуска (изменения синаптических весов пропорционально их вкладу в общую ошибку).
См. подробнее:
http://ru.wikipedia.org/wiki/Метод_обратного_распространения_ошибки
|
Deep learning
|
Глубокое обучение
(Deep learning) - это раздел
ИИ, основанный на двух идеях:
-
обучение с использованием большого количества уровней представления
информации для моделирования комплексных отношений в данных,
-
обучение на немаркированных данных ("без учителя") или на комбинации
немаркированных и маркированных данных ("с частичным привлечением учителя").
При
обучении множеству уровней представления информации высокоуровневые признаки и
концепты определяются с помощью низкоуровневых.
Такая иерархия признаков
называется
Deep Architecture
(глубокой архитектурой).
Глубокие архитектуры произвели революцию в области
Machine
Learning,
значительно превзойдя другие модели в задачах распознавания изображений, аудио,
видео и др.
Попытки обучения глубоких архитектур (в основном, нейронных сетей) до 2006 года
проваливались (за исключением особого случая свёрточных нейронных сетей).
Успешный
подход Хинтона
использует
Restricted Boltzmann
Machine
(Ограниченную
Машину Больцмана,
RBM) для моделирования каждого нового слоя высокоуровневых признаков:
-
каждый новый слой гарантирует увеличение нижней границы логарифмической функции
правдоподобия, таким образом улучшая модель при надлежащем обучении.
-
когда
достаточное количество слоёв обучено, глубокая архитектура может быть
использована как в качестве дискриминативной модели для распознавания подаваемых
на вход данных (с помощью прохода "снизу вверх"), так и в качестве генеративной
модели для производства новых образцов данных (с помощью прохода "сверху вниз").
|
Задачи
для машинного обучения
|
Цель
ML
- автоматизация
решения сложных задач в самых разных областях
человеческой деятельности:
-
классификации (как правило, выполняется с помощью обучения с учителем на
этапе собственно обучения).
-
Кластеризации
(как правило, выполняется с помощью обучения без учителя)
-
Регрессии
(как правило, выполняется с помощью обучения с учителем на
этапе тестирования, является частным случаем задач прогнозирования).
-
Понижения
размерности данных и их визуализация (выполняется с помощью
обучения без учителя)
-
Восстановления плотности распределения вероятности по набору данных
-
Выявления новизны
-
Построениея
ранговых зависимостей
Типы входных данных при обучении
-
Признаковое описание объектов — наиболее распространённый случай.
-
Описание взаимоотношений между объектами, чаще всего отношения попарного
сходства, выражаемые при помощи матрицы расстояний, ядер либо графа
данных
-
Временной ряд или сигнал.
-
Изображение или видеоряд.
-
Типы функционалов качества
|
Приложения
машинного обучения
|
Целью является частичная или полная автоматизация
решения сложных задач в самых разных областях
человеческой деятельности.
Машинное обучение имеет широкий спектр приложений:
-
Распознавание
текста (речи, рукописного ввода)
-
Генерация текста (речи)
-
Машинный перевод
-
Распознавание жестов
-
Категоризация документов
-
Ранжирование в информационном поиске
-
Распознавание образов
-
Диагностика
(техническая, медицинская...)
-
Биоинформатика
-
Обнаружение спама
-
Биржевой технический анализ
и др...
Сфера
применений машинного обучения постоянно расширяется по мере накопления огромных объёмов данных в науке,
производстве, финансах, транспорте, здравоохранении.
Возникающие при этом
задачи прогнозирования, управления и принятия решений часто сводятся к
обучению по прецедентам.
Раньше, когда таких данных не было, эти задачи
либо вообще не ставились, либо эффективно решались другими методами.
|
Обобщающая способность и переобучение
|
Обобщающая способность (generalization
ability, generalization performance) - характеристика алгоритма
обучения, обеспечивающая
вероятность ошибки на тестовой
выборке на уровне ошибки на обучающей
выборке.
Обобщающая
способность тесно связана с понятиями переобучения и недообучения.
Недообучение — нежелательное явление,
возникающее при решении задач обучения
по прецедентам,
когда алгоритм
обучения не
обеспечивает достаточно малой величины средней ошибки на обучающей
выборке.
Недообучение возникает при использовании недостаточно сложных моделей.
Переобучение (overtraining,
overfitting) — нежелательное явление, возникающее при решении задач обучения
по прецедентам,
когда вероятность ошибки обученного алгоритма на объектах тестовой
выборки оказывается
существенно выше, чем средняя ошибка на обучающей
выборке.
Переобучение возникает при использовании избыточно сложных моделей.
Эмпирический риск - средняя
ошибка алгоритма на обучающей выборке.
Метод минимизации
эмпирического риска (empirical
risk minimization, ERM)
состоит в том,
чтобы в рамках заданной модели выбрать
алгоритм, имеющий минимальное значение средней ошибки на заданной
обучающей выборке.
Переобучение
появляется именно вследствие минимизации эмпирического риска:
-
пусть задано
конечное множество из D алгоритмов, которые допускают ошибки
независимо и с одинаковой вероятностью.
-
число ошибок
любого из этих алгоритмов на заданной обучающей выборке подчиняется
одному и тому же биномиальному
распределению.
-
минимум
эмпирического риска — это случайная величина, равная минимуму из D независимых
одинаково распределённых биномиальных случайных величин.
Её ожидаемое значение уменьшается с ростом D.
-
соотвественно,
с ростом D увеличивается переобученность— разность вероятности
ошибки и частоты ошибок на обучении.
В реальной ситуации алгоритмы имеют различные
вероятности ошибок, не являются независимыми, а множество алгоритмов, из
которого выбирается лучший, может быть бесконечным. По этим причинам
вывод количественных оценок переобученности является сложной задачей,
которой занимается теория
вычислительного обучения.
Всегда существует оптимальное значение сложности модели, при котором
переобучение минимально.
|
AutoML
|
Компания Google объявила об
очередном большом шаге в разработке искусственного интеллекта, рассказав
про
AutoML - новом подходе к машинному обучению, с помощью которого нейронные сети можно
будет использовать для создания еще более эффективных нейронных сетей.
Сундар Пичаи
(ген. директор Google)
показал пример работы AutoML на конференции Google
I/O 2017.
-
Сегодня проектирование нейронных сетей чрезвычайно трудоемко и требует
опыта, что недоступно для небольших сообществ ученых и инженеров. Вот почему
мы создали подход под названием AutoML, благодаря которому нейронные сети
могут создавать нейронные сети. Мы надеемся, что AutoML будет обладать
способностями нескольких докторов наук и позволит через три-пять лет сотням
тысяч разработчиков создавать новые нейронные сети для своих конкретных
потребностей.
-
Работает это так: мы берем набор кандидатов в нейронные сети, — назовем их
нейронными сетями-малышами, — и многократно прогоняем через них на предмет
поиска ошибок уже готовую нейронную сеть до тех пор, пока не получим еще
более эффективную нейронную сеть.
См. в официальном блоге.
С помощью технологии AutoML ИИ-платформы станут быстрее обучаться и будут
гораздо умнее.
Согласно Google, даже сейчас уровень AutoML уже таков, что она может быть
эффективнее экспертов-людей в вопросе поиска лучших подходов для решения
конкретных проблем. В перспективе это позволит существенно упростить процесс
создания новых ИИ-систем, так как, по сути, их будут создавать себе же
подобные.
Предполагается,
что эта технология приведет к появлению новых
нейронных сетей и открытию возможностей, когда даже не эксперты смогут
создавать свои личные нейронные сети для своих определенных нужд. Это, в
свою очередь, увеличит способность технологий машинного обучения оказывать
влияние на нас всех.
См.
