Машинное обучение для ... |
Machine Learning
|
Машинное обучение (Machine Learning) — раздел
искусственного интеллекта, изучающий методы построения алгоритмов,
способных обучаться на выявлении
закономерностей в эмпирических данных.
|
Нейронные сети учатся совсем не так как люди.
Для нейронных
сетей "обучение = оптимизация"
Оптимизация (обучение) нейронной сети — градиентный спуск по
некоторой функции потерь, где переменными аргументами
являются веса слоёв.
Методы оптимизации (бучения) нейронных
сетей
(все они предполагают, что градиент хорошо
себя ведёт: нет обрывов, где он скачкообразно возрастает,
или плато, где он обращается в ноль). Но это не так...
Статьи, исследующие другие
подходы к обучению: вместо сглаживания целевой функции,
приближённо считают градиент в экстремальных случаях....
|
Машинное обучение
образовалось
в результате разделения науки о нейросетях на методы обучения сетей и виды
топологий архитектуры сетей, вобрав в себя методы математической
статистики и вычислительной математики.
Обучение искусственных нейронных сетей
- процесс настройки (для
эффективного решения поставленной задачи):
Хорошая простая сетевая книга (на
английском):
Neural Networks and Deep Learning.
Хорошая сложная книга:
В.В.Вьюгин
МАТЕМАТИЧЕСКИЕ ОСНОВЫ ТЕОРИИ МАШИННОГО ОБУЧЕНИЯ И ПРОГНОЗИРОВАНИЯ
20 янв «В сфере
машинного обучения сильный разброс. У Google не будет всех данных в
мире»
Партнер фонда
Andreessen Horowitz Бенедикт Эванс объясняет, почему успехи Google и
Facebook в освоении искусственного интеллекта не делают их лидерами в
этой области.
Грант Сандерсон
[DeepLearning | видео 1] Что же такое нейронная сеть?
https://www.youtube.com/watch?time_continue=353&v=RJCIYBAAiEI
все 4 видео:
https://www.youtube.com/playlist?list=PLZHQObOWTQDNU6R1_67000Dx_ZCJB-3pi
канал:
https://en.wikipedia.org/wiki/3Blue1Brown
https://habr.com/ru/post/438328/
https://habr.com/ru/post/438364/
https://habr.com/ru/company/madrobots/blog/438420/
https://habr.com/ru/post/438432/
https://habr.com/ru/post/428259/
https://habr.com/ru/post/424603/
https://habr.com/ru/company/ivideon/blog/438322/
Восемь потрясающих игр с искусственным интеллектом от компании Google
https://habr.com/ru/post/399321/
Разработчики из подразделения Google Research создали алгоритм обучения
нейросети для автоматической генерации текстового описания объектов на
изображениях на естественном (английском) языке. Он сочетает в себе
алгоритмы компьютерного зрения и обработки естественного языка. К
примеру, система способна создавать подписи наподобие «две собаки играют
на траве» или «маленькая девочка в розовой шляпке надувает пузыри». Идея
пришла благодаря последним достижениям в машинном переводе, где одна
рекурентная нейронная сеть (RNN) преобразует предложение на одном языке
в векторную модель, а вторая - преобразует эту модель в предложение на
другом языке. Вот инженеры и подумали, почему бы в качестве первой
нейросети не использовать сверточную нейросеть для распознавания
объектов на изображениях (CNN). Разработчики планируют использовать
полученную систему, например, для помощи слепым людям и для
усовершенствования поиска картинок на Google Images.
Команда разработчиков из Стэнфорда представила нейросеть NeuralTalk,
которая отыскивает на изображении отдельные объекты, события или
действия, назначает им отдельные слова и в итоге складывает их в
осмысленное предложение. Например "Печенье и чашка кофе находятся на
книге". ИИ формирует несколько предложений и выбирает из них наиболее
вероятно-правильное. Недавно мы рассказывали о подобной системе,
созданной в Google.
Французская компания Yseop специализируется
на автоматическом формировании новостей, корпоративных отчетов, писем
клиентам. На сайте компании можно поиграться с живым примером: это
финансовая статья, которая обновляется автоматически каждый раз, когда
вы меняете исходные данные в боковой панели. Первоначально в статье
рассказывается о «существенной позитивной динамике», но если ввести
более низкий показатель, то текст меняется, например, на «резкое
снижение».
https://demo.narrativa.com
Испанский стартап Narrativa создал
нейросеть, которая самостоятельно формирует обзоры футбольных матчей на
основании статистики игры. Пример текста "Севилья» выиграла у Атлетика,
получив в итоге 8 побед у себя дома. Гамейро забил первый мяч и закончил
игру с пенальти после того, как Кочовяк был удален с поля. Атлетику не
повезло: несмотря на постоянное владение мячом, команда не реализовала
ряд потенциальных голевых ситуаций". Как это получается? Сначала
нейросеть долго кормили футбольными обзорами, обучая ее извлекать факты
статистики (голы, удары, % владения мячем, замены, карточки...) из
текста. Потом запустили нейросеть в обратном направлении, так чтобы
исходя из фактов статистики она формировала предложения.
