Direct Machine
Translation (модель
дословного перевода) - в тексте
выделяются отдельные слова, каждое из них переводится, согласуется
морфология (падежи, окончания) и синтаксис и получается
отвратительный (смешной, нелепый, абсурдный) результат.
Самая простая модель машинного
перевода, существует исключительно в воображении обывателей.
Никогда не была реализована в реальности.
Основные технологии
(модели)
машинного перевода
Rule-based machine translation (RBMT) — Машинный перевод на основе правил
(c 1950-хгодов XX
века)
Corpus-based machine translation (CBMT) — Машинный перевод на корпусах текстов
(с 1980-хгодов XX века)
Neural-based machine translation (NBMT)
— Машинный перевод на базе нейронных сетей (с 2015года от РХ)
Hybrid machine translation (HMT) — Гибридный машинный перевод (интеграция нескольких разных подходов машинного перевода)
Иногда выделяется Example-based machine translation (EBMT) — Машинный перевод на базе примеров.EBMT основан на принципе параллельного двуязычного корпуса текстов, где каждое предложение дублируется на другом языке
и является частным простым случаем
CBMT.
Каждая из технологий имеет свои достоинства и ограничения.
Каждая из технологий имеет область применения, для которой она является оптимальной.
Лингвистические корпуса
Корпусная лингвистика - область лингвистики, связанная с созданием и развитием корпусов текстов (Text corpus), их применением в качестве инструмента лингвистического исследования и др. областях (в т.ч. машинного перевода).
Лингвистический корпус (Тext corpus) - репрезентативная (соответствующая представляемой функционирования языка) совокупность текстов, собранных в соответствии с определёнными принципами (соответствующими задаче), размеченных (снабженных аннотациями),обеспеченных специализированной поисковой системой.
Корпус может содержать тексты одного языка (одноязычные корпусы) или нескольких языков (многоязычные корпусы, Comparable (Мultilingual) Сorpora).
Многоязычные корпусы, которые были созданы специально для сопоставительного сравнения, называют параллельными корпусами (Parallel Corpora)
Параллельный корпус (Parallel Corpora) - структурированное собрание параллельных переводных текстов, как правило состоящее из множества блоков, каждый из которых включает "текст-оригинал" и один/несколько его переводов.
Электронные тексты в корпусе могут представлять собой целое оригинальное словесное произведение или его часть.
Структурная организация корпуса может определяетсяих назначением и может быть оптимизирована специально для поддержки перевода (автоматического, автоматизированного, осуществляемого человеком).
Такие параллельные корпуса называются переводными корпусами (Translation Сorpora).
Основные структуры Translation Сorpora:
в виде традиционного текста со ссылкой на переводы,
в простой табличной (зеркальной) форме, что более удобно для восприятия и сравнения переводчиком (человеком),
в виде адаптированной для автоматизированного перевода базы данных (Translation Memory).
Translation Memory (память переводов) — база данных, содержащая набор переведенных текстов. Каждая запись в такой базе данных соответствует «единице перевода» (англ. translation unit), за которую принимается фрагмент текста (предложение, часть предложения, абзац). Если очередное предложение исходного текста в точности совпадает с предложением, хранящимся в базе (точное соответствие, exact match), оно может быть автоматически подставлено в перевод. Новое предложение может также слегка отличаться от хранящегося в базе (неточное соответствие, fuzzy match). Такое предложение может быть также подставлено в перевод, но переводчик будет должен внести необходимые изменения.
Большинство систем как минимум поддерживают создание новых баз данных на основе параллельных текстов (alignment), автоматическое извлечение терминологии из оригинальных и параллельных текстов, создание и применение использование ловарей пользователя.
Parallel Corpora:
лежат в основе современных систем статистического машинного перевода, где перевод генерируется на основе статистических моделей, параметры которых являются производными от анализа двуязычных корпусов текста (text corpora).
используются в современных системах гибридного перевода.
