|
Определение
словарного запаса |
|
Статистические методы в языкознании
- методы использования счета и измерений для изучения языка
и речи.
Объектом применения
статистических методов обычно является письменный текст (в
первую очередь его лексический состав). |
|
Вокабула
(от лат. vocabulum «слово, имя, название»):
-
основное определяющее
слово (словосочетание) в заголовке словарной статьи,
-
отдельно взятое слово для
заучивания наизусть при первоначальном обучении языкам.
Вокабулярий
(от лат. vocabularium «лексика»):
-
список вокабул в словарях,
-
совокупность слов в
тексте, которые не входят в словарный запас читателя
(являются непонятными),
-
словарный запас человека.
Словарный запас
(лексикон) — набор слов, которыми владеет человек.
Активный словарный
запас — набор
слов, которые человек использует в устной речи и письме.
Пассивный словарный
запас
— набор слов, которые
человек узнаёт при чтении или на слух, но не использует их
сам.
Пополнение словарного запаса —
одна из основных составляющих обучения иностранному языку.
Эффективное пополнение словарного запаса учитывает:
-
наличный словарный запас (лексикон),
-
частотность слов для запоминания
(walk
vs perambulate);
-
простоту слов для запоминания
(process vs
outgrowth);
-
цели пополнения словарного запаса (специфичность
лексики).
Для эффективного изучения
новых слов и поддержания в памяти старых важно уметь
определять словарный запас (лексикон) ученика.
Традиционный
подход в определении словарного запаса заключается в интуитивном определении объема
лексикона учителем на основе общения и тестов. Такой подход,
однако, полностью опирается на опыт и квалификацию
преподавателя и не может быть объективно проконтролирован.
|
WordMash
|
WordMash инструмент
определения словарного запаса
(от компании Skyeng)
WordMash
основан на предположении, что из всех слов
языка можно составить упорядоченный по сложности список:
-
в начале
списка идут «простые слова», например те, что выучивают
дети в самом начале жизни: «мама», «папа», «хороший»,
«плохой» и т.д.
-
конце списка находятся «сложные» слова —
профессиональная лексика, архаизмы, локальные наречия и т.д.
-
в упрощенном случае предполагается, что если человек знает
некоторое слово в этом упорядоченном списке, то он знает и
все предыдущие слова в этом списке; если же человек не знает
некоторое слово, то и последующие слова он тоже не знает.
В идеальном случае для оценки словарного
запаса человека требуется определить положение границы его
знания: номер последнего слова, которое он знает.
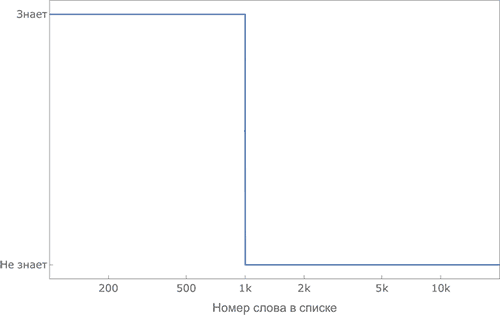
В реальности
изучение
слов происходит не по списку, не по
порядку,
лексикон разных людей отличается.
Чтобы использовать усредненное упорядочивание слов (без
четкой границы), слова в ранжированном по сложности списке
разбиваются на интервалы (например, по 100 слов) и для
каждого интервала определяется процент слов из этого
интервала, который ученик знает. В результате получается
относительно гладкая кривая, с помощью графика которой можно
увидеть, с какой вероятностью ученик знает слово. Роль
аналога границы (характеризующей численным образом словарный
запас ученика) играет медиана функции распределения (такие
номера слов, что количество неизвестных слов до них равно
количеству известных после.
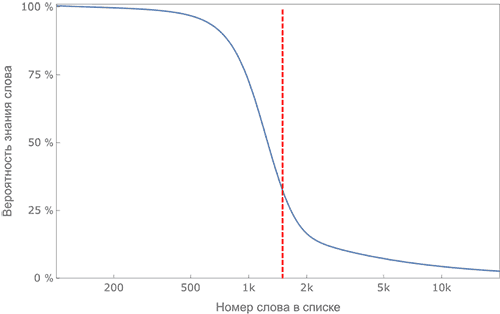
Красная
линия - медиана
распределения (зависимостиь вероятности знания слова от
его номера)
Проблема: подготовить упорядоченный по
сложности список слов... |
Анализ частотности по BNC
|
Эмпирически установлено:
Следствие:
|
Лингвистический корпус:
-
репрезентативная (соответствующая
представляемой функционирования
языка) совокупность текстов,
-
собранных в соответствии с определёнными
принципами (соответствующими задаче),
-
размеченных (снабженных аннотациями),
-
обеспеченных специализированной поисковой
системой.
|
Для
WordMash
был проведен частотный анализ
тех подкорпусов Британского
Национального Корпуса (British National Corpus), в
которых представлены:
-
письменные тексты (книги,
статьи, документы),
-
разговорные (транскрипции
бесед, записей, фильмов)
-
цитаты из докладов,
обращений и выступлений.
Эти три подкорпуса различаясь
объемами, обладают одинаковой важностью для анализа живого
языка, поэтому при подсчете частотности их «вес» в общем
результате был уравнен.
Далее были рассчитаны
частотности и проведена нормализация по подкорпусам
(усреднены три результата).