7 шалостей с нейросетями: алгоритмы ищут пьяных, гоняют котов, сочиняют
песни
https://daily.afisha.ru/brain/2318-7-shalostey-s-neyrosetyami-algoritmy-ischut-pyanyh-gonyayut-kotov-sochinyayut-pesni/
5 самых странных и бестолковых нейросетей
«Забивать микроскопом гвозди»: нейросети которые мы заслужили
https://revolverlab.com/5-neurolinks-fb5a5549c690
«Это называется — поставить на место», — прокомментировал этот короткий
диалог председатель комиссии Совета Федерации по информационной политике
Алексей Пушков.
Источник: http://rusvesna.su/news/1550345129
Как написать интересный текст с помощью нейросетей
http://2035.media/2019/01/20/text-services/
Как научить свою нейросеть генерировать стихи
https://habr.com/ru/post/334046/
Как видно из рисунка, лемма имеет приписанную к ней часть речи. Это
сделано для того, чтобы можно было использовать уже предобученные
эмбеддинги для лемм (например, от RusVectores).
С другой стороны, эмбеддинги для тридцати тысяч лемм вполне можно
обучить и с нуля, инициализируя их случайно.
Нейросеть научилась озвучивать немые видеоролики
Учёные из Университета Северной Каролины в Чапел-Хилл (University of
North Carolina at Chapel Hill, США), а также исследователи из Adobe
Research разработали метод, позволяющий по беззвучной видеозаписи
восстановить звуковую дорожку, например, лай собаки, плач ребёнка или
шум водопада.
Для решения этой задачи были задействованы рекуррентные нейронные сети —
реализуемые на компьютере математические модели, представляющие собой
связанные узлы (нейроны), обрабатывающие входной сигнал, руководствуясь
собственными параметрами. Преимущество рекуррентных нейронных сетей
в том, что каждое последующее состояние сети зависит от предыдущего,
полученного на другом «куске» данных. Это проявляется в наличии
у рекуррентной нейросети памяти и возможности распознавания
последовательных данных, таких как звук, видео или текст. Для сравнения,
работа обычной нейросети похожа на мгновенный акт распознавания образа
нашим мозгом: сидя за рулём, важно заметить дорожный знак и распознать
его тип, при этом почти не имеет значения траектория движения знака
относительно автомобиля (за исключением редких случаев, когда есть
опасность в него врезаться). Рекуррентная нейросеть постоянно
переотправляет результат своих предсказаний в исходные данные,
используемые для последующих предсказаний, подобно тому, как мы играем
в «угадай мелодию», распознавая музыку по нескольким упорядоченным
характерным признакам (нотам).
При обучении нейронным сетям показывали разные ролики, а те пытались
обнаружить зависимость между видеорядом и звуковой дорожкой. При этом
обучение пробовали проводить тремя разными способами: покадрово,
синхронизируя звук и видеоряд; раздельно, когда нейросеть сначала ищет
характерные признаки видео, а потом связывает их с характерными
признаками звука (части нейросети, обрабатывающие видео и звук, учатся
асинхронно); и, наконец, задействовав специальную технологию,
позволяющую восстанавливать картинки между кадрами видео (она была
разработана в 2010 году учёными из Брауновского (Brown University) и Дармштадтского
технического (нем. Technische
Universität Darmstadt) университетов).
Выяснилось, что последний метод обучения (flow) более чем в половине
случаев лидирует над покадровым (frame) и асинхронным (seq), а если
и отстаёт, то ненамного. Здесь показана суммарная статистика точности
распознавания, чистоты звука и его уровня совпадения с видеорядом:
В качестве финальной проверки метода, звуки, реконструированные
нейросетями по немым видеозаписям, дали послушать людям (показав
и видео). Испытуемых предупредили, какими признаками должно обладать
ненастоящее звуковое сопровождение: плохое совпадение с видео, низкое
качество, большой уровень шума. Для верности, каждое озвученное
нейросетями видео показывали трём испытуемым, устраивая затем
голосование, является ли звуковая дорожка оригинальной. При этом учёные
решили дополнительно усложнить процесс проверки, периодически показывая
людям видео со звуком от другого ролика из той же категории. Результатом
можно гордиться: более 70% искусственных звуковых сопровождений
испытуемые не смогли отличить от реальных. Лучше всего удалось
восстановить по видео звуки потоков воды, фейерверков и работающей
бензопилы, в то время как в нейросетевой плач ребёнка поверило всего
около 61% испытуемых. Интересно, что на тех типах роликов, где нейросети
показывали худшие результаты, испытуемые часто выбирали звуковую дорожку
от других роликов той же группы (путая вертолёты, принтеры и плачущих
детей).