Corpus-based machine translation
В 1984 году
Макото Нагао (1936 г.р., японский специалист по компьютерным
наукам), руководя «Проектом Мю», направленным на перевод технических
документов, предложил откааться от пословного и грамматического анализа
в пользу обучения на похожих фразах по методу аналогии - не пытаться
каждый раз переводить заново, а конструировать перевод нового текста из
параллельных фрагментов (фразы, предложения, абзацы) из уже переведенных
текстов, вычисляя лексические отличия и заменяя нужные слова).
Если многое уже переведено -
нужно воспользоваться этим, а не повторять сделанное!
Такая модель
перевода позволяет обойтись без лингвистики
Корпусный подход в машинном переводе использует
Parallel Corpora (структурированную
совокупность (корпус) параллельных двуязычных (многоязычных)
текстов).
Современные системы статистического машинного перевода (SBMT)и машинного перевода,
основанного на примерах(EBMT), представляют собой варианты корпусного подхода.
Example-based machine translation (EBMT) — Машинный перевод на базе примеров, основан на принципе
на принципе параллельного двуязычного корпуса текстов, в котором в качестве примеров содержатся пары предложений. Чем больше в распоряжении текстов (примеров), тем лучше результат машинного перевода. Таким образом,
EBMT можно рассматривать как частный простой случай
CBMT.
П
араллельные корпуса
лежат в основе всех современных систем статистического машинного перевода, где перевод генерируется на основе статистических моделей, параметры которых являются производными от анализа двуязычных корпусов текста (text corpora).
Текстовые корпуса используются также
в современных системах
машинный перевод на
базе нейронных сетей (как обучающая база нейронной сети)
игибридного перевода.
Главным преимуществом систем машинного перевода с корпусным подходом является их самонастройка, т.е. они способны запоминать терминологию и даже стилистику фраз из текстов предыдущих переводов.
Параллельный корпус (parallel corpora)— это многоязычный корпус, то есть текст оригинала и его переводы на другие языки, причем эти тексты не просто лежат рядом друг с другом, а должны быть
выровнены:
отдельные фрагменты оригинала должны совпадать с соответствующими фрагментами перевода.
Именно это позволяет использовать параллельный корпус как инструмент
перевода и исследования.
В процессе перевода предложения могут разделяться, сливаться, удаляться, вставляться или менять последовательность.
В связи с этим выравнивание часто становится сложной задачей.
Качественное выравниваниенельзя
сделать полностью автоматически (т.к.
переводчик почти никогда не соблюдает границы предложения - одно предложение оригинала может быть переведено
несколькими предложениями, и наоборот).
Параллельный текст (битекст, Parallel text, Bitext)
— совмещенный документ, состоящий из версий соответствующего текста на исходном
языке и его переводом на
целевом языке.
Выравнивание параллельного текста — это идентификация соответствующих друг другу предложений в обеих половинах параллельного текста.
Выравнивание может проводиться на разных уровнях (главам, абзацев, предложений)
Битексты создаются с помощью специальных компьютерных программ - «инструментов для выравнивания» (alignment tool) или «инструментов для битекста» (bitext tool), которые позволяют автоматически выравнивать оригинальную версию текста и его перевод.
Подобные программы, как правило, приводят в соответствие два текста (оригинал и перевод) по каждому предложению.
ABBYY Aligner
- программа выравнивания параллельных текстов
- здесь
Собрание битекстов называется «битекстовой базой данных» или «двуязычным корпусом» и может использоваться в качестве справочника и для поиска нужных сочетаний.
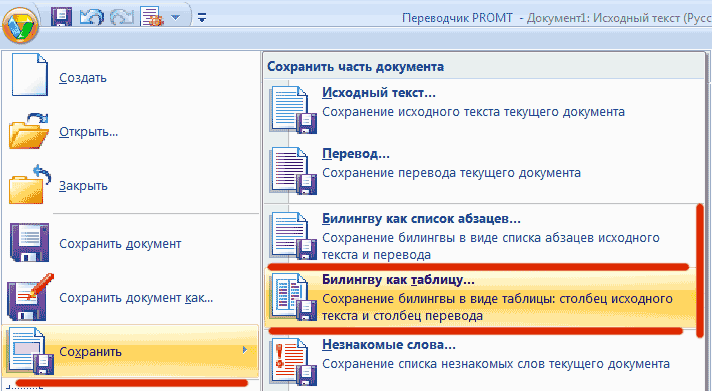
В
системе перевода PROMT (Rule-based
machine translation) результат перевода может быть
сохранен пользователем в виде билингвы (битекста) - как список
абзацев или как таблица:
К истории перевода на
параллельных текстах
Идея битекста принадлежит
Брайану Хэррису (Brian Harris), автору
статьи с изложением концепции в 1987 г.