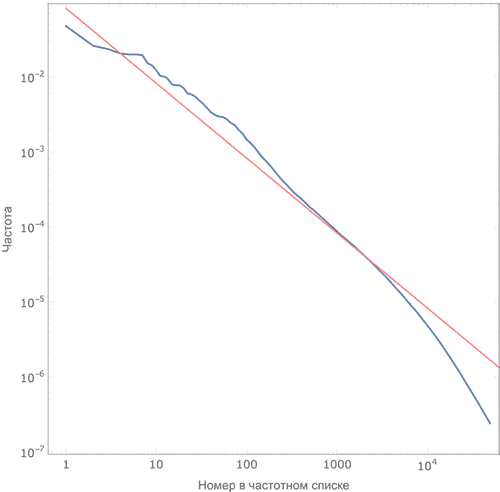
Фрагмент
полученного списка и график зависимости частотности от
номера слова:
|
Номер слова |
Слово |
Частотность (на 1 000 000
000 слов) |
|
1 |
the |
61 674 367 |
|
2 |
be |
35 206 532 |
|
470 |
leader |
2 420 806 |
|
5
175 |
millennium |
11 433 |
|
49
818 |
negligibly |
67 |
График зависимости
частотности слова от его номера в списке хорошо описывается законом
Ципфа (красная прямая):
 |
Ранжирование списка
|
Соответствие частотности слов в корпусе текстов и
относительной упорядоченностью лексикона справедливо для
группы активных читателей и создателей текстов (грамотных
носителей языка) и проблематично для иноязычных учащихся.
Например, проблемой являются слова схожей формы в английском
и русском языках, позволяющие угадать значение незнакомого
слова , что положительно влияет только на размер пассивного
словаря(если это не «ложный
друг переводчика»).
Для сортировки словаря, основанной на субъективном
восприятии сложности отдельных лексических единиц реальными
людьми из двух предложенных системой
WordMash
слов пользователь выбирает наиболее, на его взгляд, простое.
При этом для упорядочивания списка применяется система рейтингов
Эло (чем выше рейтинг – тем
сложнее его поднимать и легче потерять).
Начальный рейтинг рассчитывался как логарифм частотности:
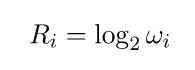
После сравнения i-го слова с j-ым:
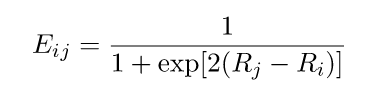
Вычисляется новый рейтинг слова:
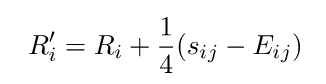
Подобная методика при некотором размере базы пользователей
оказалась устойчива к шуму результатов (достоверность
рейтинга слов, полученного на основе ответов растущего
количества участников программы повышалась).
Была построена метрика качества сортировки: количество
перестановок, которое нужно совершить в списке слов, чтобы
кривая стала монотонной (чем меньше перестановок, тем
лучше).
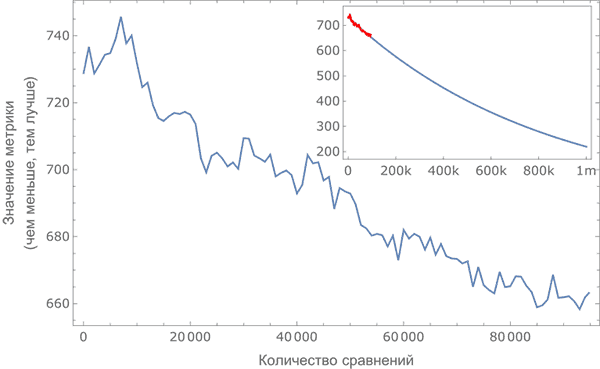
На графике показана зависимость метрики от количества
проведенных сравнений. |
Использование
WordMash
|
Результаты работы инструмента WordMash используются для
подбора учебных материалов на основе определения объема
лексикона ученика:
-
на первом этапе (словарный опрос, логарифмически
равномерно покрывающий весь диапазон ранжированного
списка) определяется приблизительная граница медианным
методом.
-
на втором этапе граница уточняется на основе опроса
вокабул в окрестности приблизительной границы.
График роста объема словарного запаса, служит мотивирующим
фактором и показателем эффективности обучения.
На сонове инструментария определения словарного запаса
ученика созданы сервисы
Прототип инструмента Wordset Generator с результатом
обработки «Автостопом по Галактике» Дугласа Адамса
|
WordSet Generator
|
Для заучивания слов,
имеющих непосредственное отношение к поставленной задаче (встречающиеся именно
в заданном контексте)
Skyeng предлагает использует инструмент
Wordset Generator, создающий
упорядоченный список слов для запоминания из текста или набора текстов, которые
хочет прочитать ученик.
Wordset Generator
создан на основе инструментов ранжирования слов и определения словарного
запаса конкретного ученика.
Алгоритм
Wordset Generator:
-
составляется список всех использованных в тексте слов, с
указанием количества вхождений.
-
отсекаются (отправляются в отдельный список) все слова,
отсутствующие в нашем словаре. Как правило, это выдуманные
автором слова, имена, названия.
-
определяется «тематичность» каждого слова в списке, для
чего сравнивается частота вхождения слова в анализируемом
тексте с частотой вхождения этого слова в корпусе текстов
английского языка (его распространенности). Число означает,
во сколько раз чаще слово присутствует в анализируемом
тексте.