В дальнейшем исследователи планируют научить ИИ ассоциировать звук
с конкретным объектом на видео, а также попробовать найти оптимальные
способы обучения нейросетей.
Согласно новому отчёту исследовательской
компании Gartner, которая специализируется на рынках ИТ, количество
внедривших искусственный интеллект компаний увеличилось на 270 процентов
за последние 4 года.
В 2015 году ИИ использовало или планировало использовать только 10
процентов респондентов, в 2018-м — 25 процентов. К 2019 году их доля
составила 37 процентов, отмечает вице-президент Gartner Крис Ховард.
В исследовании принимало участие более 3 тысяч ИТ-менеджеров из 89
стран. Суммарная выручка компаний, участвовавших в опросе, составляет
$15 трлн, а инвестиции в информационные технологии — $284 млрд.
По словам Gartner, за последний год ИИ стало использовать в три раза
больше компаний в самых различных отраслях. Скачок объясняют прогрессом
в развитии технологии, в результате чего всё больше предприятий готовы
внедрять её. Ховард добавил, что это даёт им преимущество над
конкурентами, хотя человечество далеко от создания ИИ общего назначения,
который способен сам выполнять сложные задания. При этом отмечается
нехватка квалифицированных сотрудников в сфере.
По результатам исследования, 52 процента телекоммуникационных компаний
используют чат-ботов, а 38 процентов организаций в области
здравоохранения применяют ИИ в диагностике. Также технологию используют
для защиты от мошенничества и сегментации потребителей.
Прочесть
статью на MIT Technology Review.
Исследователи компании OpenAI создали алгоритм, который умеет
генерировать достаточно убедительные фейковые новости на любую
тему всего по нескольким входным словам.
Изначально исследователи планировали разработать алгоритм для
ответов на вопросы, резюмирования текстов и выполнения
переводов. Однако вскоре обнаружили, что получившуюся ИИ-систему
можно применить в куда более опасных целях, например для
массового распространения ложной информации. Поэтому команда
решила открыть широкий доступ только к его ограниченной версии.
Для тренировки использовали датасет в 40 Гб, собранный на основе
8 млн популярных ссылок Reddit. На данный момент технология
имеет некоторые недостатки, например ИИ часто «занимается
плагиатом» и не очень хорошо справляется с незнакомыми темами, а
тексты иногда получаются бессвязными. По словам исследователей
OpenAI, всего через 1-2 года система научилась бы стабильно
генерировать настолько естественные тексты, что разоблачить
подделки было бы очень сложно.
OpenAI запустили СЕО Tesla и SpaceX Илон Маск и президент Y
Combinator Сэм Альтман в 2015 году. Организация ставит целью
разработку искусственного интеллекта на благо общества.
Посетить сайт OpenAI и познакомиться с ним.
https://openai.com
Изучить материалы странички о GPT-2
https://blog.openai.com/better-language-models/#content
Рекомендуется познакомиться с кодом и статьёй
https://github.com/openai/gpt-2
https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
Компания Google научила нейросеть распознавать объекты
на простых рисунках. Чтобы совершенствоваться, нейросеть должна
постоянно обучаться. Для этого на основе нейросети запустили онлайн-игруQuick,
Draw!, в которой сеть должна как можно раньше угадать, что
рисует пользователь. На распространение игры обратил внимание
TJournal.
«Может ли нейронная сеть научиться распознавать рисунки?
Посмотри, насколько хорошо она это делает, и помоги обучить ее,
просто играя», — призывают создатели. Они отмечают, что
распознать рисунок — не так просто для искусственного
интеллекта, потому что один и тот же предмет разные люди могут
рисовать совершенно по-разному.
«Это не всегда работает. Но чем больше вы играете с нейросетью,
тем большему она научится. До сих пор мы обучили ее нескольким
сотням понятий и надеемся добавить еще. Мы сделали это
в качестве примера того, как вы можете использовать машинное
обучение в забавных вещах», — пишут на сайте игры.
Задача пользователя — нарисовать шесть простых объектов.
На каждый из них отводится по 20 секунд, за которые нейросеть
пытается угадать, что рисует человек. После каждой игры скетчи
пользователей добавляются в базу данных нейросети. Пользователю
показывают, как то же самое рисовали другие люди и объясняют,
почему сеть не смогла распознать его рисунок.
Наглядное введение в нейросети на примере распознавания цифр
https://www.captionbot.ai
Сервис от Microsoft автоматически генерирующий подписи к фото
Проект под названием CaptionBot - онлайн приложение, которое
автоматически генерирует релевантные подписи к изображениям.