Первые
переводческие работы с параллельными текстами были выполнены в конце 80-х – начале 90-х годов в рамках разработки систем статистического машинного перевода.
Э
ти работы вызвали критику со стороны традиционной лингвистики, так как в них отвергались подходы к машинному переводу, считавшиеся общепринятыми в течение десятков лет.
В частности,
игнорировалась структура предложений, а в качестве модели языка использовались
n-граммы (последовательности
n слов), на непригодность которых для целей моделирования языка
указывал в 50-е годы Н.А. Хомский.
Однако, статистический подход к машинному переводу привлек к себе внимание
возможностью снижения трудоемкости за счет отказа от ручного составления переводных словарей и грамматик: если в логике системы обнаруживается ошибка, ее устранение означает необходимость повторного запуска процедуры извлечения параметров из корпуса примеров, а не ручное переписывание этих ресурсов.
Первые системы перевода на основе примеров задумывались как несвязанные с конкретной парой языков – чтобы добавить новую пару языков в систему предполагалось всего лишь обработать соответствующий корпус текстов.
Первые методики машинного перевода на основе примеров послужили толчком для дальнейших исследований в области извлечения лингвистической информации из параллельных текстов.
Алгоритмы обучения на параллельных корпусах стали применяться в инструментахTranslation Memory, облегчающих труд человека-переводчика, в системах автоматической проверки переводов, выполненных вручную.
Предложено большое число подходов и конкретных алгоритмов. Некоторые из них специфичны для отдельных задач, другие применимы во всех областях обработки параллельных текстов.
Промежуточное место между переводной памятью и статистическим машинным переводом занимают системы машинного перевода на основе примеров (EBMT – example-based machine translation), составляющие законченные предложения из фрагментов, хранящихся в памяти.
Битекст и Translation Memory
Идея «битекста» имеет много общего с концепцией Translation Memory (памяти переводов), однако:
память переводов представляет собой базу данных, в которой сегменты текста (соответствующие друг другу предложения) расположены таким способом, при котором они не связаны с оригинальным контекстом, то есть оригинальная последовательность предложений теряется, а битекст сохраняет изначальную последовательность предложений.
битексты создаются в качестве справочного инструмента для консультаций специалистов-переводчиков, а не автоматизированных программ. Поэтому небольшие ошибки выравнивания или неточности, которые могут привести к сбоям в памяти переводов, для них не имеют значения.
Стандартным форматом для обмена базами данных памяти переводов между разными системами автоматизированного перевода является формат TMX - XML словарь Ассоциация отрасли локализации (Localisation Industries Association, LISA).
TMX позволяет сохранять оригинальный порядок предложений.
Конкордансы
Конкорданс (Concordance) – список всех употреблений заданного языкового выражения (слова, словочетания, предложения) в контексте.
Первый конкордансбыл создан к Вульгатев XIII векеХьюго де Сент-Шером(Hugues de Saint-Cher), которому помогали 500 монахов.Из-за огромного объёма работы в докомпьютерные времена конкордансы были созданы только для важнейших трудов – Библии, Вед, Корана, произведенияУ.Шекспира.
Тематические конкордансы – это списки тем, которые охватывает книга, с содержанием сути этих тем. Наиболее известный из таких конкордансов – Nave's Topical Bible.
Конкорданс(традиционное понимание) - список ключевых слов книги или текста, расположенных в алфавитном порядке, с их непосредственными контекстами.
«Опыт конкорданса к роману в стихах А. С. Пушкина «Евгений Онегин» с приложением текста романа» (М.: «ЛексЭст», 2003. – 592 с.).