-
проводится полуавтоматическая подстройка списка под
конкретные нужды (с помощью заданных параметров или
перемещения ползунков).
-
задается уровень знания ученика («сложность»). При этом
отсекаются слова, с которыми ученик, скорее всего, уже
знаком.
-
выбираются веса тематичности и локальной частотности.
Тематичность важна в том случае, если мы готовим список
профессиональных терминов для использования по работе. В
случае анализа художественной литературы важнее частотность.
-
вычисляется вероятность того, что
конкретное слово в данном тексте является именем собственным
(в веб-версии такие слова подсвечиваются разной
интенсивности красным цветом). Ползунок «Имена собственные»
позволяет удалять такие слова в соответствии с заданной
вероятностью; в большинстве случаев здесь требуется ручное
вмешательство, особенно если речь идет о художественной
литературе.
Применение
Wordset Generator:
-
Наиболее очевидное применение инструмента Wordset Generator
для учащихся – создание списков слов для заучивания
под конкретные книги, фильмы, события, терминосистемы.
-
Анализ художественной литературы помогает готовить рекомендационные списки для каждого уровня учеников.
Чем меньше «сложных» слов выдает программа – тем доступнее
текст для учащихся, находящихся в середине пути изучения
языка. Для высоких же уровней такие тексты не представляют
трудности и не несут образовательной пользы – им надо
подыскивать более богатые лексически произведения. Например,
в произвольно выбранном детективе Агаты Кристи (After the
Funeral) «сложных» слов менее 300; в «Улиссе»
Джеймса Джойса - больше 2000.
От учителя, использующего
Wordset Generator,
требуется:
-
подготовить корпус текстов
(современных и "живых"), из
которых будут извлекаться слова.
-
настроить (ручным
перетаскиванием ползунков) правильные параметры
сложности, тематичности и проч.
-
обработка полученного набора
слов (выяснение точного значения слова в данном
контексте и др.)
-
подбор ко всем словам
смысловых иллюстраций...
Прототип
Wordset Generator: http://tools.skyeng.ru/sandbox/wordset-generator/
(ограничение на размер
текста — до 80 000 знаков, включая пробелы и переносы
строк).
Это
внутренний инструмент
Skyeng, не предназначенный для широкой
публики (потому и интерфейс его аскетичен).
По умолчанию
предложен результат парсинга первой главы “Автостопом по Галактике” Адамса.
Полученные
слова можно добавить в приложение вручную с помощью встроенного словаря.
Можно создать собственный список слов
(экспортировать
его в CSV).
Приложение Aword
(загрузить приложение для Android и iOS можно бесплатно, но работает Aword по
принципу подписки: первые три дня – тестовый режим и ... платить)
После
пополнения словарного запаса можно начать общаться с учителем по Skype с
помощью
сервиса.
|
Открываем доступ к инструменту для составления списков английских слов из
фильмов, книг и статей
|
Каждый язык, диалект, наречие, сленг на нашей планете сам по себе уникален и
интересен. И каждый из перечисленных вариантов имеет свой определённый набор
слов, которыми наполняются словари и головы студентов. Но прежде чем начать
говорить непосредственно об английском языке, хотелось бы начать с нашего
родного – родного для меня и для вас, читающих эту статью, — и великого русского
языка.
Ответьте сами себе на вопрос: сколько слов родного языка вы знаете и используете
абсолютно свободно в вашей речи? Как вы будете их считать? Первый способ – берём
самый большой словарь и начинаем ставить галочки напротив тех слов, которые нам
знакомы. Проходит 3 недели, когда мы доходим до слов «яшма», «ящик», «ящур» (кто
что знает), снова открываем первую страницу и начинаем считать. Ещё через 3
недели каждый выйдет на определённую огромную цифру слов и подумает, для чего он
проделал все эти манипуляции. Для чего, я расскажу чуть позже. Второй способ –
не берём словарь, ничего не считаем, потому что нам, лично, это не нужно и у нас
веские аргументы. Почему это всё-таки нужно, я тоже поведаю в этой статье. И
наконец-то третий способ – находим в интернете тест на определение активного или
пассивного словарного запаса, проходим его и точно знаем, в каких пределах
варьируется доступное нашему сознанию количество слов. Но и тут возникает
проблема: как правильно выбрать тест, ведь их десятки, что такое пассивный и
активный запасы слов и т.д. Итак, обратимся к теории и разберёмся всё-таки, что
же такое словарный запас и почему я решила сегодня поговорить именно об этом.
Говоря простым ненаучным языком, словарный запас – это тот определённый набор
слов, которым владеет определённый человек. Именно владеет, а не просто «слышал
звон, не знаю где он». Т.е. понимает значение того или иного слова, умеет
применить его в устной и письменной речи, воспринимает его при живом общении.
Весь в целом словарный запас конкретного человека можно разделить на активный и
пассивный. Активный словарный запас – это набор слов, которые он использует в
устной и письменной речи, когда он является источником этой речи. Пассивный же
словарный запас – это набор тех слов, которые человек распознаёт, читая ту или
иную литературу, или услышав их в устной речи, но сам источником этих слов не
является, т.е. не использует в своей собственной речи. Данное разграничение
применимо как для родного, так и для изучаемого вами в качестве иностранного
языка, так как в обоих случаях есть те слова, которыми пользуемся лично мы с
вами, и те, значения которых мы распознаём нашей памятью.