Сервис позволяет выбирать для анализа как фотографии доступные в
сети, так и снимки, загруженные с компьютера. Но помните, все снимки
которые вы загружаете будут сохранены, для дальнейшего обучения
системы!
Сервис Microsoft, угадывающий возраст человека по фотографии
В качестве демонстрации возможностей облачной платформы Azure
компания Microsoft представила шуточный сервис How-Old.net, который
анализирует загружаемую фотографию и сообщает предполагаемый возраст
изображённого на ней человека.
https://www.how-old.net
Компания Google объявила о запуске сайта A.I.
Experiments в открытом доступе для всех пользователей. Здесь собраны
простые эксперименты, которые позволяют в игровой форме понять, как
именно работают нейронные сети и машинное обучение.
https://experiments.withgoogle.com/collection/ai
На презентации сайта креативный директор Google Creative Lab Алекс Чен
сказал, что “учитывая крутизну кривой обучения для таких программ,
компания представляет A.I. Experiments”, чтобы подобные программы не
пугали разработчиков, которые хотят заниматься искусственным
интеллектом.
Пользователи могут как экспериментировать с уже готовыми образцами таких
программ, так и загружать свой код, чтобы проверить, как это работает.
Сейчас на сайте – восемь разновидностей программ на основе нейронных
сетей.
К примеру, в Quick, Draw! можно попробовать самому нарисовать набросок
какого-либо объекта за 20 секунд с помощью мыши или пальца, и дать
нейронной сети его опознать.
http://primat.org/demo/network/network.html#2
2019/01/15 19:07:19
Искусственный интеллект (мировой рынок)
Frost & Sullivan (15 января 2019 года): Рынок ИИ будет расти на 31%
ежегодно. К 2022 году суммарный бъем рынка технологий ИИ увеличится до
$52,5 млрд (2018 - $17,8 млрд).
Tractica: объем рынка ПО ИИ в 2018 - $8,1 млрд. К 2025 году - $105,8
млрд.
Инвестиции в AI в 2018 - $50 млрд, в 2017 - $25 млрд
Повсеместное внедрение ИИ к 2030 году увеличит объем глобального рынка
товаров и услуг на $15,7 трлн
http://www.tadviser.ru/a/425392
Анализ показывает, что почти 40% задач, выполняемых военнослужащими США,
можно автоматизировать. А это высвободит почти 500 тысяч человек.
По сумме инвестиций в ИИ лидер - США ($6.4 млрд.), за которыми следует
Китай ($5.5 млрд.). По средней стоимости сделки - Китай (от $100 млн)
против $15 млн у США.
5 самых популярных областей использования ПО ИИ:
видеонаблюдение,
системы мониторинга и управления ИТ-сетями и операциями,
клиентское обслуживание и маркетинг,
распознавание голоса и речи,
обнаружение и распознавание объектов техникой...
...
IDC - объем глобального рынка ИИ в 2018 - $24 млрд, в 2022-м - $77,6
млрд.
Среднегодовые темпы роста - 37,3%.
Около 40% затрат на приходится на ПО. Ежегодный рост - 43,1%.
BCC Research: объем рынка технологий распознавания речи - $104 млрд в
2016, $184,9 млрд в 2021, ежегодный рост за 2016–2021 +12,1% .
07.12.2018 в Стэнфорде состоялась конференция "AI и будущее
общества"
Основные тезисы:
ИИ – новое электричество: фундаментальная технология, которая
постепенно трансформирует большинство отраслей экономики и общества.
Это растянется на десятилетия.
Данные – это новая нефть, а Китай – новый ОПЕК. Накопление большого
объема данных критично для развития AI. Блокировка китайскими
властями доступа иностранных IT-компаний на их рынок и слабые
законы, защищающие конфиденциальность пользователей, привели к тому,
что китайские компании обгоняют Запад и претендуют на титул
AI-сверхдержавы.
Европе нужно срочно определяться с ролью в грядущем мире AI.
Число рабочих мест не уменьшится – но работа будет совсем другой.
Креатив, эмпатия, стратегия – главные человеческие качества, которые
это поколение AI не сможет воспроизвести.
Главный вызов AI не в том, что миллионам людей не будет кем
работать, а в том, что им придется постоянно быстро переучиваться.
БЕЗ ИИ – КАК БЕЗ ЭЛЕКТРИЧЕСТВА
Сергей Орлов
15 февраля 2019
От искусственного интеллекта уже начинает зависеть не только
безопасность, но и здоровье. На днях представитель российского
стартапа Skychain объявил, что ученые разработали ИИ, способный
диагностировать онкологию в легких по рентгеновским снимкам с
точностью в 94%. Этого удалось добиться, создав нейросеть и дав ей
изучить более 350 трехмерных КТ-снимков легких пациентов с раковыми
опухолями, пишут “Извесстия”.