Словарная статья Москва конкорданса к «Евгению Онегину» выглядит так:
МОСКВА, 5
Москва, России дочь любима, ...........................Эп.Г7.1 Как и надменная Москва. ..............................Г4XVII.14 Москва, я думал о тебе! .............................Г7XXXVI.12 Москва... как много в этом звуке .............Г7.XXXVI.12 Нет, не пошла Москва моя .......................Г7.XXXVII.8
Помимо конкорданса словоформ издание включает в себяпунктуационный конкорданс, обратный список словоформ, · поглавную карту романа, алфавитный указатель строф и др...
Конкорданс (в корпусной лингвистике)- список примеровупотреблений языкового выражения (слова, n-граммы), полученный в результате поиска по корпусу, со ссылками на источник.
Корпус-менеджер- программное обеспечение для корпуса, подсчитывает конкретные словоформы, группы словосочетаний, выводит результаты статистики, представляет в виде диаграммы..
Конкордансы широко используются в компьютерной лингвистикедля:
Многоязычные конкордансы– конкордансы, основанные на параллельных текстах.
В многоязычном конкордансе можно найти переводы определенных слов и словосочетаний на русский язык или с русского языка (правильность перевода не гарантирована!)
Примеры многоязычных конкордансов (TM) c веб-интерфейсом:
Конкордансеры - специальные программы составления конкордансов по некоторому корпусу текстов.
Конкордансерыпозволяют:
находить частоту той или иной языковой единицы по произвольному корпусу текстов,
получать список контекстов, в которых данная единица встретилась,
сортировать контексты по ключевому слову (в исходной форме) или по словоформе, по ближайшему контексту
Примеры конкордансеров:
TextSTAT - Simples Text Analyse Tool - работает с корпусами на разных языках, с использованием специального языка запросов (языка регулярных выражений)
Добрынина Ксения Сергеевна(каф. теории и практики перевода Оренбургский гос. пед. ун-т) О МЕТОДИКЕ РАБОТЫ НАД КОНКОРДАНСАМИ Раскрывается понятие "конкорданс", история его возникновения, структура, основные функции. Проводится противопоставление между словарями и конкордансами по нескольким шкалам. Рассматривается структура словарной статьи открытого конкорданса У. Шекспира.
(http://www.linguee.ru/?from=com) - онлайн-сервис, сочетающий в себе словарь, постоянно редактируемый лингвистами, и систему поиска переводов слов и выражений на базе 100 миллионов переведенных текстов.
Результаты поиска Linguee разделены на две части.
Слева наглядно представлены значения слова из словаря. Эти значения выверены нашими лингвистами.
Справа расположены примеры перевода для запрашиваемого значения. Эти примеры взяты из других источников. Они позволяют узнать, как то или иное выражение переводится в контексте.
Зубкова Е.В. (Пермский национальный исследовательский политехнический университет)
СИСТЕМА КОНТЕКСТУАЛЬНОГО ПОИСКА LINGUEE В ОБУЧЕНИИ ПИСЬМЕННОМУ ПЕРЕВОДУ В статье рассматриваются преимущества Linguee – системы контекстуального поиска по параллельным корпусам – для подготовки письменных переводчиков. Приводятся примеры заданий, формирующих необходимые профессиональные навыки. Ключевые слова: информационные технологии, параллельный корпус, банк речевых средств, семантика, сочетаемость
Параллельный корпус переводов «Слова о полку Игореве»
«Слово о полку Игореве» не имеет равных в количестве переводов на русский язык.
В базе корпуса переводов «Слова...»представлено более 90 переводов на современный русский язык и есть не менее трёх десятков текстов, которые пока не оцифрованы и не введены в корпус.
Существует порядка двухсот переводов «Слова...»на другие языки (причём среди переводчиков мы обнаруживаем ключевые для данной традиции фигуры: В.Набокова, Р. М. Рильке, Ю.Тувима, Ф.Супо, В.Ганки, И.Франко, Я.Купалы, Р.Нигмати).
М. Л. Гаспаров:
Каждый перевод, сколь бы он ни был превосходен, проецирует многомерную сложность подлинника на плоскость, делает оригинал упрощённым и представляет его односторонне.
