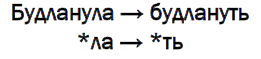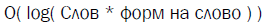Бытует мнение, что русская морфология у Яндекса реализована лучше чем у
Google. В этой статье я покажу, что дело обстоит ровным счетом
наоборот.
Эта статья адаптация моей статьи на SeoNews для Хабра
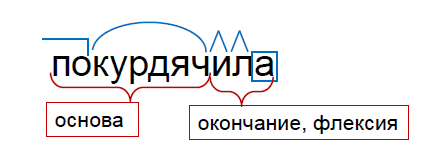
В русском языке несколько сотен тысяч слов, причем каждое из них может быть во множестве словоформ. Например, прилагательное может быть в 100 словоформах:

В итоге, если сохранять морфологический словарь «в лоб» нам нужно около 500 мб. 500.000(число слов) * 75(ср. число словоформ) * (10 (ср. длина слова) + 4 байта (на сохранение номера слова + 2 байта на сохранение номера словоформы)). Для ускорения необходимо держать все эти данные в памяти, а скорость критична в случае поисковой системы.
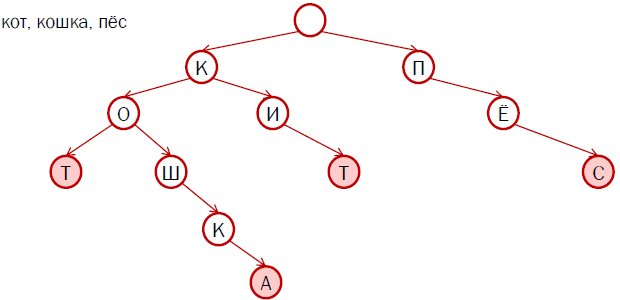
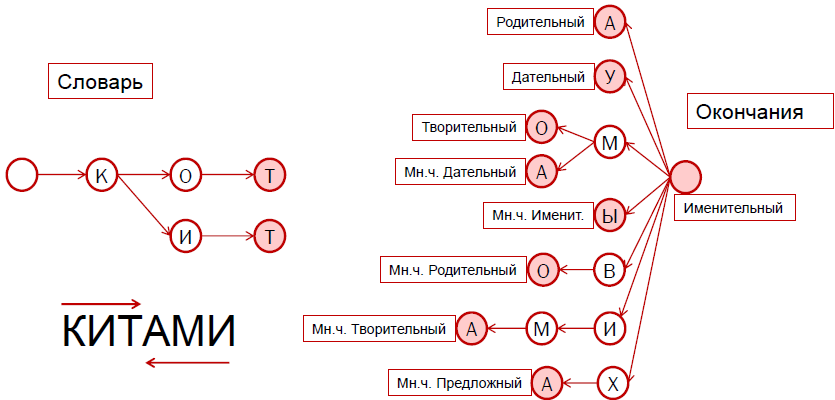
Существует «сжатый» вид. Многие слова имеют одинаковые окончания в одинаковой форме. Например, «великий» и «могучий». Нам нужно сохранить лишь начало слова («велик» и «могуч») и номер группы. В итоге нам понадобиться около 5мб. 500.000 * (8(ср. длина начала)+ 2(номер группы)). Однако, в этом случае база будет содержать артефакты.
Правил преобразования глаголов(делать) в причастия(делающий) не много. Поэтому в сжатой базе деепричастия и причастия считаются словоформами глагола, а не отдельными словами.
А вот правил преобразования глаголов в совершенный вид (делать->сделать, купить->покупать, искать->найти) бессчетное множество, поэтому для сжатой базы глаголы совершенного и несовершенного вида — разные слова.
Эти артефакты критичны только для поиска, в котором морфология используется, чтобы объединять словоформы.
Яндекс подсвечивает не только словоформы, но еще и синонимы. Однако, подсветку синонимов можно отключить при помощи оператора "+".
Связь совершенного и несовершенного вида глаголов в Яндексе организована через синонимы, а не через морфологию.
А вот связь глаголов и причастий — реализована через морфологию.