В России есть подобные технологии и для определения инсульта на
основе МРТ. В США разработали устройство, с помощью которого
выявляют диабетическую ретинопатию, из-за которой теряет зрение не
малый процент трудоспособного населения.
Более простой вариант, но от того не менее важный — системы
телемедицины. Онлайн-сервис DocDoc, который называют Uber для
врачей, автоматически на основе указанных пациентов симптомов
подбирает специалиста, выдает направление на анализы и рекомендации
перед приемом. Стоит также упомянуть о технологиях, которые
облегчают жизнь людям с ограниченными возможностями: например,
разработанный Microsoft сервис распознавания разговорной речи,
необходимый людям с ограничениями по слуху.
Транспорт, безопасность, здравоохранение и другие сферы с участием
искусственного интеллекта — в масштабе всё это превращается в «умный
город». В Канаде уже проходят соревнования Smart Cities Challenge.
Власти России взяли на вооружение эту концепцию и включили ее в
перечень государственных программ. И успешные примеры уже есть.
Институт McKinsey включил Москву в топ «умных городов» Европы.
Столица заняла девятое место. При этом москвичи оказались самыми
передовыми среди европейцев — они больше остальных разбираются в
инновационных сервисах и пользуются ими.
Исследователи, изучавшие феномен «умных городов», изначально
полагали, что внедрение ИИ будет чем-то закулисным, незаметным глазу
людей. Но сейчас всё это становится их будничными рабочими
инструментами — взять те же сервисы отслеживания автобусов,
благодаря которым можно лишний раз не мерзнуть на остановке.
Для коммерческого сектора внедрение ИИ — вопрос выживания. Не
предоставив клиенту «умный сервис», потерять его проще простого.
Касается это и внутренних процессов. «Аэрофлот» рассчитывает уже
через два года использовать искусственный интеллект, чтобы
прогнозировать налоговые поступления и риски.
В современном мире применение технологий искусственного интеллекта —
один из важнейших аспектов развития, как на государственном уровне,
так и на уровне компаний. Инициативы по обмену опытом в этой области
и выработке совместных решений должны стать главной задачей для
бизнеса, законодателей, ученых и представителей государства, считают
в Сбербанке.
Не использовать ИИ в контексте времени равно отказу от
электричества. В Агентстве стратегических инициатив по продвижению
новых проектов отмечали, что пока компетенций в этой области
недостаточно, но на то искусственный интеллект и «ребенок, которого
надо обучать и развивать». Развивается он очень быстро — городскую
жизнь без него уже трудно представить.
|
Компания Google научила нейросеть распознавать объекты
на простых рисунках. Чтобы совершенствоваться, нейросеть должна
постоянно обучаться. Для этого на основе нейросети запустили онлайн-игруQuick,
Draw!, в которой сеть должна как можно раньше угадать, что
рисует пользователь. На распространение игры обратил внимание
TJournal.
«Может ли нейронная сеть научиться распознавать рисунки?
Посмотри, насколько хорошо она это делает, и помоги обучить ее,
просто играя», — призывают создатели. Они отмечают, что
распознать рисунок — не так просто для искусственного
интеллекта, потому что один и тот же предмет разные люди могут
рисовать совершенно по-разному.
«Это не всегда работает. Но чем больше вы играете с нейросетью,
тем большему она научится. До сих пор мы обучили ее нескольким
сотням понятий и надеемся добавить еще. Мы сделали это
в качестве примера того, как вы можете использовать машинное
обучение в забавных вещах», — пишут на сайте игры.
Задача пользователя — нарисовать шесть простых объектов.
На каждый из них отводится по 20 секунд, за которые нейросеть
пытается угадать, что рисует человек. После каждой игры скетчи
пользователей добавляются в базу данных нейросети. Пользователю
показывают, как то же самое рисовали другие люди и объясняют,
почему сеть не смогла распознать его рисунок.
Новости ML
|
Наиболее успешные современные
промышленные методы компьютерного зрения и распознавания речи построены на
использовании глубинных сетей, а гиганты IT-индустрии, такие как Apple, Google,
Microsoft,
Facebook скупают коллективы исследователей, занимающихся глубинным обучением
целыми лабораториями.
02 .04.2016
В
Калифорнийском университете
в Беркли создали нейросеть,
которая преобразует исходные чёрно-белые
фотографии в полноцветные, добавляя данные о цвете объектов по
результатам анализа свыше миллиона подобных изображений. За секунды она
достигает лучшего результата, чем профессионалы
за несколько часов работы в Photoshop.