подробнее. |
Сетевые ресурсы
От автоматической обработки текста к машинному пониманию
|
Из
лекции
Владимира Селегея
- директора по
лингвистическим исследованиям компании ABBYY, заведующего кафедрами
компьютерной лингвистики РГГУ и МФТИ, председателя оргкомитета ведущей
российской конференции по компьютерной лингвистике «Диалог»
(прочитана 9 октября 2012 г. в Лектории
Политехнического музея).
-
Важно, что статистическая революция открыла путь к реальному многоязычию.
Но самое главное, что методы статистической оценки и машинного обучения
стали использоваться и в подходах, основанных на лингвистических
моделях. Появились гибридные системы. Можно брать статистику и добавлять в нее лингвистику.
У нас другой подход: мы берем лингвистические модели и обучаем их на
корпусах.
-
На наш взгляд, возникает новая парадигма компьютерной лингвистики.
|
Дерев ья
принятия решений
|
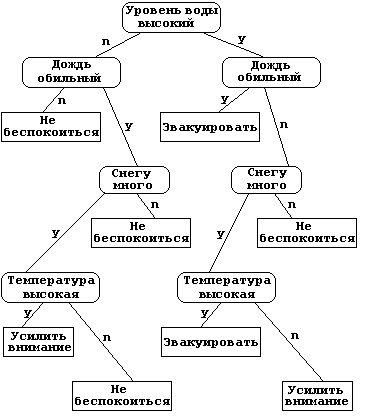
Дерево принятия
решений (Decision
tree
) — метод анализа
данных для прогнозных моделей.
Цель: создать
модель, которая предсказывает значение целевой переменной на основе
нескольких переменных на входе.
Структура дерева
представляет собой: «листья» и «ветки».
На ветках дерева
решения записаны атрибуты, от которых зависит целевая функция, в листьях
записаны значения целевой функции, а в остальных узлах — атрибуты, по
которым различаются случаи.
Чтобы
классифицировать новый случай, надо спуститься по дереву до листа и
выдать соответствующее значение.
Деревья решений
широко используются в интеллектуальном анализе данных.
Пример
(для
поискового ранжирования задачи - разбиения текста на предложения и
построения
сниппетов).
Сниппет
- небольшой отрывок текста из найденной поисковой машиной страницы
сайта, использующихся в качестве описания ссылки в результатах поиска.
В
некотором тексте есть потенциальный делитель - точка.
В
реальном Интернете (далеком от
литературного языка), очень много текстов, когда точка не
является знаком пунктуации "точка".
Поэтому нужно проанализировать контекст, который
находится около этой точки.
Пишется
анализатор, который начинает проверять простые правила:
-
есть ли пробел справа,
что говорит о том, что
это, скорее всего конец предложения.
-
есть ли большая
буква справа...
-
...................
-
таких правил на текущий момент около 40.
Необходимо скомбинировать
эти правила
между собой и произвести финальную оценку.
Здесь также применяется
машинное обучение
на деревьях
принятия решений.
Дерево принятия решений– бинарное дерево
с условием, которое проверяет, сработал или не сработал признак.
Признаки кодируются при помощи нуля и единицы.
Если признак не
сработал – нужно идти налево, если сработал – направо. После перехода может быть проверка нового
условия.
Получаются такие достаточно длинные цепочки условий,
оканчивающиеся листом дерева, в котором записывается вероятность
того, что это конец предложения.
Проблема
переобучения (с
ростом дерева рост качества замедляется и останавливается на недостаточном для решения задачи уровне)
преодолевается с помощью
бустинга.
Бустинг
(boosting — улучшение) — процедура последовательного построения
композиции алгоритмов машинного обучения, когда каждый следующий
алгоритм стремится компенсировать недостатки композиции всех предыдущих
алгоритмов. В течение последних 10 лет бустинг остаётся одним из
наиболее популярных методов машинного обучения.
Применение бустинга:
-
строится первое дерево, и для всех
элементов обучающего множества вычисляется ошибка.
-
строится
следующее дерево, только его задача уже не предсказывать концы
предложений, а указывать на ошибку предыдущего дерева.
-
по
цепочке, строится несколько десятков, а иногда и сотен деревьев.
-
получается достаточно гладкое решение.
|
Модель простейшей сети с одним слоем
|
Простейшая сеть с одним
скрытым слоем может быть представлена следующим образом:

На шаге 2 входной вектор значений X (набор чисел)
умножается на вектор весов W1, затем складывается с вектором смещений
B1, полученные значения весов передаются
сигма функции
возбуждения. Далее вычисленный вектор S1 умножается на веса скрытого
слоя W2 складывается с смещением B2, и вычисляется функция softmax которая
является ответом сети.
Этот же алгоритм в графическом виде можно (вычисление
идет снизу-вверх):
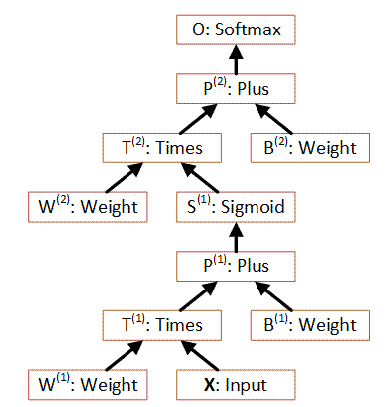
|
Sharky Neural Network
|
Sharky Neural Network -
приложение для демонстрации возможность
обучаемости нейросети.
SNN
позволяет
выбрать
общей вид
и модель работы
нейронной сети, другие параметры, после чего задать образ
распознания и понаблюдать за работой программы нейросети.
SNN
использует контролируемое машинное обучение с помощью алгоритма
обратного распространения ошибки.
Это
бесплатное программное обеспечение доступно на странице:
http://www.SharkTime.com
Нейронная сеть
SNN
относит
2D-точки
(вектора описывается двумя реальными
значениями: x и y) в два разных класса,
проводя визуализацию
данных пунктов (желтый и синий) классификации.
Нейроны
SNN
используют биполярный сигмоид функции
активации (f(x)=2/(1+e-βx)-1).
Пользователь может
добавлять, удалять, загружать или сохранять точки
обоих цветов (желтого и синего), очищать поле от точек.
Чтобы создать
логотип
"X"- нужно:
-
Ctrl + Левая Кнопка
Мыши
-
ввод множества точек
(режим спрея, распылителя)
-
[ -
уменьшение диапазона спрея
-
]
- увеличение диапазона спрея
-
заполнить синими
точками фон
в
режиме "спрей".
-
выбрать
подходящую структуру сети (закладка
Network
и раскрывающийся список Network
Structure),
-
настроить параметры обучения
(закладка
Learn)
-
нажать кнопку "Learn button".
Другие полезные сочетания клавиш:
-
F5 - Сброс сети.
-
F6 - Начать учить.
-
Esc - Перестать учиться.
|
PPAML
|
PPAML (Probabilistic Programming for Advanced Machine
Learning) -
новая (с
2013 г.) исследовательская
программа DARPA по вероятностному
программированию для машинного обучения.
DARPA
(Defense Advanced Research Projects Agency) — агентство
передовых оборонных исследовательских проектов Минобороны США.
К этлин
Фишер
(руководитель PPAML):
-
PPAML призвана сделать для
машинного обучения то, что появление языков высокого уровня
50 лет назад сделало для программирования в целом.
-
Не существует общепринятых
универсальных инструментов для создания интеллектуальных
систем. Из-за этого приходится постоянно изобретать
велосипеды (раз за разом реализовывать похожие алгоритмы, строить с нуля архитектуру).
-
Совокупность общих подходов и парадигм, используемых в машинном
обучении, получила название "вероятностное
программирование".
-
Инструменты, библиотеки и языки пока не
покидают стен университетов DARPA
намерено изменить эту ситуацию.