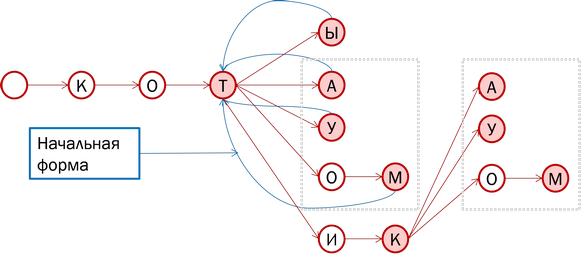
На этой картинке четко видны артефакты сжатия морфологического словаря. Другими словами Яндекс использует сжатие.
Быть может подсветка просто «отстает от мозгов». Однако, для высокочастотных запросов подсветка синонимом сама отключается. Это показывает, то что подсветка связана с мозгами в случае синонимов — не может же она просто так отключаться. Единственное объяснение этому — результатов в выдаче итак хватает и Яндекс экономит ресурсы не подключая поиск по синонимам.
Разница в выдаче хорошо наблюдается в запросах содержащих глагол в обоих видах и причастие. Например, «сделать клизму», «делать клизму» и «сделавший клизму», если набрать их в Яндекс и в Google.
Мы показали наличие артефактов морфологии Яндекс и то что они влияют на ранжирование, хотя, они могут не влиять на качество выдачи. Однако, мне удалось довольно быстро найти несколько исключений в Яндексе: купить и покупать, выщипывать и выщипать, отправлять и отправить склеены на уровне морфологии. Единственная гипотеза почему эти исключения появились — их добавили для улучшения выдачи. Следовательно, артефакты, как минимум, в частных случаях ухудшают выдачу.
Google
Google использует несжатую морфологию. По крайней мере, «артефакты сжатия» мне не удалось найти.
Единственное несоответствие формальной модели русского языка в Google — обычная (хороший) и превосходная (лучший) степени прилагательных разделены в морфологии. Вероятно они соединены как синонимы, однако, Google не подсвечивает синонимы.
Это не объясняется как артефакт сжатия, поскольку правил преобразования преобразования форм прилагательных не так много (красивый->красивейший, умный->умнейший) и ни база AOT.ru и ни словарь Зализняка не разделяет формы прилагательных.
Разделение прилагательных по степени, объясняется оптимизацией качества выдачи. Степень прилагательных изменяет их «окраску», делая их смысловую связь более похожей на синонимы, чем на словоформы. Например, запрос «прекрасные фото» по смыслу намного ближе к «красивые фото» чем «красивейшие фото».
Это совпадает с интуитивным представлением о языке. Я несколько раз встречался с тем, что «хороший» и «лучше» приводили в пример того, что Яндекс понимает синонимы.
Морфология в Яндексе писалась лет 10 назад, а тогда 500 мб. памяти для нескольких сотен серверов могли обойтись в копеечку. С тех пор память подешевела, но изменение морфологии привело бы к целому каскаду изменений в БД Яндекса. Поэтому, в Яндексе используется сжатый вид морфологии.
Google изначально английская поисковая система. В английском языке слова имеют всего несколько словоформ и в сжатии морфологии нет смысла. Видимо, поэтому, в русской морфологии Google не используется сжатие.
Морфология у Google организована «правильнее» и немного лучше чем у Яндекса. Ирония в том, что причина этому в английском происхождении Google.
Однако, морфология это лишь один из многих аспектов в выдаче. Сказать, что у Google лучше выдача чем у Яндекса только на основе морфологии, тоже самое что оценивать интеллект по высоте лба. Цель статьи была в развеивании убеждения о том, что морфология в Google организована хуже чем в Яндексе.
Эта статья адаптация моей статьи на SeoNews для Хабра
Русская морфология
В русском языке несколько сотен тысяч слов, причем каждое из них может быть во множестве словоформ. Например, прилагательное может быть в 100 словоформах:
В итоге, если сохранять морфологический словарь «в лоб» нам нужно около 500 мб. 500.000(число слов) * 75(ср. число словоформ) * (10 (ср. длина слова) + 4 байта (на сохранение номера слова + 2 байта на сохранение номера словоформы)). Для ускорения необходимо держать все эти данные в памяти, а скорость критична в случае поисковой системы.
Существует «сжатый» вид. Многие слова имеют одинаковые окончания в одинаковой форме. Например, «великий» и «могучий». Нам нужно сохранить лишь начало слова («велик» и «могуч») и номер группы. В итоге нам понадобиться около 5мб. 500.000 * (8(ср. длина начала)+ 2(номер группы)). Однако, в этом случае база будет содержать артефакты.