Работа с иллюстрациями
здесь
24.01.201 6
Microsoft выложила в открытый доступ на
Github
исходный код
Computational Network Toolkit
- инструментов, которые используются в компании для глубинного обучения
в области искусственного интеллекта
29.05.2014
Руководителем Microsoft
Сатьей Наделлой
представлен устный переводчик для Skype с необычной способностью: чем больше
языков система осваивает, тем лучше начинает переводить с тех,
которые изучила до этого.
Skype
Translate
— это мощная нейросеть,
которая, к примеру, для распознавания речи строит
определенную модель.
Технологии Skype Translate также используются в
Microsoft Cortana
(из
WIndows Phone 8.1), которая понимает вопросы
на естественном языке и дает осмысленные ответы.
15.11.2014
Стив Балмер
(бывший
руководитель Microsoft)
пожертвовал "значительные средства" Гарвардскому университету
(в котором учился), что позволит ему расширить факультет компьютерных наук
на 50% сфокусировав его
на машинном обучении.
Сумма не оглашалась. Кроме того, Балмер пожертвовал
$50 млн Университету Орегона.
29.11.2014
 Стефан Вейтц
(глава подразделения Bing, поисковой системы
Microsoft): Стефан Вейтц
(глава подразделения Bing, поисковой системы
Microsoft):
-
Bing
удерживает около 30%
рынка в США.
Лидирующий в
этом сегменте Google Microsoft уже не сможет побороть,
но обычный поиск по ключевым
словам теряет своё первостепенное значение.
-
Microsoft собирается
улучшать свой поисковый движок в ещё несформировавшихся
областях, таких как машинное обучение и поиск на основе
естественного языка.
-
Bing является основой, на которой
базируется интеллектуальный помощник Cortana в Windows
Phone, а также построен индексатор Apple Spotlight в
операционных системах iOS 8 и Mac OS X 10.10 Yosemite.
Таким образом, в Microsoft ставят перед собой цель
создания технологий для интерактивного взаимодействия с
пользователем как на стационарных компьютерах, так и на смартфонах.
Согласно comScore для США
в сентябре 2014
Bing
пользовались 29.4% пользователей (+0.1% за год),
Google
использовали 67.3% (+0.4% за год).
10.11.2014
Поисковая система Google,
с помощью искусственных нейронных сетей и машинного обучения,
приобрела возможность
понимать, что изображено на фото
и описывать изображение на
естественном языке.
|
Математическая интерпретация обучения
нейронной сети
|
На каждой итерации алгоритма обратного
распространения весовые коэффициенты нейронной сети модифицируются так,
чтобы улучшить решение одного примера.
Таким образом, в процессе
обучения циклически решаются однокритериальные задачи оптимизации.
Обучение нейронной сети характеризуется
четырьмя ограничениями (выделяющими
ML
из общих задач оптимизации):
-
огромное число параметров,
-
необходимость высокого параллелизма
при обучении,
-
многокритериальность решаемых задач,
-
необходимость найти достаточно широкую
область, в которой значения всех минимизируемых функций близки к
минимальным.
В остальном проблема обучения,
как правило, формулируется как задача минимизации оценки.
На самом деле нам
неизвестны (и никогда не будут известны) все возможные задачи для
нейронных сетей.
|
Обучение по прецедентам
|
Обычно обучение
нейронной сети осуществляется на некоторой выборке (обучающей выборке,
совокупности прецедентов).
По мере процесса обучения,
который происходит по некоторому алгоритму, сеть должна все лучше и лучше
(правильнее) реагировать на входные сигналы.
Общая постановка задачи обучения по прецедентам:
-
Имеется
множество объектов (ситуаций) и множество
возможных
ответов (откликов, реакций).
-
Существует некоторая зависимость между ответами и
объектами, но она неизвестна.
-
Известна
конечная совокупность прецедентов — пар «объект, ответ», называемая
обучающей выборкой.
-
На
основе этих данных требуется восстановить зависимость
и построить
алгоритм, способный для любого объекта выдать приемлемо точный ответ.
Данная постановка является обобщением классических задач аппроксимации
функций, где объектами являются
действительные числа или векторы.
В реальных прикладных задачах входные
данные об объектах могут быть неполными, неточными, нечисловыми,
разнородными.
Эти особенности приводят к большому разнообразию методов
машинного обучения.
|
Алгоритмы
обучения нейронных сетей
|
Базовые виды нейросетей
(перцептрон и многослойный перцептрон) могут
обучаться:
с
учителем
(известны правильные
ответы к каждому входному примеру, а веса подстраиваются так, чтобы
минимизировать ошибку),
без
учителя
(позволяет распределить
образцы по категориям за счет раскрытия внутренней структуры и
природы данных),
с
подкреплением
(комбинируются два
вышеизложенных подхода).