-
Среди целей программы — радикальное уменьшение трудоёмкости
создания систем машинного обучения, снижение порога
вхождения в программирование интеллектуальных приложений,
усовершенствование базовых алгоритмов машинного обучения,
максимальное использование современных аппаратных технологий
— многоядерных процессоров и GPU, облачных вычислений,
создание и стандартизация API для связи элементов
инфраструктуры машинного обучения в единую систему.
Здесь PDF с
кратким описанием программы.
Вероятностное программирование – ключ
к искусственному интеллекту?
http://habrahabr.ru/post/242993/
Классы
вероятностных языков программирования:
-
языки, допускающие задание генеративных моделей только в форме Байесовских
сетей (или других графических вероятностных моделей). Не открывая
возможности решения принципиально новых решений задач, является
высокоэффективным инструментом использования графических моделей.
Пример: язык
Infer.NET
(от Microsoft).
Большинство задач машинного обучения могут быть сформулированы в Байесовской
постановке
см.
байесовское программирование
-
Тьюринг-полные языки (позволяют выйти за рамки того класса задач, которые
существующие методы машинного обучения уже умеют решать). Проблема
эффективности вывода в таких языках, приводит к плохой масштабируемости на
задачи реального мира. Перспективны в исследованиях, связанных с когнитивным
моделированием и общим искусственным интеллектом.
Пример: язык
Church
(Чёрч, расширение диалекта Scheme для языка Лисп) с web-реализацией (web-church)
позволяющей экспериментировать без установки дополнительного программного
обеспечения.
|
Вероятностное программирование
|
Вероятностное программирование
- способ представления порождающих
вероятностных моделей и проведения статистического
вывода в них с
учетом данных с помощью обобщенных алгоритмов.
В
«обычном» программировании основой является алгоритм, обычно
детерминированный, который позволяет нам из входных данных
получить выхоные по четко установленным правилам.
Однако
часто мы зная только результат, заинтересованы в том, чтобы
узнать приведшие к нему неизвестные (скрытые) значения.
Для этого (с
помощью теории математического моделирования) создается
вероятностная модель, часть параметров которой не определены
точно.
В
машинном обучении (для решения задач вероятностного
программирования) используются
порождающие вероятностные модели, где модель
описывается как алгоритм, но вместо точных однозначных
значений скрытых параметров и некоторых входных параметров
мы используем вероятностные распределениях на них.
|
"обычное"
программирование |
вероятностное
программирование |
|
 |
 |
К лассы
вероятностных языков программирования:
-
языки, допускающие задание генеративных моделей только в форме Байесовских
сетей (или других графических вероятностных моделей). Не открывая
возможности решения принципиально новых решений задач, является
высокоэффективным инструментом использования графических моделей.
Пример: язык
Infer.NET
(от Microsoft).
Большинство задач машинного обучения могут быть сформулированы в Байесовской
постановке
см.
байесовское программирование
-
Тьюринг-полные языки (позволяют выйти за рамки того класса задач, которые
существующие методы машинного обучения уже умеют решать). Проблема
эффективности вывода в таких языках, приводит к плохой масштабируемости на
задачи реального мира. Перспективны в исследованиях, связанных с когнитивным
моделированием и общим искусственным интеллектом.
Пример: язык
Church
(Чёрч, расширение диалекта Scheme для языка Лисп) с web-реализацией (web-church)
позволяющей экспериментировать без установки дополнительного программного
обеспечения.
Языки
вероятностного программирования
(перечень с
кратким описанием каждого) здесь.
См. Вероятностное программирование – ключ к искусственному
интеллекту?
http://habrahabr.ru/post/242993/ |
ML на векторных моделях
|
Для обучения
нейронных сетей без учителя использоваться
представления слов в виде векторов в многомерном
пространстве.
Оценка
подобия (степени их совместного появления) слов на основе
данного векторного
представления используются в области машинного
перевода.
На рисунке: линейные
отображения векторных
представлений слов английского и испанского
языков спроецированы на двухмерное пространство с помощью метода
PCA
(principal component analysis, главных компонентов), а потом повернуты,
чтобы подчеркнуть сходство структур в двух языках.
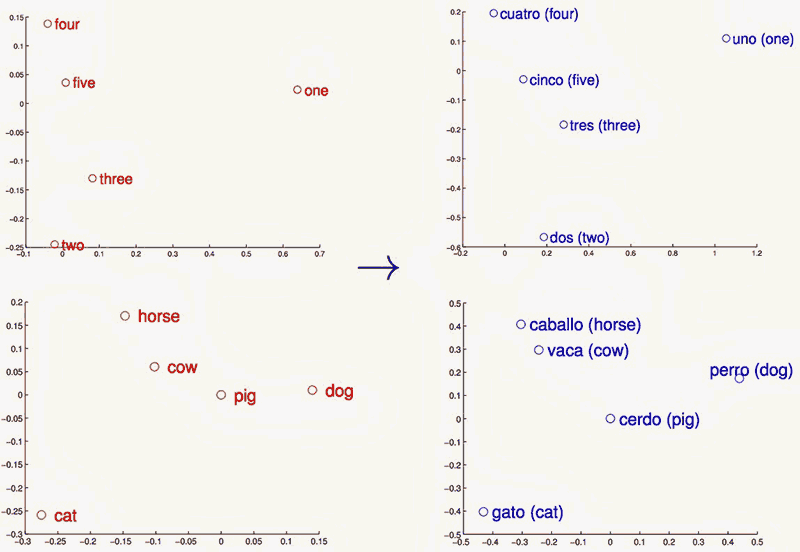
|
Azure ML
Studio
|
Теоретическая часть машинного обучения требует глубокой математической
подготовки, что делает снижает популярность его инструментария среди
разработчиков.
Однако практическое использование машинного обучения в собственных
приложениях может быть достаточно простой задачей.
Azure
Machine Learning
– это облачная инструментальная среда разработки:
-
предоставляющая десятки
готовых алгоритмов машинного обучения – от простейшего
алгоритма линейной регрессии, до сложных и
специализированных
-
позволяющая в простой и
наглядной форме
-
с помощью готовых
компонентов
машинного обучения
-
собрать необходимый
процесс обработки данных
-
провести
экспериментальную проверку их эффективности
-
и в случае успеха
опубликовать все в виде сервиса
-
распространяя и монетизируя
полученные модели
-
посредством использования из
в мобильных приложениях
Построение модели машинного обучения в
Azure ML
Studio:
-
Определение
задачи (требуемого
результата)
-
Загрузка данных
(или использование готовых
данных репозитариев)
-
Создание нового эксперимента
-
Формирование выборки данных для дальнейшего обучения модели
-
Подготовка данных (формирования
характеристик, удаления выбросов и разделения выборки на
обучающую и тестовую.
-
Выбор моделей данных и
соответствующих алгоритмов обучения, которые могут дать
требуемый результат.
-
Обучение модели (поиск
скрытых закономерностей в выборке данных с целью отыскания
способа предсказания алгоритмом обучения на основе выбранной
модели).
-
Оценка модели (исследование
ее прогностическиз характеристик на тестовой выборке и
замеры уровеней ошибок.
-
Принятие модели в качестве
итоговой или повторное обучение после добавления новых
входных характеристик или изменения алгоритма обучения.
-
Публикация веб-сервиса
-
Тестирование сервиса
-
Разработка приложения
-
Мониторинг и монетизации модели
|
RNN и LSTM
Рекуррентные сети (RNN,
Recurrent
neural network)
- нейросетевая архитектура для работы
с последовательностями произвольной длины.
Рекуррентный — значит возвращающийся.
Рекуррентные сети отличаются наличием
некоторого внутреннего состояния, которое обновляется при
прохождении по всем элементам последовательности.