Артефакты
Правил преобразования глаголов(делать) в причастия(делающий) не много. Поэтому в сжатой базе деепричастия и причастия считаются словоформами глагола, а не отдельными словами.
А вот правил преобразования глаголов в совершенный вид (делать->сделать, купить->покупать, искать->найти) бессчетное множество, поэтому для сжатой базы глаголы совершенного и несовершенного вида — разные слова.
Эти артефакты критичны только для поиска, в котором морфология используется, чтобы объединять словоформы.
Яндекс
Яндекс подсвечивает не только словоформы, но еще и синонимы. Однако, подсветку синонимов можно отключить при помощи оператора "+".
Связь совершенного и несовершенного вида глаголов в Яндексе организована через синонимы, а не через морфологию.
А вот связь глаголов и причастий — реализована через морфологию.
На этой картинке четко видны артефакты сжатия морфологического словаря. Другими словами Яндекс использует сжатие.
Разница в выдаче
Быть может подсветка просто «отстает от мозгов». Однако, для высокочастотных запросов подсветка синонимом сама отключается. Это показывает, то что подсветка связана с мозгами в случае синонимов — не может же она просто так отключаться. Единственное объяснение этому — результатов в выдаче итак хватает и Яндекс экономит ресурсы не подключая поиск по синонимам.
Разница в выдаче хорошо наблюдается в запросах содержащих глагол в обоих видах и причастие. Например, «сделать клизму», «делать клизму» и «сделавший клизму», если набрать их в Яндекс и в Google.
Влияние на качество выдачи
Мы показали наличие артефактов морфологии Яндекс и то что они влияют на ранжирование, хотя, они могут не влиять на качество выдачи. Однако, мне удалось довольно быстро найти несколько исключений в Яндексе: купить и покупать, выщипывать и выщипать, отправлять и отправить склеены на уровне морфологии. Единственная гипотеза почему эти исключения появились — их добавили для улучшения выдачи. Следовательно, артефакты, как минимум, в частных случаях ухудшают выдачу.
Google использует несжатую морфологию. По крайней мере, «артефакты сжатия» мне не удалось найти.
Единственное несоответствие формальной модели русского языка в Google — обычная (хороший) и превосходная (лучший) степени прилагательных разделены в морфологии. Вероятно они соединены как синонимы, однако, Google не подсвечивает синонимы.
Это не объясняется как артефакт сжатия, поскольку правил преобразования преобразования форм прилагательных не так много (красивый->красивейший, умный->умнейший) и ни база AOT.ru и ни словарь Зализняка не разделяет формы прилагательных.
Разделение прилагательных по степени, объясняется оптимизацией качества выдачи. Степень прилагательных изменяет их «окраску», делая их смысловую связь более похожей на синонимы, чем на словоформы. Например, запрос «прекрасные фото» по смыслу намного ближе к «красивые фото» чем «красивейшие фото».
Это совпадает с интуитивным представлением о языке. Я несколько раз встречался с тем, что «хороший» и «лучше» приводили в пример того, что Яндекс понимает синонимы.
Почему так произошло
Морфология в Яндексе писалась лет 10 назад, а тогда 500 мб. памяти для нескольких сотен серверов могли обойтись в копеечку. С тех пор память подешевела, но изменение морфологии привело бы к целому каскаду изменений в БД Яндекса. Поэтому, в Яндексе используется сжатый вид морфологии.
Google изначально английская поисковая система. В английском языке слова имеют всего несколько словоформ и в сжатии морфологии нет смысла. Видимо, поэтому, в русской морфологии Google не используется сжатие.
Итого
Морфология у Google организована «правильнее» и немного лучше чем у Яндекса. Ирония в том, что причина этому в английском происхождении Google.
Однако, морфология это лишь один из многих аспектов в выдаче. Сказать, что у Google лучше выдача чем у Яндекса только на основе морфологии, тоже самое что оценивать интеллект по высоте лба. Цель статьи была в развеивании убеждения о том, что морфология в Google организована хуже чем в Яндексе.
Морфология и компьютерная лингвистика для самых маленьких
На Хабре уже был пост о
Технопарке, и даже рассказы о курсах (1, 2),
которые в нем проходят. Сегодня мы публикуем первую часть
мастер-класса, который для студентов Технопарка провел Андрей
Андрианов из ABBYY.