Некоторые нейросети
и большинство статистических методов можно отнести только к одному из
способов обучения. Поэтому правильно классифицировать алгоритмы обучения
нейронных сетей.
Обучение с
учителем
— для каждого прецедента задаётся пара «ситуация, требуемое решение»:
Обучение без учителя
— для каждого прецедента задаётся только
«ситуация», требуется сгруппировать объекты в кластеры, используя данные
о попарном сходстве объектов, и/или понизить размерность данных:
Обучение с
подкреплением
— для каждого прецедента имеется пара «ситуация, принятое решение»:
Активное
обучение
— отличается тем, что обучаемый алгоритм имеет возможность
самостоятельно назначать следующую исследуемую ситуацию, на которой
станет известен верный ответ:
-
Обучение с частичным привлечением учителя (semi-supervised learning) —
для части прецедентов задается пара «ситуация, требуемое решение», а для
части — только «ситуация»
-
Трансдуктивное обучение (transduction) — обучение с частичным
привлечением учителя, когда прогноз предполагается делать только для
прецедентов из тестовой выборки
-
Многозадачное обучение (multi-task learning) — одновременное обучение
группе взаимосвязанных задач, для каждой из которых задаются свои пары
«ситуация, требуемое решение»
-
Многовариантное обучение (multiple-instance learning) — обучение, когда
прецеденты могут быть объединены в группы, в каждой из которых для всех
прецедентов имеется «ситуация», но только для одного из них (причем,
неизвестно какого) имеется пара «ситуация, требуемое решение»
|
Метод обратного
распространения ошибки
|
Существует большое число алгоритмов обучения, ориентированных на решение разных
задач.
Самый успешный:
Метод обратного распространения ошибки
(backpropagation) — метод обучения, который используется с
целью минимизации ошибки работы и получения желаемого выхода.
Основная идея метода:
В итоге каждый нейрон способен
определить вклад каждого своего веса в суммарную ошибку сети.
Простейшее правило
обучения соответствует методу наискорейшего спуска (изменения синаптических весов пропорционально их вкладу в общую ошибку).
См. подробнее:
http://ru.wikipedia.org/wiki/Метод_обратного_распространения_ошибки
|
Deep learning
|
Глубокое обучение
(Deep learning) - это раздел
ИИ, основанный на двух идеях:
-
обучение с использованием большого количества уровней представления
информации для моделирования комплексных отношений в данных,
-
обучение на немаркированных данных ("без учителя") или на комбинации
немаркированных и маркированных данных ("с частичным привлечением учителя").
При
обучении множеству уровней представления информации высокоуровневые признаки и
концепты определяются с помощью низкоуровневых.
Такая иерархия признаков
называется
Deep Architecture
(глубокой архитектурой).
Глубокие архитектуры произвели революцию в области
Machine
Learning,
значительно превзойдя другие модели в задачах распознавания изображений, аудио,
видео и др.
Попытки обучения глубоких архитектур (в основном, нейронных сетей) до 2006 года
проваливались (за исключением особого случая свёрточных нейронных сетей).
Успешный
подход Хинтона
использует
Restricted Boltzmann
Machine
(Ограниченную
Машину Больцмана,
RBM) для моделирования каждого нового слоя высокоуровневых признаков:
-
каждый новый слой гарантирует увеличение нижней границы логарифмической функции
правдоподобия, таким образом улучшая модель при надлежащем обучении.
-
когда
достаточное количество слоёв обучено, глубокая архитектура может быть
использована как в качестве дискриминативной модели для распознавания подаваемых
на вход данных (с помощью прохода "снизу вверх"), так и в качестве генеративной
модели для производства новых образцов данных (с помощью прохода "сверху вниз").
|
Задачи
для машинного обучения
|
Цель
ML
- автоматизация
решения сложных задач в самых разных областях
человеческой деятельности:
-
классификации (как правило, выполняется с помощью обучения с учителем на
этапе собственно обучения).
-
Кластеризации
(как правило, выполняется с помощью обучения без учителя)
-
Регрессии
(как правило, выполняется с помощью обучения с учителем на
этапе тестирования, является частным случаем задач прогнозирования).
-
Понижения
размерности данных и их визуализация (выполняется с помощью
обучения без учителя)
-
Восстановления плотности распределения вероятности по набору данных
-
Выявления новизны
-
Построениея
ранговых зависимостей
Типы входных данных при обучении
-
Признаковое описание объектов — наиболее распространённый случай.
-
Описание взаимоотношений между объектами, чаще всего отношения попарного
сходства, выражаемые при помощи матрицы расстояний, ядер либо графа
данных
-
Временной ряд или сигнал.
-
Изображение или видеоряд.