Рекуррентная сеть на каждом шаге может
сгенерировать новый выход для любого слоя многослойной нейронной
сети.
В классических RNN (vanilla RNN)
функция обновления внутреннего состояния — это просто некоторая
нелинейность поверх линейного преобразования входа и предыдущего
состояния, а выход — тоже нелинейность поверх линейного
преобразования внутреннего состояния.
С возникновением идеи рекуррентных
сетей появилась надежда на качественное решение
задач NLP (обработки текста на
естественных языках).
Рекуррентные сети (RNN)
позволяют помнить предыдущее состояние, тем самым снижая количество
данных подаваемых на вход сети.
RNN угадывает следующие слова в тексте (ноты в мелодии),
возвращаясь к своим прошлым догадкам, которые нейросеть хранит
как вектор активации нейронов и передает с шага на шаг.
Необходимость «зацикливания» и «обладания
памятью» нейронных сетей обусловлена тем, что данные голоса или текста
невозможно подать на вход сети в полном объёме, они возникают некоторыми
порциями, разделенными во времени.
|
один ко многим |
многие к
одному |
многие ко
многим |
многие ко
многим |
|
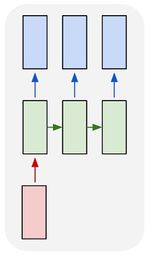 |
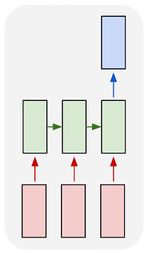 |
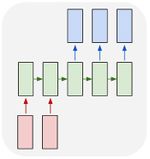 |
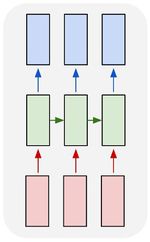 |
|
в генерации
текста |
в
сантимент-анализе |
в переводе |
в
классификации |
Развитием модели
RNN и их
разновидностью являются
LSTM
( сети с долгой краткосрочной памятью, Long short-term memory), для которых разработан специальный тип нейронов, переводящий себя
в возбужденное состояние на основе некоторых значений и не меняющий его
пока на вход не придет деактивационый вектор.
LSTM не передает контекст целиком,
а решает, какую часть использовать, а какую — забыть.
LSTM имеет
модификации, чтобы лучше отличать важный контекст от неважного.
LSTM сети в том числе помогают решить
задачу преобразования последовательности в последовательность
возникающую при переводе одного языка на другой.
Системы на основе RNN и LSTM впервые превзошли человека в распознавании фраз и
рукописного ввода.
|
CNN
Сверточная нейронная сеть
(convolutional
neural network, CNN) — специальная
архитектура нейронных сетей, изначально нацеленная на эффективное
распознавание изображений.
Свертка
(convolution) — операция над парой матриц.
В сверточной нейронной сети выходы промежуточных слоев образуют
матрицу (изображение) или набор матриц (несколько слоёв
изображения).
Чтобы получить матрицы для работы
с текстом берётся
embedding
для каждого слова и ставятся все вектора в ряд, получая
искомую матрицу.
Сверточный слой
нейронной сети представляет из себя применение операции свертки к
выходам с предыдущего слоя, где веса ядра свертки являются
обучаемыми параметрами.
В одном сверточном
слое может быть несколько сверток.
Свёрточная нейронная сеть анализирует полученные данные
одновременно, а не последовательно, как в RNN.
Ряд задач NLP
на основе CNN
(свёрточных нейронных сетей, сonvolutional neural network) решается
быстрее, чем на основе RNN.
Что
такое свёрточная нейронная сеть
Применение сверточных нейронных сетей для задач NLP
|
Embedding
Embedding (вложение)
—
сопоставление произвольной сущности (слова, слога, узла в графе,
фрагмента речи или картинки) некоторому вектору (в многомерном
пространстве).
Embedding
— сопоставление точки в каком-то многомерном пространстве объекту
(слову...).
Embedding
— процесс (результат процесса) преобразования языковой сущности
(слова, предложения, параграфа или целого текста) в набор чисел –
числовой вектор
Embedding
— числовой вектор (упорядоченный список чисел), полученный из
языковых сущностей.
Концепция
вложений (embeddings) — одна из самых замечательных идей в
машинном обучении.
Простейшие эмбеддинги слов
получают простой нумерацией слов в словаре и установкой значения
единицы в длинном векторе размерности, равной числу слов в
словаре. Пронумеруем слова Толкового словаря Ушакова (85 289
слов). Слово «абака» преобразуется в число 5. Эмбеддинг слова
«абака» будет иметь 85288 нулей на всех позициях, кроме пятой,
где будет стоять 1. Этот метод построения эмбеддингов называют
унитарным кодированием (one-hot encoding). Любому предложению на
русском языке можно попытаться поставить в соответствие
последовательность (кортеж) таких 85289-мерных векторов. И тогда
действия над словами могут быть преобразованы в действия над
этими числовыми векторами, что собственно и свойственно
компьютеру.
Проблема: отсутствие в выбранном
словаре слова, для которого ищется эмбеддинг.
В революционной работе Томаша
Миколова (2013) предложено использовать гипотезу локальности:
«слова, которые встречаются в одинаковых окружениях, имеют
близкие значения». Близость в данном случае – это стоящие рядом
сочетающиеся слова. Для получения таких свойств нужно строить
эмбеддинги слов в высокоразмерном (но не зависящем от числа
слов) векторном пространстве. Чтобы каждому слову теперь
соответствовал набор из двух-пяти сотен чисел, и эти наборы
удовлетворяли свойствам математического векторного пространства
(чтобы их можно было складывать, умножать на скаляры, находить
между ними расстояния и при этом каждое такое действие с
числовыми векторами имело смысл как некоторое действие над
словами).
Томаш Миколов назвал метод
получения таких эмбеддингов «word2vec».
Он основан на использовании вероятностной оценки совместного
употребления групп слов и самообучаемой на корпусах текстов
нейронной сети.
Модели получения эмбеддингов слов,
предложений и документов
-
GloVe, разработанная в
Стэнфорде,
-
fastText – разработанная
Facebook,
-
doc2vec – модель, отображающая
в числовой вектор целый документ.
-
BERT (Google AI Language,
2018).
Word2vec
— совокупность моделей на основе искусственных нейронных сетей,
предназначенных для получения векторных представлений слов на
естественном языке.
Чудесный мир Word Embeddings: какие они бывают и зачем нужны?
Word2vec в картинках
Word2Vec: как работать с векторными представлениями слов
Что
такое эмбеддинги...
Векторное_представление_слов
|
Transformer
Трансформер
– это архитектура, основанная на
attention
(механизме внимания),
благодаря чему модель оптимизирует интенции на разные части текста и
таким образом лучше выучивает закономерности, необходимые для
решения задачи.
Механизм
внимания
(attention mechanism, attention model,
attention) — техника используемая в
рекуррентных нейронных сетях (RNN) и сверточных нейронных сетях
(CNN) для поиска взаимосвязей между различными частями входных и
выходных данных.
По аналогии с
RNN (рекуррентными нейронными сетями) трансформеры предназначены для
обработки последовательностей (в том числе текстов на естественном
языке: машинный перевод, автогенерация текста, автоматическое
реферирование и др.).
В отличие от RNN,
трансформеры не требуют обработки последовательностей по порядку.
Например, если
входные данные — это текст, то трансформеру не требуется
обрабатывать конец текста после обработки его начала.
Благодаря этому трансформеры распараллеливаются легче чем RNN и
могут быть быстрее обучены.
04.06.2021
Упадок RNN и LSTM сетей
(оригинал)
-
Мы
полюбили RNN (рекуррентные нейронные сети), LSTM (Long-short
term memory), и все их варианты.