Если говорить о составе языка в целом, то русский язык практически невозможно
подсчитать, так как он слишком богат и разнообразен, и по разным источникам в
нём насчитывается от 2,5 до 4,5 миллионов слов и словарных единиц. В английском
языке всё намного проще, последний раз официальный подсчёт проводили в 1999 году,
и по его данным в этом языке насчитывается чуть больше одного миллиона слов и
словарных единиц. Поэтому может смело радоваться тому, что изучаем именно
английский язык, ведь миллион – это не так уж много. А если говорить серьёзно,
то из этого «чуть больше миллиона» в обыкновенной повседневной речи даже самый
образованный человек использует не более 20-30 тысяч слов и словарных единиц (и
не более 50 тысяч хранится на жёстких дисках его памяти) – и при том, что
английский для него родной. Если же мы говорим об английском языке, как об
иностранном, изучаемом нами, то самые высокие показатели для активного
словарного запаса составляют 8-10 тысяч слов, а для пассивного до 15 тысяч. Т.е.
вы видите, что показатели не так уж велики и страшны, как может показаться на
первый взгляд.
Теперь стоит поговорить о том, как же подсчитать ту самую заветную цифру, на
которую вы выходите с вашим объёмом знаний. Существует множество различных
способов, тестов, подсчётов. Я предлагаю вам обратить внимание на два из них, и
я аргументирую почему выбрала именно эти варианты. Первый из этих вариантов
подсчёта вы можете найти на сайте http://www.testyourvocab.com, который посвящен
совместному американско-бразильскому исследовательскому проекту, направленному
именно на подсчёт слов вашего пассивного словарного запаса. Построен он очень
просто – вам лишь нужно отмечать те слова, значение которых (хотя бы одно) вам
достоверно известно. Единственная проблема в том, сможете ли вы быть честны сами
с собой и действительно правдиво выбирать узнанные вами слова. В конце система
сама считает ваш результат и выдаёт примерное значение +/- 500 слов. Второй
вариант подсчёта слов позволяет сделать это по уровням и конкретно увидеть, в
чём же ваши упущения. Этот вариант подсчёта вы можете найти на сайте http://www.er.uqam.ca.
Данный тест позволит вам пройтись по уровням и точно определить, где мы ставим
точку и продолжаем обучение. Каждая версия теста состоит из 6 уровней, и
проходить их необходимо, начиная с самого первого, даже если вы уверены, что
знаете гораздо больше. Результат даст вам возможность понять, каков ваш
словарный запас и на что стоит обратить своё внимание.
Но для чего же считать? Вот вопрос, который многих из вас сейчас заботит. Ведь
цифры никому не важны, думаете вы. Но это не так. Во-первых, такой подсчёт
позволяет объективно оценить ваш уровень знания лексики, во-вторых, при
прохождении определённых тестирований британских и американских школ, вас буду
просить указать результаты подсчёта словарного запаса. И я никому из вас не
советую делать это навскидку, так как после выполнения тестирования может
случится конфуз несоответствия указанных вами данных и результатов теста.
Поэтому знать свой словарный запас (особенно активный), не просто полезно, но в
некоторых случаях необходимо.
Далее я хотела бы привести примерную градацию объёмов словарного запаса:
словарный запас в размере 350-700 слов – активный словарный запас необходимый
для начального (базового) уровня владения иностранным языком.
словарный запас в размере 700-1300 слов – достаточный для того, чтобы
объясниться (если он активный для вас); и для чтения на базовом уровне (если это
ваш пассивный словарный запас).
словарный запас в размере 1300-2800 слов – активный словарный запас, достаточный
для бытового повседневного общения; в случае, если он пассивный, достаточен для
беглого чтения.
словарный запас в размере 2800-5500 слов – вполне пригоден для свободного чтения
прессы или научной литературы.
словарный запас в размере до 8000 слов – достаточно для нормального полноценного
общения человека, изучающего английский как иностранный, что позволит понимать
практически любую литературу, ТВ-программы и прессу.
словарный запас в размере до 13 000 – активный словарный запас человека с
высоким уровнем образования, который изучает английский как иностранный язык.
Но даже если вы прошли данное тестирование успешно, следует помнить, что только
слова, зафиксированные в вашей памяти, не дадут вам возможности свободно
общаться по-английски, так как у этого навыка множество других аспектов. Однако,
овладев 2000 правильно подобранных часто используемых слов, при наличии
определенной грамматической базы и практики, вы без труда сможете общаться на
великолепном языке Туманного Альбиона.
|
Нивхи и числительные
|
Нивхи – таинственные носители древнего языка на краю дальневосточной России, на
Сахалине и Нижнем Амуре. Слово нивх является, во-первых, этнонимом этого народа,
во-вторых, выражением понятия человек, в-третьих, во множественном числе народ,
а в начале начал могло означать я есмь.
Лев Я́ковлевич Ште́рнберг (1861-1927) — российский и советский этнограф,
член-корреспондент АН СССР по отделу палеоазиатских народов (1924)[2]. Профессор
Петроградского университета (1918).
Профессор Лев Яковлевич Штернберг с 1889 до 1898 г. отбывал ссылку как
политзаключенный на острове Сахалин.
Там изучал нивхов, нашел их свободолюбивыми дикарями, полуоседлыми рыболовами,
охотниками, обитающими зимой в землянках. Установил, что род является их
единственной и главной общественной организацией. Не знают ни патриархальной
власти, ни других элементов насилия. Глубоко и безусловно верят в
сверхъестественную силу шаманов.