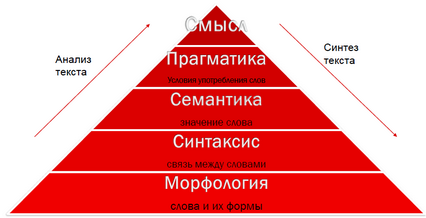
Для начала не лишним будет вспомнить, что такое морфология, а также какое отношение она имеет к лингвистике. За этим предлагаю пройти под кат к содержимому первого поста серии.
Многим из вас со школы знакомо предложение «Глокая куздра штеко будланула бокра и курдячит бокрёнка». Хотя мы не знаем, что скрывается за всеми словами этого предложения (за исключением союза «и»), мы можем предположить, что главное действующее лицо здесь куздра. Причем это не какая-то обычная куздра, а глокая. Что она сделала? Будланула. Как она это сделала? Штеко. Кого она будланула? Бокра. Кроме того, она совершает какие-то действия над бокрёнком.
Эту фразу придумал академик Лев Щерба, а академик Александр Потебня на примере этой фразы демонстрировал своим студентам, как определенную часть семантики мы можем извлечь из морфологии слова, из его словоизменения, из окончаний. Мы не знаем лексического значения слов — не понимаем, какие объекты названы — но мы можем уловить их грамматическое значение. Именно о грамматических значениях я бы хотел рассказать в этой статье.
Как только вы прочитали предложение: «Глокая куздра штеко будланула бокра и курдячит бокрёнка», вы сразу выловили подлежащее и два сказуемых — «будланула» и «курдячит». Разные части речи в разных языках могут по-разному образовывать предложения.
Увидев слово «будланула», даже не зная, что оно означает, вы уже можете его просклонять, проспрягать. Вам понятно, что инфинитив этого слова — «будлануть». Можно изменить род (будланул, будлануло), а можно поменять время (будланёт, будланёшь). То, как слова изменяются, в каких формах определяют то или иное грамматическое значение, изучает второй подраздел морфологии — словоизменение.
Встретив бокра и бокрёнка в одном предложении, вы сразу же себе представили, что бокрёнок – это детеныш бокра, как слонёнок и слон. Может быть, это просто мелкая копия большого бокра — ну, не выдался персонаж, например, ростом.
Мы часто образуем новые слова с помощью суффиксов (например, уменьшительно-ласкательных), для того чтобы поменять какие-то свойства объекта; можно даже изменить часть речи. Например, есть слово «лопата». От этого слова при желании можно образовать глагол: – лопатить. Носители языка быстро поймут его значение, а вот те, кто изучает русский язык как иностранный, будут долго разгадывать, что же это за слово, и почему его нет в словаре. Довольно часто мы образуем глаголы от свойств разных животных и наделяем эти глаголы какими-то свойствами.
Я уже упоминал, что у слова есть два значения – лексическое (что слово означает по словарю), и грамматическое (что слово означает в предложении). Какую-то семантику можно вынести и из грамматического значения. Например, слово «будланула». Очевидно, что это глагол. Из этого следует, что слово «будланула» означает действие. Кроме того, мы можем сказать, что это глагол в прошедшем времени, единственном числе, женского рода, совершенного вида. Все это дает вам дополнительную информацию. Например, в русском языке часто женский род ассоциируется с женским полом. Мы не можем объяснить, почему вилка женского рода, а стакан мужского, но почему девушка поднялась, а мальчик поднялся, нам понятно. И нам будет резать слух, если кто-то ошибется в выборе рода.
Ещё со школьной парты мы представляем грамматическое значение в виде набора граммем. Родительный падеж, прошедшее время, единственное число – все это разные граммемы. Граммемы можно сгруппировать по категориям. Именительный, родительный, дательный, винительный и предложный – это категория падежа. Одна и та же форма не может иметь две граммемы одной категории. Если мы говорим «будланула», то мы имеем в виду только граммему единственное число. В одной и той же форме «будланула» мы не можем зашифровать одновременно две формы глагола. Не может быть существительного одновременно и в именительном и в дательном падеже. Формы могут совпадать, как они часто совпадают у именительного и винительного падежа, однако их нужно различать. Это еще одна из задач морфологии.