-
В
течении нескольких лет они был способом решения таких
задач как: последовательное обучение, перевод
последовательностей (seq2seq). Так же они позволили
добиться потрясающих результатов в понимании речи и
переводе ее в текст. Эти сети поспособствовали
восхождению таких голосовых помощников как Сири, Кортана,
Гугл и Алекса. Не забудем и машинный перевод, который
позволил нам переводить документы на разные языки. Или
нейросетевой машинный перевод, позволяющий переводить
изображения в текст, текст в изображения, делать
субтитры для видео и т.д.
-
Затем, в 2015-16 появились ResNet и Attention
(«Внимание»). Тогда начало приходить понимание, что LSTM
– была умной техникой обойти, а не решить задачу. Так же
Attention показал, что MLP сеть (Multi-Layer Perceptron
Neural Networks - многослойные персептроны) может быть
заменена усредняющими сетями, управляемыми вектором
контекста.
-
Завязывайте с RNN и LSTM, они не так хороши!
Используйте Attention. Внимание, - действительно всё,
что вам нужно!
|
Transfer Learning
Трансферное
обучение (подраздел ML) — применение
знаний, полученных благодаря решению одной задачи, к другой, но
схожей задаче.
TL основано на предобученных моделях (обученных на больших наборах
общедоступных данных).
Transfer Learning с использованием TensorFlow.JS
Deep Learning: Transfer learning и тонкая настройка глубоких
сверточных нейронных сетей
Погружение в свёрточные нейронные сети: передача обучения
(transfer learning)
BERT,
ELMO и Ко в картинках (как в NLP пришло трансферное обучение)
Эффективность
трансферного обучения в предварительном обучении модели на большом
неразмеченном корпусе текстов для одной из задач самообучения (self-supervised
learning).
Например:
языкового моделирования (или перевода, или заполнения пропусков
в тексте).
Затем модель
дообучается на меньших наборах данных показывая (часто) значительно
лучшие результаты, чем в случае обучения на одних только размеченных
данных.
2018 Первые
успехи трансферного обучения на моделях GPT, ULMFiT, ELMo, BERT)
2019 Новые
успехи на новых моделях: XLNet, RoBERTa, ALBERT, Reformer и MT-DNN.
|
GPT (OpenAI)
OpenAI
(https://openai.com/) —
американская компания разработкой в области машинного обучения,
основана (И. Маск +) в конце 2015 с целью создать открытую компанию,
работающую на благо общества, а не государства или корпорации.
GPT
(Generative Pre-trained Transformer)
— модель
обработки естественного языка от OpenAI на архитектуре трансформер
(150 миллионов параметров). Создана летом 2018.
GPT-2
— второе поколение модели обработки
естественного языка от OpenAI, авторегрессионная генеративная
языковая модель на архитектуре трансформер (1,5 млрд. параметров).
Создана в феврале 2019.
GPT-3
— третье поколение модели обработки естественного языка от OpenAI,
авторегрессионная генеративная языковая модель на архитектуре
трансформер (175 млрд. параметров). Создана в мае 2020.
Обучение
GPT-3
происходило на суперкомпьютере Microsoft Azure AI, который был
построен специально для OpenAI.
На обучение
могло уйти от $4,6 млн.
Для обучения
алгоритма исследователи собрали датасет из более 570 ГБ текстов
(0,11 % документов были на русском языке).
Как работает GPT-2 и в чем его
особенности
Generative Pre-trained Transformer 3
(GPT-3) от
OpenAI:
GPT-3 от OpenAI может стать величайшей вещью со времён Bitcoin
Сбер выложил русскоязычную модель GPT-3 Large с 760 миллионами
параметров в открытый доступ
The Illustrated GPT-2
(Visualizing Transformer Language Models)
How GPT3 Works -
Visualizations and Animations
A robot wrote this entire article. Are you
scared yet, human?
статья
GPT-3 для The Guardian о том, что не следует бояться ИИ
GPT-3:
Response to Philosophers ответ GPT-3 на эссе философов
OpenAI's GPT-3 may be the
biggest thing since bitcoin
Humans vs AI (A/B testing
OpenAI's GPT-3)
It’s Not Just Size That
Matters: Small Language Models Are Also Few-Shot
Learners
GPT-3 Bot Spends a Week
Replying on Reddit
|
B ERT,
SMITH
BERT
от Google — это усовершенствованная сеть GPT от OpenAI
(двунаправленная вместо однонаправленной и т.д.) на архитектуре
Transformer.
С декабря 2019-го Google
официально использует BERT в поиске (превью наиболее вероятного
ответа на запрос — это тоже его работа).
BERT
— state-of-the-art языковая модель для 104 языко
Ваш
первый BERT: иллюстрированное руководство
BERT,
ELMO и Ко в картинках (как в NLP пришло трансферное обучение)
BERT хорошо распознает смысл,
скрытый в словах и коротких предложениях, но
часто посредственно справляется с пониманием контекста
объёмных текстов.
SMITH
от Google
— разрабатываемая модель
обучения нейросетей,
которая может сменить (дополнить)
BERT
SMITH дожен уметь понимать контекст
отдельных фрагментов текста относительно всего содержимого
публикации, что повысит точность интерпретации больших документов.
|
Text-To-Text Transfer
Transformer (T5)
T5
(Text-To-Text Transfer Transformer)
- новая модель трансферного обучения в парадигме
text-to-text.
В парадигме
(модели, формате, фреймворке)
text-to-text
вход и выход модели представляются текстовыми строками
В модели
BERT на выходе метку класса, или фрагмент входной
последовательности.
Фреймворк
text-to-text
позволяет использовать одну и ту же модель, функцию потерь и
гиперпараметры для любой задачи NLP, включая:
-
машинный
перевод,
-
суммаризацию документов,
-
определение семантической
близости,
-
определение грамматической
состоятельности,
-
вопросно-ответные системы,
-
задачи
классификации
-
анализ
тональности.
-
другое...
|
Важная составляющая трансферного обучения – это наличие
неразмеченного набора данных, используемого для
предварительного обучения (важны качественные,
разнообразные данные и большие данные). Это редкость:
Тексты Wikipedia высокого
качества, однообразны стилистически и малого объема.
Тексты
Common
Crawl (обработанные тексты из веб-сканирования)
огромны, разнообразны, низкого качества)
Для того, чтобы удовлетворить требованиям, описанным
выше, был разработан Colossal Clean Crawled Corpus (C4) – очищенная версия Common
Crawl, объем которой в 100 раз превышает объем
Википедии.
Процесс очистки набора данных включал удаление
дубликатов, неполных предложений, а также
неприемлемых или мусорных текстов. Подобная
фильтрация способствовала получению лучших
результатов в прикладных задачах, в то время как
большой объем позволил увеличить размер модели без
риска переобучения.
С4 доступен в TensorFlow Datasets.
|
Т5
предобучается на новом открытом наборе данных для обучения –
Colossal Clean Crawled Corpus (C4).
Для каждой
задачи на вход модели Т5
подается текст
Обучение
Т5 состоит
в генерации некоторого целевого текста.
В
T5 text-to-text и новом наборе данных для предварительного обучения
С4 исследовалось и применялось множество новейших идей и технологий
в сфере трансферного обучения. Выяснилось, что:
-
модели с
энкодером и декодером обычно превосходят языковые модели с
одним декодером;
-
задачи
типа заполни_пропуск (где модель обучается восстанавливать
пропущенные слова во входном тексте) являются наилучшим
решением и что самым важным фактором оказываются затраты на
вычисление;
-
обучение
на данных определенной предметной области может оказаться
полезным,
-
предварительное обучение на небольших наборах данных может
привести к переобучению;
-
многозадачное обучение может быть сравнимо с предварительным
обучением и последующей тонкой настройкой, однако требует
внимательного выбора частоты обучения модели на определенную
задачу;
В Т5 использовались
Google Tensor Processing Unit Google Cloud.