″Самой замечательной особенностью этого таинственного племени, привлекающей к
нему интерес одинаково как этнографа, так и лингвиста, - это его язык.″
ЕРУХИМ АБРАМОВИЧ КРЕЙНОВИЧ (1906-1985) - исследователь палеосибирских языков, д.
фил. н.
НИВХСКИЙ ЯЗЫК
ЗАГАДКА ДРЕВНЕГО ЯЗЫКА
Количественные числительные нивхского языка представляют собой уникальную,
предметную, конкретную систему счета, уходящую корнями в неолит.
До 30 разрядов числительных для выражения конкретных количеств, но нет разряда
для счета понятий с абстрактным значением.
Все они ориентированы на счет единичных предметов или групы предметов по
внешнему сходству.
Эти числительные располагаются перед существительными.
I. Числительные для счета предметов разной формы:
1./ мелкие круглые предметы: ник ″один″, мик ″два″, тех ″три″, ных ″четыре″,
тхох ″пять″; (наконечники, стрелы, пули, дроби, топоры, зубы, клубни, сараны,
кедровые орехи, ягоды, икринки, яйца, пальцы, кулаки, украшения на женских
плат6ьях, камешки, звезды, монеты, деньги, пуговицы, бусинки, проруби, мячи,
кисеты, бутылки, желудки тюленей и т.д.);
2./ длинные предметы: нех 'один', мех 'два', тех 'три', ных 'четыре', тхох
'пять' (деревья, палки, шестты, кусты, растения, стебли, травы, корни, юколы,
морская капуста, дороги, тропинки, хребты гор, ручьи, ребра, кишки, волосы,
иголки, гвозди, нитки, ремни, спички и т.д.)
3/ плоские предметы: ньрах 'один', мрах 'два', тьрах 'три', нрых 'четыре',
тхорах 'пять' (листья табака, бумага, коры дерева, листья деревьев и растений,
одеяла, покрывала, паруса, рубашки, халаты и другие тонкие и плоские предметы);
4/ парные предметы: ньваск 'один', мевск 'два', тьфаск 'три', нвыск 'четыре',
тховск 'пять' (глаза, уши, лица, руки, ноги, лыжи, весла, берестовые чумашки для
воды, инструменты для свивания веревок, тормозные палки, следы ног, нарт,
руковицы, штаны, наголенники, обуви, серьги, берега реки, ласты и т. д.);
II. Живые существа, семьи, поколения
1/ люди, лесные люди-духи, морские люди-духи ньеннг 'один', меннг 'два', тьақр
'три', нырнг 'четыре', тхорнг 'пять';
2/ семьи: ньиршнгк 'один', миршнгк 'два', тьершнгк 'три', ныршнгк 'четыре',
тхоршнгк 'пять';
3/ поколения: ньесвах 'один', месвах 'два', тьесвах 'три', нысвах 'четыре',
тхосвах 'пять';
4/ животные, рыбы, птицы, змеи, насекомые, злые духи: ньан 'один', мар 'два',
тьақр 'три', ныр 'четыре', тхор 'пять'.
III. Числительные для счета рыболовных снастей, предметов для охоты на тюленей:
1/ сети: нео 'один', мео 'два', тео 'три', ныо 'четыре', тхоу 'пять';
2/ неводы: ньвор 'один', мевор 'два', тьфор 'три', нвыр 'четыре', тх офр 'пять';
3/ неводные полоса: ньершқи 'один', мершқи 'два', тьершқи 'три', ныршқи
'четыре', тхоршқи 'пять";
4/ ячейки сетей: ниу 'один', миу 'два', теу 'три', ныу 'четыре', тхоу 'пять';
5/ шесты для рукоятки гарпунов: ньла 'один', мел 'два', тьла 'три', нлы
'четыре', тхола 'пять″
6/ снасти на тюленей и калугу: ньфат 'один', мефат 'два', тьфат 'три', нфыт
'четыре', тхофат 'пять';
7/ место (например, в скольких местах ставили капканы): ньавр 'один', мевр
'два', тьавр 'три', нывр 'четыре', thoвр 'пять'.
IV. Числительные для счета рыбных запасов и шестов для нанизывания юколы:
1/. связки юкол для людей: ньар 'один', мер 'два', тьар 'три', ныр 'четыре',
тхор 'пять';
2/. связки корюшки для людей: ньнгақ 'один', менгақ 'два', тьнгақ 'три', нырнгақ
'четыре', тхорнгақ 'пять';
3/. связки корма для собак: ньхуви 'один', миγви 'два', тьхови 'три', ныγви
'четыре', тхуγви 'пять';
4/. шесты для сушки: неск 'один', меск 'два', тьеск 'три', ныск 'четыре', тхоск
'пять'.
V. Числительные для счета средств передвижения:
1/: лодки: ним 'один', мим 'два', тем 'три', ным 'четыре', тхом 'пять';
2/. нарты: нирш 'один', мирш 'два', терш 'три', нырш 'четыре', тхорш 'пять'.
VI. Числительные для счета разных материалов:
1/. доски: неть 'один', меть 'два', теть 'три', ныть 'четыре', тхоть 'пять';
2/. веревочные сплетения: ньлай 'один', мелай 'два', тьлай 'три', нылай
'четыре', тхолай 'пять';
3/. пачки травы для обуви: ньарвс 'один', мервс 'два', тьарвш 'три', нырвс
'четыре', тхорвс 'пять'.