Компьютерная лингвистика – это часть искусственного интеллекта. Цель компьютерной лингвистики – создание алгоритмов, с помощью которых машина будет понимать смысл текста или слов, которые поступают ей из различных источников ввода – звук, изображение, текстовая информация.
Области применения компьютерной лингвистики:
Наиболее широко компьютерная лингвистика применяется при обработке естественного языка. Обработка решает самые разные задачи, в числе которых составление словарей и автоматический перевод.
Другие технологии, связанные с обработкой естественного языка, также интересны как с теоретической, так и с практической точки зрения. Извлечение фактов из текста и автореферирование позволяют автоматически категоризировать большие объемы текста с большей точностью, чем методы машинного обучения. Системы управления знаниями, экспертные и вопросно-ответные системы в основе своей также имеют извлечение знаний из текста.
При распознавании текста применяются другие технологии. А в данном случае нас интересует, является слово словарным или нет. Когда распознается текст, мы часто имеем дело с нечеткостью изображения, и алгоритмы бинаризации, которая происходит перед распознаванием текста, не могут дать результат 100%. В связи с этим генерируется масса гипотез о том, что же там все-таки написано. Иногда невозможно отличить букву «н» от «м» или «н» от «к», и тогда в дело вступает компьютерная лингвистика, а если точнее – морфология. Морфология подсказывает, есть такое слово в языке или нет.
Распознавание речи работает схожим образом. Из набора звуков строятся гипотезы относительно конкретных букв, которые произносит человек. Возьмем слово «корова». Мы говорим «карова», а пишем «корова». Здесь важно понять, есть ли в русском языке слово «карова» или нет.
Синтез речи – еще одна интересная технология, которая может использоваться как самостоятельно, так и в рамках автоматического перевода. Это уже синтетическая задача: нам необходимо проанализировать текст на одном естественном языке, определить его смысл, и, исходя из полученного результата, сгенерировать текст на другом естественном языке.
На этом вводная часть закончена. В следующем посте поговорим о роли морфологии в компьютерной лингвистике.
В цикле будет 4 поста
Для начала не лишним будет вспомнить, что такое морфология, а также какое отношение она имеет к лингвистике. За этим предлагаю пройти под кат к содержимому первого поста серии.
Многим из вас со школы знакомо предложение «Глокая куздра штеко будланула бокра и курдячит бокрёнка». Хотя мы не знаем, что скрывается за всеми словами этого предложения (за исключением союза «и»), мы можем предположить, что главное действующее лицо здесь куздра. Причем это не какая-то обычная куздра, а глокая. Что она сделала? Будланула. Как она это сделала? Штеко. Кого она будланула? Бокра. Кроме того, она совершает какие-то действия над бокрёнком.
Эту фразу придумал академик Лев Щерба, а академик Александр Потебня на примере этой фразы демонстрировал своим студентам, как определенную часть семантики мы можем извлечь из морфологии слова, из его словоизменения, из окончаний. Мы не знаем лексического значения слов — не понимаем, какие объекты названы — но мы можем уловить их грамматическое значение. Именно о грамматических значениях я бы хотел рассказать в этой статье.
Морфология – это раздел лингвистики, который изучает 4 вещи
Части речи
Как только вы прочитали предложение: «Глокая куздра штеко будланула бокра и курдячит бокрёнка», вы сразу выловили подлежащее и два сказуемых — «будланула» и «курдячит». Разные части речи в разных языках могут по-разному образовывать предложения.
Словоизменение
Увидев слово «будланула», даже не зная, что оно означает, вы уже можете его просклонять, проспрягать. Вам понятно, что инфинитив этого слова — «будлануть». Можно изменить род (будланул, будлануло), а можно поменять время (будланёт, будланёшь). То, как слова изменяются, в каких формах определяют то или иное грамматическое значение, изучает второй подраздел морфологии — словоизменение.
Словообразование
Встретив бокра и бокрёнка в одном предложении, вы сразу же себе представили, что бокрёнок – это детеныш бокра, как слонёнок и слон. Может быть, это просто мелкая копия большого бокра — ну, не выдался персонаж, например, ростом.