Крупнейшая
модель Т5
имела 11 000 000 000 параметров и достигла уровня
state-of-the-art в рамках бенчмарков GLUE, SuperGLUE, SQuAD и
CNN/Daily Mail. Модель с 11 миллиардами параметров генерирует
точный текст ответа в 50.1%, 37.4% и 34.5% случаев в заданиях
TriviaQA, WebQuestions и Natural Questions соответственно.
Команда разработчиков Т5 играла против модели в викторине Pub
trivia challenge и проиграла!
Можно поиграть с Т5
Неожиданным
результатом оказалось достижение человеческого уровня в понимании
естественного языка в рамках бенчмарка SuperGLUE, который
разрабатывался намеренно сложным для моделей машинного обучения, но
легким для человека.
Т5, предобученная на
корпусе С4:
-
показывает наилучшие результаты во
многих NLP-бенчмарках,
-
обладает большей гибкостью для тонкой
настройки под конкретные задачи обработки текстов.
23 Oct 2019
Exploring the Limits of Transfer Learning with a Unified Text-to-Text
Transformer
24 Feb 2020
Exploring Transfer Learning with T5: the Text-To-Text Transfer
Transformer
mT5
mT5 —
предобученный мультилингвальный Transformer для 101 языков от
Google AI.
-
mT5
основан на
версии T5.1.1 модели T5 и
является T5 (схожи архитектура модели и
процедура обучения)
-
mT5
обучался на корпусе веб-страниц из Common Crawl на 101 языках —
mC4.
-
В
mT5
используют GeGLU нелинейность и предобучают на неразмеченных
данных без использования dropout.
-
Данные на разных языках семплировали для
регулировки баланса между редкими и популярными языками
веб-страниц, вычисляя вероятность семплинга текста на
определенном языке.
-
mT5
обходит существующие Transformer-модели на всех задачах и по
всем метрикам.
Сравнение state-of-the-art мультилингвальных
Transformer-моделей на задачах классификации пары
предложений, структурного предсказания и вопросно-ответной
системы с использованием бенчмарка xtreme.
См.
https://arxiv.org/pdf/2010.11934.pdf +
Github:
http://goo.gle/mt5-code
23.10.2020
mT5: A
massively multilingual pre-trained text-to-text transformer
|
Meena
|
29.01.2020
Google
представляет Meena, чат-бота на нейросетях
Meena
— максимально "человечная" модель, работающая на основе
нейросетей:
-
основана на архитектура Evolved Transformer seq2seq
-
имеет 2,6 млрд параметров (в 1,7 раза больше, чем у OpenAI
GPT-2)
-
обучалась на 341 Гб текста ( в 8,5 раз больше, чемOpenAI
GPT-2)
-
работает с помощью одного блока кодера Evolved Transformer и
13 блоков декодера Evolved Transformer.
Кодер отвечает за обработку контекста разговора, чтобы Meena
могла понять смысл сказанного.
Затем декодер использует эту информацию для формулирования
ответа.
Существующие оценки качества чат-бота малоэффективны из-за их
сложности и несогласованности.
Разработана новая метрика оценки под названием Sensibleness and
Specificity Average (SSA), которая фиксирует основные атрибуты
общения бота с людьми:
-
каждый разговор начинается одинаково — с приветствия
-
каждый ответ оценивается по двум параметрам — осмысленность
и конкретность.
-
если ответ кажется неправильным (запутанным, нелогичным
или фактически неверным), он оценивается как не имеющий
смысла. Если ответ проходит по критерию осмысленности,
то дальше высказывание оценивается как конкретное (связанное
с предметом обсуждения) или нет.
-
чувствительность чат-бота (Sensibleness) складывается из
доли ответов, помеченных как «разумные»
-
специфичность (Specificity) — складывается из доли ответов,
помеченных как «конкретные».
Среднее из этих двух — оценка SSA.
Perplexity(недоумение) —
дополнительный параметр оценки
Meena —
автоматическая метрика, измеряющая неопределенность языковой
модели. Чем ниже этот показатель, тем больше уверенности в том,
что модель сгенерирует свой ответ правильно, и тем выше
оказывается показатель SSA.
У Meena показатель недоумения равен 10,2, что соответствует SSA
в 72%.
Оценка SSA человека, как утверждает Google, составляет в среднем
86%.
27.09.2020
Фейсбук представил
SOTA open-domain
— чатбот
модель (милиларды параметров, по архитектуре — трансформер).
На human evaluation модель от FB получилась сильно лучше прошлой SOTA
модели — Meena от Google
|
DeBERTa
DeBERTa
(Decoding-enhanced BERT with
disentangled attention,
BERT с улучшенным декодированием и рассеянным вниманием)
– это модель
понимания естественного языка (NLU,
Natural Language Understanding) от
Microsoft.
DeBERTa имеет,
отличный от оригинального трансформера, разделённый механизм
внимания, где каждый токен кодируется векторами контента и
позиции, которые не суммируются в один вектор, c ними работают
отдельные матрицы.
DeBERTa
имеет 48 слоёв и 1,5 млрд
различных тренировочных параметров (в
8 раз меньше T5).
DeBERTa
по умолчанию учитывает не только значения слов, но и их позиции
и роли в предложении.
В
предложении «новый магазин открылся рядом с торговым центром»
(a new store opened beside the new mall»
поймёт, что близкие по контекстному значению слово «магазин»
(store) и словосочетание «торговый центр» (mall) играют
разные синтаксические роли (подлежащим здесь является именно
«магазин»).
DeBERTa
может определять зависимость слов друг от
друга.
Понимает,
что зависимость между словами «deep» и «learning» гораздо
сильнее, когда они стоят рядом (термин «глубокое обучение»),
чем когда они встречаются в разных предложениях.
DeBERTa
превзошла базовые показатели человека в тесте SuperGLUE на
сложное понимание естественного языка (NLU).
Средний показатель для людей не экспертов составляет 89.8
баллов, и задачи, которые нужно решать модели, сравнимы с
экзаменом по английскому. DeBERTa показала 90.3, следом за
ней идет T5+Meena от Google.
Microsoft
собирается интегрировать
DeBERTa в следующую версию тьюринговой модели
Microsoft Turing
(Turing NLRv4).
Microsoft применяет тьюринговые модели в целом спектре своих
продуктов, среди которых поисковик бинг Bing, пакет офисных
программ и Office облачный сервис Azure Cognitive Services. В
них они используются, помимо прочего, чтобы совершенствовать
взаимодействие с чат-ботами, предоставление рекомендаций и
ответов на вопросы, поиск, автоматизацию поддержки клиентов,
создание контента и т. д.
12.02.2020
Turing-NLG: в Microsoft обучили языковую модель с 17 миллиардами
параметров
|
CNTK на
Github
|
В 2015 году многие
крупные компании опубликовали на Github свои разработки:
-
Google - TensorFlow,
-
Baidu -
warp-ctc.
-
Microsoft выложила в открытый доступ на
Github
исходный код
Computational Network Toolkit
- набора инструментов,
для проектирования и тренировки сетей
различного типа, которые можно использовать для распознавания
образов, понимания речи, анализа текстов и многого другого.
Computational Network Toolkit
победила в конкурсе ImageNet LSVR 2015 и
является самой быстрой среди существующих конкурентов.
Computational Network Toolkit является
попыткой систематизировать и обобщить основные подходы по построению
различных нейронных сетей, снабдить ученых и инженеров большим набором
функций и упростить многие рутинные операции. CNTK позволяет создавать сети
глубокого обучения (DNN),
сверточные сети (CNN),
рекуррентные сети и сети с памятью (RNN,
LSTM).