Сопоставляя два или несколько переводов, читатель может получить как бы стереоскопическое изображение оригинала, увидеть его с разных сторон.
Выполняя перевод с одного языка на другой, переводчик принимает
многочисленные решения, заключающие в себе его знания обо всех уровнях межъязыковых соответствий – лексическом, грамматическом, идиоматическом и т.д.
Однако
переводчик не оставляет документацию или учебные пособия по выполненной работе.
Создание словарей, учебников, формализация принципов перевода до уровня автоматических систем выполняется отдельно от собственно перевода, и обычно не охватывает всего спектра задач, решаемых переводчиком в повседневной деятельности.
Системы статистической обработки параллельных текстов открывают
возможность проанализировать, формализовать и документировать мысль переводчика, воплощенную в паре оригинал-перевод,
может повысить эффективность использования переводческого труда.
Переводная лексикография и
корпусные технологии
В середине 90-х годов автоматическое построение переводных словарей по параллельным текстам стало рассматриваться как отдельная задача, и к настоящему времени установление лексических переводных соответствий по несвязанным текстам достигает точности на уровне слов выше
95%
Методы статистической обработки параллельных текстов применяются и в интересах исторической лексикографии, особенно в тех сферах, где существует переводная литература научного или технического характера.
Корпусная концепция перевода
Корпусная лингвистика (corpus linguistics) открыла новые направления и перспективы в области развития теории перевода
и его автоматизации.
Если
традиционная лингвистика в качестве основного инструмента перевода текста считает двуязычный словарь, то для корпусной лингвистики
главным условием перевода является понимание текста
на исходном языке, т.е. описание его значения (или смысла) с помощью определенных правил и трансформаций.
Перевод текста (концептуально)
- процедура перефразирования (трансформация воспроизводства) его значения в
переводящем языке.
Данная процедура предполагает те же операции кодификации значения, которые необходимы для понимания текста на родном языке.
Для корпусной семантики значение определенного сегмента текста в языке А есть его перевод на некий язык В.
Эмпирической базой служит здесь
параллельная корпора
-
множество текстов, существующих в разных языках и все их переводы на другие языки.
При этом значение понимается в строго лингвистическом смысле как парафраза.
Полное значение сегмента текста складывается из всех зафиксированных его интерпретаций в переводах на иные языки.
Таким образом, основной единицей анализа в корпусной
семантике является единица перевода, т.е. единица, которая в переводе на другой язык, трактуется как единое неделимое целое.
Единица перевода, как правило, соотносится с определенным тестовым сегментом или коллокацией языковых единиц в одноязычной корпоре.
Значение единицы перевода представляет собой ее переводной эквивалент в другом языке.
Является ли некая повторяемая в тексте единица - единицей перевода или она представляет собой некую последовательность слов, может быть очевидным только в процессе перевода.
Во-первых, то, что в одном языке является единицей перевода, может в другом языке быть простой последовательностью отдельных слов. И только сообщество переводчиков может решить относительно каждого конкретного языка, что следует считать единицей перевода. Анализ параллельной корпоры свидетельствует о том, что в общеупотребительном языке единица перевода, как правило, превышает объем отдельного слова.
Во-вторых, если значение единицы перевода - это ее переводное эквивалентное соответствие в
переводящем языке, то, значит, данная единица имеет столько же значений, сколько у нее разных эквивалентов (не синонимичных) в других языках.
Напр., английское слово sorrow имеет три эквивалента во французском переводе - chagrin, peine, tristess. Первые два обозначают чувство, связанное с определенной причиной, которое его вызывает, третье значение - чувство, которое не связано с определенной причиной. Эквивалентами в немецком языке будут - Traur (caused by loss), Kummer (caused by infelicitous event intense and usually of limited duration); Gram (caused by an infelicitous event, more a disposition of unlimited duration). Как видно, набор немецких значений не совпадает с французскими эквивалентами и, следовательно, все они будут рассматриваться как отдельные значения слова sorrow.
С помощью параллельной корпоры можно автоматически перевести около 98% текстов.
Количество неотмеченных единиц составляет только 1%.