VII. Числительные для измерения:
1/. сажени: ньа 'один', ме 'два', тьа 'три', ны 'четыре, тхоа 'пять';
2/. ручные четверти: ньма 'один', мема 'два', тьма 'три', нмы 'четыре', тхома
'пять';
3/. толщина и длина медвежьего и тюленьего сала: ниух 'один', миух 'два', теух
'три', ныух 'четыре', чхалмавазрш 'ладонь';
4/. дни, проведенные в пути: них 'один', мих 'два', тех 'три', ных 'четыре',
тхох 'пять'.
Не только абстрактных чисел нет, нет и порядковых числительных.
Причина неимения абстрактных чисел скрывается в абсолютной конкретизации счета,
в несуществовании отвлеченых понятий.
Так как там, где всё воспринимается живым, одушевленным и дееспособным, нет
места отвлеченным понятиям.
Очередность или последовательность выражается по пространственному расположению
чего-либо.
Следовательно, третий дом, нивх скажет так: кеқрыхпхидыф тьый эрқпхидыф тьый
эрқпхидыф ″на верхнем конце деревни дом, за ним еще дом, за тем домом еще дом″.
|
е мнение
|
https://ru.wikipedia.org/wiki/Системы_наименования_чисел
http://numword.ru/
NumWord.ru — сервис для перевода любых чисел в прописную форму на русском,
английском, немецком, французском и украинском языках
https://ru.wikipedia.org/wiki/Именные_названия_степеней_тысячи
http://live.mephist.ru/show/number-naming/
Наименования и склонения числительных
Склонение числительных по падежам онлайн
именительный • родительный • дательный • винительный • творительный • предложный
Эта программа умеет называть и склонять количественные числительные от 1·10−3000
до числа, десятичная запись которого состоит из 3003 девяток. Вне этого
диапазона ни правильность результата, ни работоспособность программы не
гарантируются.
http://www.gramota.ru/class/coach/tbgramota/45_110
Выберите правильные варианты ответов. Для проверки
выполненного задания нажмите кнопку «Проверить».
Следует выучить несколько простых правил, которые
регулируют правописание имен числительных.
1. У числительных «ПЯТЬ» – «ДЕВЯТНАДЦАТЬ», а также
«ДВАДЦАТЬ» и «ТРИДЦАТЬ» Ь пишется на конце, а у
числительных «ПЯТЬДЕСЯТ» – «ВОСЕМЬДЕСЯТ» и «ПЯТЬСОТ» –
«ДЕВЯТЬСОТ» – в середине слова.
2. Числительные «ДЕВЯНОСТО» и «СТО» имеют окончание О в
именительном и винительном падежах, а в остальных
падежах – окончание А. (ИСТРАТИТЬ СТО РУБЛЕЙ, НЕ ХВАТАЕТ
СТА РУБЛЕЙ). Числительное «СОРОК» в именительном и
винительном падежах имеет нулевое окончание, а в
остальных падежах – окончание А. ( ЕМУ НЕТ И СОРОКА
ЛЕТ). В именительном и винительном падежах числительное
«ДВЕСТИ» имеет окончание И, а числительные «ТРИСТА» и
«ЧЕТЫРЕСТА» – окончание А. (СУЩЕСТВУЕТ УЖЕ ТРИСТА ЛЕТ).
3. Сложные числительные (и количественные, и
порядковые), состоящие из двух основ, пишутся слитно
(ШЕСТНАДЦАТЬ, ШЕСТНАДЦАТЫЙ, ДЕВЯТЬСОТ, ДЕВЯТИСОТЫЙ).
4. Составные числительные пишутся раздельно, имея
столько слов, сколько в числе значащих цифр, не считая
нулей (ПЯТЬСОТ ДВАДЦАТЬ ТРИ. ПЯТЬСОТ ДВАДЦАТЬ ТРЕТИЙ).
Однако порядковые числительные, оканчивающиеся на
-ТЫСЯЧНЫЙ, -МИЛЛИОННЫЙ, -МИЛЛИАРДНЫЙ пишутся слитно
(СТОТЫСЯЧНЫЙ, ДВУХСОТТРИДЦАТИПЯТИМИЛЛИАРДНЫЙ).
5. Дробные числительные пишутся раздельно (ТРИ ПЯТЫХ,
ТРИ ЦЕЛЫХ И ОДНА ВТОРАЯ), но числительные
ДВУХСПОЛОВИННЫЙ, ТРЕХСПОЛОВИННЫЙ, ЧЕТЫРЕХСПОЛОВИННЫЙ
пишутся слитно. Числительное ПОЛТОРА и ПОЛТОРАСТА имеют
лишь две падежные формы: ПОЛТОРА (ПОЛТОРЫ в ж. Р.),
ПОЛТОРАСТА для именительного и винительного падежа и
ПОЛУТОРА, ПОЛУТОРАСТА для всех остальных падежей без
родовых различий.
6. B составных количественных числительных склоняются
все образующие их слова (ДВЕСТИ ПЯТЬДЕСЯТ ШЕСТЬ –
ДВУХСОТ ПЯТИДЕСЯТИ ШЕСТИ, ДВУМЯСТАМИ ПЯТЬЮДЕСЯТЬЮ
ШЕСТЬЮ), При склонении дробных числительных также
изменяются обе части (ТРИ ПЯТЫХ – ТРЕХ ПЯТЫХ – ТРЕМ
ПЯТЫМ – ТРЕМЯ ПЯТЫМИ – О ТРЕХ ПЯТЫХ).