Мы часто образуем новые слова с помощью суффиксов (например, уменьшительно-ласкательных), для того чтобы поменять какие-то свойства объекта; можно даже изменить часть речи. Например, есть слово «лопата». От этого слова при желании можно образовать глагол: – лопатить. Носители языка быстро поймут его значение, а вот те, кто изучает русский язык как иностранный, будут долго разгадывать, что же это за слово, и почему его нет в словаре. Довольно часто мы образуем глаголы от свойств разных животных и наделяем эти глаголы какими-то свойствами.
Грамматическое значение
Я уже упоминал, что у слова есть два значения – лексическое (что слово означает по словарю), и грамматическое (что слово означает в предложении). Какую-то семантику можно вынести и из грамматического значения. Например, слово «будланула». Очевидно, что это глагол. Из этого следует, что слово «будланула» означает действие. Кроме того, мы можем сказать, что это глагол в прошедшем времени, единственном числе, женского рода, совершенного вида. Все это дает вам дополнительную информацию. Например, в русском языке часто женский род ассоциируется с женским полом. Мы не можем объяснить, почему вилка женского рода, а стакан мужского, но почему девушка поднялась, а мальчик поднялся, нам понятно. И нам будет резать слух, если кто-то ошибется в выборе рода.
Ещё со школьной парты мы представляем грамматическое значение в виде набора граммем. Родительный падеж, прошедшее время, единственное число – все это разные граммемы. Граммемы можно сгруппировать по категориям. Именительный, родительный, дательный, винительный и предложный – это категория падежа. Одна и та же форма не может иметь две граммемы одной категории. Если мы говорим «будланула», то мы имеем в виду только граммему единственное число. В одной и той же форме «будланула» мы не можем зашифровать одновременно две формы глагола. Не может быть существительного одновременно и в именительном и в дательном падеже. Формы могут совпадать, как они часто совпадают у именительного и винительного падежа, однако их нужно различать. Это еще одна из задач морфологии.
Прикладные задачи лингвистики
Компьютерная лингвистика – это часть искусственного интеллекта. Цель компьютерной лингвистики – создание алгоритмов, с помощью которых машина будет понимать смысл текста или слов, которые поступают ей из различных источников ввода – звук, изображение, текстовая информация.
Области применения компьютерной лингвистики:
-
Обработка естественного языка
- Словари и автоматический перевод
- Извлечение фактов из текста и автореферирование
- Системы управления знаниями, экспертные системы
- Вопросно-ответные системы
- Распознавание текста (OCR)
- Распознавание речи (ASR)
- Синтез речи
Обработка естественного языка
Наиболее широко компьютерная лингвистика применяется при обработке естественного языка. Обработка решает самые разные задачи, в числе которых составление словарей и автоматический перевод.
Другие технологии, связанные с обработкой естественного языка, также интересны как с теоретической, так и с практической точки зрения. Извлечение фактов из текста и автореферирование позволяют автоматически категоризировать большие объемы текста с большей точностью, чем методы машинного обучения. Системы управления знаниями, экспертные и вопросно-ответные системы в основе своей также имеют извлечение знаний из текста.
Распознавание текста (OCR)
При распознавании текста применяются другие технологии. А в данном случае нас интересует, является слово словарным или нет. Когда распознается текст, мы часто имеем дело с нечеткостью изображения, и алгоритмы бинаризации, которая происходит перед распознаванием текста, не могут дать результат 100%. В связи с этим генерируется масса гипотез о том, что же там все-таки написано. Иногда невозможно отличить букву «н» от «м» или «н» от «к», и тогда в дело вступает компьютерная лингвистика, а если точнее – морфология. Морфология подсказывает, есть такое слово в языке или нет.
Распознавание речи (ASR)
Распознавание речи работает схожим образом. Из набора звуков строятся гипотезы относительно конкретных букв, которые произносит человек. Возьмем слово «корова». Мы говорим «карова», а пишем «корова». Здесь важно понять, есть ли в русском языке слово «карова» или нет.
Синтез речи
Синтез речи – еще одна интересная технология, которая может использоваться как самостоятельно, так и в рамках автоматического перевода. Это уже синтетическая задача: нам необходимо проанализировать текст на одном естественном языке, определить его смысл, и, исходя из полученного результата, сгенерировать текст на другом естественном языке.
На этом вводная часть закончена. В следующем посте поговорим о роли морфологии в компьютерной лингвистике.