Тем не менее корпора не является окончательным решением проблемы
машинного перевода, она может служить обычному переводчику в качестве дополнительного инструмента перевода в нахождении всех возможных эквивалентов и соответствий.
Мона Бейкер
(Mona Baker) профессор кафедры переводоведения и директор Центра
перевода и межкультурных исследований при Университете Манчестера в
Англии.
Внесла ущественный вклад в
корпусные методы перевода и корпусную концепцию.
Обычный переводчик видит в переводе нечто, не поддающееся каким бы то ни было общим закономерностям и правилам, текст, сопротивляющийся обработке и категоризации.
Исследователь видит в переводе фрагмент живой коммуникации, который отличается от оригинала не тем, что он как-то искажает источник, а тем, что он функционирует в других условиях порождения и восприятия.
Язык, и язык перевода в особенности, есть отражение не
столько лингвистических закономерностей и моделей, сколько феномен, характеризующийся признаками социальной, культурной, идеологической и когнитивной природы. С точки зрения корпусной лингвистики, перевод каждого отдельного текста есть проявление общих закономерностей, задаваемых структурой языка-источника или его жанровым своеобразием.
выборка текстов в ИЯ, переведенных с разных языков,
что дает возможность установить степень влияния языка-источника на модель текста в ИЯ,
выборка текстов в ПЯ, выполненных выдающимися переводчиками (английскими и американскими), что дает возможность исследовать индивидуальный стиль того или иного переводчика, его творческую манеру и т.д.,
выборка текстов, организованных в специальные корпусы: художественных текстов, публицистических, информационно-новостных и т.д.
Комплексы упражнений с паралельными корпусами
направлены преимущественно на сопоставление исходного и переводного текстов с целью идентификации тех или иных приемов перевода и оценки их эффективности.
В частности, учащимся предлагается дать подробный анализ лексического и грамматического наполнения оригинального текста в сопоставлении с текстом перевода.
Использование корпусов позволяет задействовать в обучении
большой объем материала, разнообразие стилей и жанров,
инструментарий быстрого анализа и поиска примеров на анализируемые конструкции и т.д.
Благодаря множеству встречающихся вариантов перевода итересующей лексической единицы или словосочетания, понижается тенденция приравнивания их какому-то одному эквиваленту на языке перевода.
Параллельный корпус также может внести ясность при выборе приемов перевода.
По некоторым данным около 50%, а на начальном этапе обучения до 80% времени перевода тратится на обращение к реферативной информации, например, словарям.
Параллельные корпусы позволяют значительно сократить эти временные затраты и предоставляют образцы профессионального перевода при изучении приемов и способов перевода.
Переводчик может найти в корпусе эквивалент интересующей лексической единицы, сделать вывод по какому принципу переводятся имена собственные, географические названия (транскрипция, транслитерация), идиомы, термины и т.п., соответствия тем или иным грамматическим или стилистическим явлениям и выделить способы их перевода, получив список контекстов для данного явления.
Параллельные корпуса текстов-образцов (в виде
базы данных) особенно полезны в том случае, когда переводчик работает со строго нормированными (конвенциональными) текстами, жанрово-стилистическое и стилистическое оформление таких текстов практически не допускает варьирования, отступления от определенных социокультурных норм (тексты деловой переписки, тексты-рецепты, тексты-прогнозы погоды, тексты-контракты и т.д).
переводческий коммуникативный (формирование умений выборочного и полного перевода и его редактирования).
Параллельные корпусы могут эффективно использоваться для разработки упражнений обоих предпереводческих комплексов, в частности, упражнений, направленных на:
формирование у учащихся языкового терминологического навыка в соответствии с выбранным профилем;
развитие дискурсивно-аналитического навыка дешифровки формальных признаков грамматических явлений в тексте,
обучение переводческим трансформациям, которые должны быть освоены старшеклассниками, на основании анализа их применения профессиональными переводчиками в отношении тех же лексических и грамматических единиц, которые используются в переводимом тексте.
Корпус дает возможность не только изучать стандартные лексические и синтаксические соответствия между двумя языками, но и анализировать путем сопоставления различных переводов принципы, лежащие в основе той или иной переводческой стратегии.