7. НО при склонении составного порядкового числительного
изменяется только окончание последней составной части
(ДВЕСТИ ПЯТЬДЕСЯТ ШЕСТОЙ – ДВЕСТИ ПЯТЬДЕСЯТ ШЕСТОГО –
ДВЕСТИ ПЯТЬДЕСЯТ ШЕСТЫМ).
8. Слово ТЫСЯЧА склоняется, как существительное женского
рода на -А; слова МИЛЛИОН и МИЛЛИАРД склоняются, как
существительные мужского рода с основой на согласный.
9. Обратите внимание: числительные ОБА (м. и ср. р.) и
ОБЕ (ж. р.) склоняются по-разному: у числительного ОБА
основой для склонения является ОБОJ- (ОБОИХ, ОБОИМ,
ОБОИМИ), а у числительного ОБЕ основа ОБЕJ- (ОБЕИХ,
ОБЕИМ, ОБЕИМИ).
10. Обратите внимание: при смешанном числе
существительным управляет дробь, и оно употребляется в
родительном падеже единственного числа: 1 2/3 м (ОДНА
ЦЕЛАЯ И ДВЕ ТРЕТЬИХ МЕТРА).
Упражнение
1. Испанский художник Гойя за свою жизнь создал 700 картин.
2. П. М. Третьяков в
1892 году
передал в дар Москве 1925 произведений
искусства.
3. В некоторых городах из-за чумы в 14 веке погибло 56,3
% населения.
4. По энциклопедии это известный русский гистолог,
уволенный в 1914 году
из Московского университета реакционным министром
просвещения Кассо. [Д. Гранин. Зубр (1987)]
5. Я уверен, что вы встретите об_их
сестёр.
6. Он вышел из дома с 300 рубл_
7. Город меняет метрику пространства, и вы согласитесь
со мной, что 150 шагов
— не одно и то же в городе и в деревне. [Б. Хазанов.
Город и сны (2001)]
8. На гербе нашей страны изображён дву_главый орел.
9. Горький опыт Коломнина и других научил нас, что доза
эта, напротив, очень невелика, что нельзя вводить в
организм человека больше 6/100 грамм_ кокаина;
эта доза в двадцать пять раз меньше той, которую
назначил своей больной несчастный Коломнин. [В. В.
Вересаев. Записки врача (1895–1900)]
10. Я вернулся домой с 672 рублями.
11. И дома, и в поле, и в сарае я думал о ней, я
старался понять тайну молодой, красивой, умной женщины,
которая выходит за неинтересного человека, почти за
старика (мужу было больше 40лет),
имеет от него детей, – понять тайну этого неинтересного
человека, добряка, простака, который рассуждает с таким
скучным здравомыслием, на балах и вечеринках держится
около солидных людей, вялый, ненужный… [А. П. Чехов. О
любви (1898)]
12. — Дело не в пессимизме и не в оптимизме, — сказал я
раздраженно, — а в том, что у 99 из
ста нет ума. [А. П. Чехов. Дом с мезонином (1896)]
13. Гости с уважением указывали на одного богатого
откупщика, ее родителя, и кое-кто замечал шепотом, что
за ней уже отложено на приданое 300 тысяч
рублей. [Ф. М. Достоевский. Елка и свадьба (1848)]
14. Ежели бы Кутузов решился оставаться в Кремле, то
армия Наполеона отрезала бы его от всех сообщений,
окружила бы его 40000 изнуренную
армию, и он находился бы в положении Мака под Ульмом.
[Л. Н. Толстой. Война и мир. Том первый (1867–1869)]
15. Печатать текст нужно с дв_с_половинным интервалом.
Упражнение подготовили Н. Маслов и Б. А. Панов («Лига
Школ»).
Ле́ксика (от др.-греч. τὸ λεξικός — «относящийся к слову», от ἡ λέξις — «слово»,
«оборот речи») — совокупность слов того или иного языка, части языка или слов,
которые знает тот или иной человек или группа людей. Лексика является
центральной частью языка, именующей, формирующей и передающей знания о
каких-либо объектах, явлениях.
Словарный состав языка — наиболее открытая и подвижная сфера языка. В него
непрерывно входят новые слова и постепенно уходят старые. Нарастающая сфера
человеческих знаний прежде всего закрепляется в словах и их значениях, благодаря
чему лексических приобретений в языке становится все больше. Образование, наука,
новейшие технологии, сведения из других культур — всё это формирует новый тип
современного общества (информационное), в котором формируется новый языковой
стиль — стиль эпохи информационного развития.
Словарный состав языка
Словарный состав языка - все слова (лексика) какого-либо языка (в т. ч.
неологизмы, диалектная лексика, жаргонизмы, терминология и т. д.). Объём и
состав словарного состава языка зависят от характера и развитости хозяйственной,
общественной, культурной жизни носителей языка. Словарный состав языка
представляет собой определённым образом организованную систему, где слова
объединяются или противопоставляются в том или ином содержательном отношении (синонимы,омонимы,
антонимы, лексические поля).