CNTK помогает решить задачи инфраструктурного
характера, в частности, у него уже есть подсистемы чтения данных из
различных источников. Это могут быть текстовые и бинарные файлы, изображения,
звуки.
Ядро CNTK создано на языке C++, но
предполагается создать интерфейсы на
Python bindings и C# .
Подробно о возможностях
и функциях CNTK: An
Introduction to Computational Networks and the Computational Network Toolkit.
Об использовании
CNTK узнать из CNTK
Wiki.
Краткое введение в CNTK в
материалах
NIPS 2015 опубликовано
здесь
Примеры
наиболее распространенных подходов
в решении задач применимых к нейронным сетям.
В CNTK входит несколько примеров анализа
речи, на основе
AN4 Dataset, Kaldi
Project, TIMIT,
и проект по трансляции на основе
работы.
Анализ текста представлен проектами по
анализу комментариев, новостей, и произнесенных фраз (spoken language
understanding,
SLU).
24.01.2016
Microsoft выложила в открытый доступ на
Github
исходный код
Computational Network Toolkit
- инструментов, которые используются в компании для глубинного обучения
в области искусственного интеллекта
(проектирования и тренировки сетей различного типа, которые можно
использовать для распознавания образов, понимания речи, анализа текстов
и многого другого).
 Сюэдун
Хуан
(Xuedong Huang, ведущий специалист Microsoft по системам распознавания
речи): Сюэдун
Хуан
(Xuedong Huang, ведущий специалист Microsoft по системам распознавания
речи):
-
Разработчики
в моей группе были озабочены проблемой, как ускорить процесс
распознавания речи компьютерами, а имеющиеся инструменты работали
слишком медленно. Поэтому группа добровольцев вызвалась решить
проблему самостоятельно, используя собственное решение, которое
ставило производительность на первое место.
-
Усилия окупились сполна. Во внутренних тестах
CNTK показал более
высокую производительность,
чем другие популярные вычислительные инструментарии, которые
разработчики используют для создания моделей глубинного обучения в
задачах вроде распознавания речи и распознавания образов, за счёт
лучших коммуникационных возможностей. Инструментарий CNTK просто
невероятно более эффективен, чем всё, что нам доводилось видеть
В компании Microsoft инструментарий CNTK используется на кластере
компьютеров для обработки алгоритмов синтеза и распознавания речи,
распознавания изображений и движения на видео.
|
"Войны" нейронных сетей
Generative adversarial networks
(GAN) -
соперничающие нейронные сети
-
Есть две нейронных сети. Первая сеть,
порождающая, обозначим ее как функцию yG=G(z),
на вход она принимает некое значение z,
а на выходе выдает значение yG.
Вторая сеть, различающая, и мы ее обозначим как функцию yD=D(х),
то есть на входе — x,
на выходе — yD.
-
Порождающая сеть должна научиться
генерировать такие образцы yG,
что различающая сеть D не
сможет их отличить от неких настоящих, эталонных образцов. А
различающая сеть, наоборот, должна научиться отличать эти
сгенерированные образцы от настоящих.
-
Изначально сети не знают ничего, поэтому
их надо обучить на основе набора обучающих данных — (Xi,
Yi).
На вход сети последовательно подаются Xi и
рассчитываются yi=N(Xi).
Затем по разнице между Yi (реальное
значение) и yi (результат
работы сети) перерассчитываются коэффициенты сети и так по
кругу.
На каждом шаге обучения вычисляется значение функции потерь (loss
function), по градиенту которой потом пересчитываются
коэффициенты сети. А вот функция потерь уже учитывает отличие Yi от yi.
-
Вместо минимизации функции потерь в ходе
обучения сети можно решать другую оптимизационную задачу -
максимизации функции успеха. И это используется в
GAN.
-
Обучение первой, порождающей, сети
заключается в максимизации функционала
D(G(z)). То есть эта сеть стремится
максимизировать не свой результат, а результат работы второй,
различающей, сети.
-
Порождающая сеть должна научиться для любого значения, поданного
на ее вход, сгенерировать на выходе такое значение, подав
которое на вход различающей сети, получим максимальное значение
на ее выходе (а это означает, что порождающая сеть порождает
правильные образцы).
-
Порождающая сеть будет учиться по
градиенту результата работы различающей сети.
-
Обучение различающей сети заключается в
максимизации функционала
D(x)(1 — D(G(z))). Она должна выдавать
1 для эталонных образцов и 0 для образцов, сгенерированных
порождающей сетью. Причем сеть ничего не знает о том, что ей
подано на вход: эталон или подделка. На каждом шаге
обучения различающей сети один раз рассчитывается результат
работы порождающей сети и два раза — результат работы
различающей сети: в первый раз ей на вход подается эталонный
образец, а во второй — результат порождающей сети.
-
Обе сети связаны в неразрывный круг
взаимного обучения. И чтобы вся эта конструкция работала нам
нужны эталонные образцы — набор обучающих данных(Xi).
Заметьте, что Yi здесь
не нужны. Хотя, понятно, что на самом деле по умолчанию
подразумевается, что каждому Xi соответствует Yi=1.
-
В процессе обучения на вход порождающей
сети на каждом шаге подаются какие-то значения, например,
совершенно случайные числа (или совсем даже неслучайные числа —
рецепты для управляемой генерации). А на вход различающей сети
на каждом шаге подается очередной эталонный образец и очередной
результат работы порождающей сети.
-
В результате порождающая сеть должна
научиться генерировать образцы как можно более близкие к
эталонным. А различающая сеть должна научиться отличать
эталонные образцы от порожденных.
|
A Visual and Interactive Guide to the Basics
of Neural Networks
TensorFlow
|
TensorFlow
- библиотека с открытым исходным кодом программного обеспечения для
численных расчетов с помощью диаграмм потока данных.
TensorFlow
предназначена для студентов, исследователей, любителей, хакеров,
инженеров, разработчиков, изобретателей.
TensorFlow Developer Summit
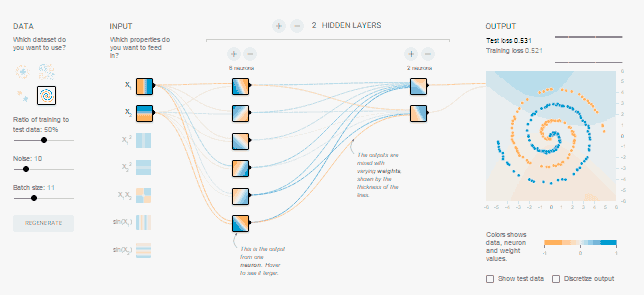
Для знакомства с работой нейронных сетей и экспериментов в области
машинного обучения
TensorFlow
предоставляет
Учебную нейросеть,
которая может быть использована непосредственно в браузере (в том
числе для реальных
приложений за счет связей с ресурсами библиотеки
TensorFlow).
Учебная нейросеть:
-
имеет
входы и выходы,
-
реализует между нейронами,
-
содержит скрытые слои, в которых отображены весовые коэффициенты
межнейронных связей.
-
задается наборами входных данных
-
позволяет задавать уровень шума
(аналога дискурсивного наречия "почти")
-
содержит
простейшие средства управления процессом обучения.
«Удачные» связи отмечаются на обучаемых слоях синим, неудачные –
оранжевым.
П ри
всей кажущейся простоте варьирования параметров Учебной нейросети,
ее обучение не столько ремесло и наука, сколько искусство.
выращивания ИИ на простейшей когнитивной модели
Работе с нейросетями надо учиться.
Учебная нейросеть
инструмент, который дает возможность
поэкспериментировать с нейросетями и получить нужные для этого навыки.