По частоте и общеупотребительности в словарном составе языка выделяются часто
употребляемые слова — активный запас слов (активный словарь) и слова,
употребляемые редко или в специальных целях (архаизмы, неологизмы, терминология
и т. д.) — пассивный запас слов (пассивный словарь). Границы между активным и
пассивным словарём подвижны, в историческом развитии языка происходит
перемещение слов из одной группы в другую (ср., например, русские "прошение", "прислуга",
"гувернёр", "городовой", перешедшие из активного в пассивный словарь). Слова,
находящиеся в активном употреблении у всех носителей языка на протяжении
длительной истории его развития (например, названия частей тела, явлений природы,
термины родства, обозначения основных действий, свойств, качеств), называются
основным лексическим (словарным) фондом языка, который подвержен изменениям в
наименьшей степени. Выявлению соотношения активного и пассивного запаса в
словарном составе языка на определённом этапе его развития (обычно в рамках
нескольких стилей, жанров, видов речи) служат частотные словари.
Все носители языка обычно легко вычленяют слова в потоке речи, осознают их как
самостоятельные, отдельные языковые единицы.
Итак, слово – это значимая, самостоятельная единица языка, основной функцией
которой является номинация (название). В отличие от морфем, минимальных значимых
единиц языка, слово самостоятельно, грамматически оформлено по законам данного
языка, и оно обладает не только вещественным, но и лексическим значением. В
отличие от предложения, обладающего свойством законченной коммуникации, слово
как таковое не коммуникативно, но именно из слов строятся предложения. При этом
слово всегда связано с материальной природой знака, посредством чего слова
различаются, образуя отдельные единства смысла и звукового (или графического)
выражения.
Словарный состав языка непрерывно пополняется с развитием общества по
словообразовательным законам языка, а также за счёт заимствований. В словарный
состав рус. языка, в основе которого слова общеславянского и исконно русского
происхождения, вошли на разных этапах развития слова из скандинавских, финских,
тюркских, старославянских, греческих, позднее — из латинских, романских,
германских языков. В словарный состав немецкого языка вошли слова из латинского,
французского, итальянского, английского и некоторых других языков. Эти слои
заимствованной лексики в С. с. я. отражают культурно-исторические связи народов,
являясь одним из доказательств (иногда единственным) контактов древних народов.
С. с. я. фиксируются (не полностью) в толковых словарях.
Далее.
Все слова, употребляющиеся в данном языке, образуют его словарный состав. Среди
этого большого круга лексических единиц имеется небольшой, но отчетливо
выделяющийся круг слов – основной словарный фонд, объединяющий все корневые
слова, ядро языка. Основной словарный фонд менее обширен, чем словарный состав
языка; от словарного состава языка он отличается тем, что живет очень долго, в
продолжение веков, и дает языку базу для образования новых слов.
Основной словарный фонд охватывает самые необходимые слова языка. Для
обозначения одного и того же в языке может быть ряд синонимов, которые
по-разному расцениваются в словарном составе языка и не все входят в основной
словарный фонд. Слова основного словарного фонда – факты нейтральной лексики: их
можно употреблять с тем же значением в любом жанре речи (устная и письменная
речь, проза и стихи, драма и фельетон и т.д.) и в любом контексте. Следует
оговориться, что при многозначности слова не все значения данного слова являются
фактом основного словарного фонда.
Через словарный состав язык непосредственно связан с действительностью и ее
осознанием в обществе. В лексике находят отражение социальные, профессиональные,
возрастные различия внутри языкового коллектива. Т.к. лексика обращена к
действительности, она очень подвижна, сильно изменяет свой состав под
воздействием внешних факторов. Возникновение новых реалий, исчезновение старых
ведет к появлению или уходу соответствующих слов, изменению их значений. Именно
поэтому точное количество всех слов языка принципиально невозможно подсчитать.
В словаре носителей языка различают активный и пассивный словари. Активный
словарь – это те слова, которые говорящий на данном языке не только понимает, но
и сам употребляет. Слова основного словарного фонда безусловно составляют основу
активного словаря, но не исчерпывают его, т.к. у каждой группы людей, говорящих
на данном языке, есть и такие специфические слова и выражения, которые для
данной группы всходят в их активный словарь, ежедневно ими употребляются, но не
обязательны как факты активного словаря для других групп людей, имеющих в свою
очередь иные слова и выражения. Таким образом, слова основного словарного фонда
– общие для активного словаря любых групп населения, слова же специфические
будут разными для активного словаря различных групп людей.
Пассивный словарь – это те слова, которые говорящий на данном языке понимает, но
сам не употребляет. Таковы, например, многие специальные технические или
дипломатические термины, а также и различные экспрессивные выражения.
Понятия активного и пассивного словаря очень важны при изучении иностранного
языка. Однако нельзя забывать, что слова, имеющиеся в пассиве, могут при
надобности легко перейти в актив, а наличное в активе – уйти в пассив.
Происхождение лексики современного русского языка
Словарный состав языка (лексика) – это совокупность всех слов данного языка.
Лексикой называют также и совокупность слов писателя, отдельного человека,
состав слов какого-либо произведения.
Формирование состава русского языка – процесс длительный и сложный. Наряду со
словами, которые появились в языке сравнительно недавно, в нем существует
большое количество слов очень древних, но активно употребляемых в настоящее
время.
Лексикология – раздел языкознания, изучающий словарный состав языка. В курсе
лексикологии слова русского языка рассматриваются с различных точек зрения:
изучаются значения слов, их место в общей системе языка, происхождение,
стилистическая окраска.Лексикон — весь словарный запас языка, в котором выделяют
активную и пассивную составляющие.
|
|