30.03.2018
TensorFlow интегрирован с JavaScript и
задачи можно запускать прямо из браузера
22.05.2019
Машинное обучение глубокой нейронной сети с подкреплением
на tensorflow.js:
Трюки
Репозиторий с кодом
Запустить обучение в браузере
Документация по tensorflow.js,
где также можно найти дополнительные ресурсы для изучения.
|
Решения
DeepMind
|
DeepMind
основана в 2010 году в Лондоне, в 2014 году приобретена Google за $500
000 000.
Одним из условий сделки DeepMind с Google
было создание последней коллегии по этическим проблемам искусственного
интеллекта.
Цель компании — «решить проблему интеллекта»,
реализовать его в машинах и понять, как работает мозг человека.
Демис Хассабис
(основатель
DeepMind):
В начале
обучения система ИИ DeepMind ничего не знает о правилах игры и учится играть
самостоятельно, используя на входе только пиксельное изображение
игры и информацию об очках, получаемых в ходе игры. В основе ИИ
лежит глубинное
обучение с подкреплением (deep Q-network (DQN)) -
вариация обучения с подкреплением без модели с применением
Q-обучения, в котором функция полезности моделируется с помощью
глубинной нейронной сети. В качестве архитектуры нейросети выбрана
свёрточная нейронная сеть.
В
2015 AlphaGo от победила
DeepMind в го лучших игроков.
В
2017 AlphaZero в течение 24 часов достигла сверхчеловеческого уровня игры в
шахматы, сёги, и го, победив чемпионов мира среди программ.
Гарри
Каспаров:
-
AlphaZero - большой плюс для шахмат. Бояться этого не
надо: "Человек же не соревнуется в скорости с автомобилем. И
шахматистам искусственный интеллект не помешает играть друг с
другом. Главное - наслаждаться красотой шахмат.
-
С
помощью AlphaZero мы будем всё больше и больше открывать шахматы. Находка
ярко демонстрирует несовершенство наших шахматных знаний. Я смотрю партии и думаю: как много,
оказывается, я не понимаю! Выясняется, что какие-то идеи, которые
раньше считались неоспоримыми, могут не работать! Очень
увлекательно.
Публикации DeepMind затрагивают следующие темы: понимание
естественного языка машинами, генерация изображений по шаблону с
помощью нейронных сетей, распознавание речи, алгоритмы обучения
нейронных сетей.
В
2016 начато сотрудничество с Blizzard для обучения ИИ в Starcraft II.
Ведется работа над «Starcraft 2 API», которая позволяет ИИ полностью
взаимодействовать с интерфейсом игры, принять участие в разработке
может любой желающий
28.05.2019
AlphaFold: Using AI for scientific discovery (краткий
конспект):
|
Хм...
|
03.06.2016
-
Warner
Bros. отправили
уведомление видеохостингу Vimeo о нарушении авторских прав
согласно Закону об авторском праве в цифровую эпоху (Digital
Millennium Copyright Act, DMCA) и список нелегально закачанных
видеоматериалов, правами на которые владеет Warner. Заявление
было отозвано из-за ошибки - часть видео была не взята из фильма, а
в рамках проекта
Теренса
Броуда
[Terence Broad] воссоздана с помощью машинного обучения. Warner не
смогла отличить симуляцию и настоящую вещь.
Теренс Броуд
учил нейросеть смотреть кино – не так, как это делают люди, но так,
как это подходит машине. Научившись распознавать данные фильма,
кодировщик уменьшил каждый кадр до представления в виде числа из 200
цифр, и затем реконструировал это число обратно в новые кадры, с
целью добиться совпадения с оригиналом. Версия фильма от нейросети
полностью уникальна и создана на основе того, что она увидела в
оригинальном фильме – это интерпретация фильма системой основанная
на ограниченном понимании.
|
Хм...
|
03.06.2016
-
Warner
Bros. отправили
уведомление видеохостингу Vimeo о нарушении авторских прав
согласно Закону об авторском праве в цифровую эпоху (Digital
Millennium Copyright Act, DMCA) и список нелегально закачанных
видеоматериалов, правами на которые владеет Warner. Заявление
было отозвано из-за ошибки - часть видео была не взята из фильма, а
в рамках проекта
Теренса
Броуда
[Terence Broad] воссоздана с помощью машинного обучения. Warner не
смогла отличить симуляцию и настоящую вещь.
Теренс Броуд
учил нейросеть смотреть кино – не так, как это делают люди, но так,
как это подходит машине. Научившись распознавать данные фильма,
кодировщик уменьшил каждый кадр до представления в виде числа из 200
цифр, и затем реконструировал это число обратно в новые кадры, с
целью добиться совпадения с оригиналом. Версия фильма от нейросети
полностью уникальна и создана на основе того, что она увидела в
оригинальном фильме – это интерпретация фильма системой основанная
на ограниченном понимании.
|
Проблемы применения ML
A New Approach to Understanding How Machines
Think (перевод)
Основные проблемы:
Нейросеть может выдать 1000 верных ответов
и 1 неприемлимо ошибочный, но
не сможет объяснить, что привело его к такому заключению. Не существует способа понять, на какие
именно особенности данных нейросеть «обращает внимание». Это
«знание» размазано по множеству слоёв из искусственных нейронов,
у каждого из которых есть связи с сотнями или тысячами других
нейронов.
Проблема «чёрного ящика» не технологический недочёт, а
фундаментальное ограничение!
Проект
XAI (eXplainable AI, объяснимый ИИ) от DARPA занимается
интерпретируемостью ML - разрабатывает
систему TCAV (Testing
with Concept Activation Vectors, Испытание векторов активации
концепций) - «переводчик на человеческий»,
который позволит расспросить нейросистему по поводу принятых ею решений.
Бин Ким
(Been
Kim, Google Brain):
-
Не надо понимать каждую
мелочь модели. Но наша цель – понять достаточно для
того, чтобы этот инструмент можно было использовать
безопасно. Но как можно верить в систему, если не
понимать полностью, как она работает?
-
Если
мы не решим задачу интерпретируемости, мы не сможем
двигаться дальше с этой технологией, и, возможно просто от
неё откажемся – из страха или недостатка свидетельств
надежности.
-
TCAV
не направлен на установление доверия ИИ. Нам известно, что
люди очень доверчивы, их легко обмануть, заставив во что-то
верить. Цель интерпретируемости МО противоположна - сообщить
человеку, что конкретную систему использовать небезопасно.
Цель - раскрыть потенциальные ограничения в действиях ИИ.
|
ML от
Microsoft
|
29.11.2014
 Стефан Вейтц
(глава подразделения Bing, поисковой системы
Microsoft): Стефан Вейтц
(глава подразделения Bing, поисковой системы
Microsoft):
-
Bing
удерживает около 30%
рынка в США.
Лидирующий в
этом сегменте Google уже не побороть,
но обычный поиск по ключевым
словам теряет своё первостепенное значение.
-
Microsoft
улучшает поисковый движок на основе машинного обучения и
естественного языка.
-
Bing - основа, на
которой базируются Cortana и построен индексатор Apple Spotlight в
операционных системах iOS и Mac OS X.
Согласно comScore для США
в сентябре 2014
Bing
пользовались 29.4% пользователей (+0.1% за год),
Google
использовали 67.3% (+0.4% за год).
29.05.2014
Skype
Translate
— нейросеть,
осуществляющая
устный перевод для Skype с необычной способностью: чем больше
языков система осваивает, тем лучше начинает переводить с тех,
которые изучила до этого.
Технологии Skype Translate также используются в
Microsoft Cortana, которая понимает вопросы
на естественном языке и дает осмысленные ответы.
|
Почитать...
Математика для
искусственных нейронных сетей для новичков:
|
|