-
Типы функционалов качества
|
Данные
для машинного обучения
|
Типы входных данных при обучении:
-
Признаковое описание объектов — наиболее распространённый случай.
-
Описание взаимоотношений между объектами, чаще всего отношения попарного
сходства, выражаемые при помощи матрицы расстояний, ядер либо графа
данных
-
Временной ряд или сигнал.
-
Изображение или видеоряд.
-
Типы функционалов качества
|
Приложения
машинного обучения
|
Целью является частичная или полная автоматизация
решения сложных задач в самых разных областях
человеческой деятельности.
Машинное обучение имеет широкий спектр приложений:
-
Распознавание речи
-
Распознавание жестов
-
Распознавание рукописного ввода
-
Категоризация документов
-
Ранжирование в информационном поиске
-
Распознавание образов
-
Диагностика
(техническая, медицинская...)
-
Биоинформатика
-
Обнаружение спама
-
Биржевой технический анализ
и др...
Сфера
применений машинного обучения постоянно расширяется по мере накопления огромных объёмов данных в науке,
производстве, финансах, транспорте, здравоохранении.
Возникающие при этом
задачи прогнозирования, управления и принятия решений часто сводятся к
обучению по прецедентам.
Раньше, когда таких данных не было, эти задачи
либо вообще не ставились, либо эффективно решались другими методами.
|
Обобщающая способность и переобучение
|
Обобщающая способность (generalization
ability, generalization performance) - характеристика алгоритма
обучения, обеспечивающая
вероятность ошибки на тестовой
выборке на уровне ошибки на обучающей
выборке.
Обобщающая
способность тесно связана с понятиями переобучения и недообучения.
Недообучение — нежелательное явление,
возникающее при решении задач обучения
по прецедентам,
когда алгоритм
обучения не
обеспечивает достаточно малой величины средней ошибки на обучающей
выборке.
Недообучение возникает при использовании недостаточно сложных моделей.
Переобучение (overtraining,
overfitting) — нежелательное явление, возникающее при решении задач обучения
по прецедентам,
когда вероятность ошибки обученного алгоритма на объектах тестовой
выборки оказывается
существенно выше, чем средняя ошибка на обучающей
выборке.
Переобучение возникает при использовании избыточно сложных моделей.
Эмпирический риск - средняя
ошибка алгоритма на обучающей выборке.
Метод минимизации
эмпирического риска (empirical
risk minimization, ERM)
состоит в том,
чтобы в рамках заданной модели выбрать
алгоритм, имеющий минимальное значение средней ошибки на заданной
обучающей выборке.
Переобучение
появляется именно вследствие минимизации эмпирического риска:
-
пусть задано
конечное множество из D алгоритмов, которые допускают ошибки
независимо и с одинаковой вероятностью.
-
число ошибок
любого из этих алгоритмов на заданной обучающей выборке подчиняется
одному и тому же биномиальному
распределению.
-
минимум
эмпирического риска — это случайная величина, равная минимуму из D независимых
одинаково распределённых биномиальных случайных величин.
Её ожидаемое значение уменьшается с ростом D.
-
соотвественно,
с ростом D увеличивается переобученность— разность вероятности
ошибки и частоты ошибок на обучении.
В реальной ситуации алгоритмы имеют различные
вероятности ошибок, не являются независимыми, а множество алгоритмов, из
которого выбирается лучший, может быть бесконечным. По этим причинам
вывод количественных оценок переобученности является сложной задачей,
которой занимается теория
вычислительного обучения.
Всегда существует оптимальное значение сложности модели, при котором
переобучение минимально.
|
AutoML
|
Компания Google объявила об
очередном большом шаге в разработке искусственного интеллекта, рассказав
про
AutoML - новом подходе к машинному обучению, с помощью которого нейронные сети можно
будет использовать для создания еще более эффективных нейронных сетей.
Сундар Пичаи
(ген. директор Google)
показал пример работы AutoML на конференции Google
I/O 2017.
-
Сегодня проектирование нейронных сетей чрезвычайно трудоемко и требует
опыта, что недоступно для небольших сообществ ученых и инженеров. Вот почему
мы создали подход под названием AutoML, благодаря которому нейронные сети
могут создавать нейронные сети. Мы надеемся, что AutoML будет обладать
способностями нескольких докторов наук и позволит через три-пять лет сотням
тысяч разработчиков создавать новые нейронные сети для своих конкретных
потребностей.
-
Работает это так: мы берем набор кандидатов в нейронные сети, — назовем их
нейронными сетями-малышами, — и многократно прогоняем через них на предмет
поиска ошибок уже готовую нейронную сеть до тех пор, пока не получим еще
более эффективную нейронную сеть.
См. в официальном блоге.
С помощью технологии AutoML ИИ-платформы станут быстрее обучаться и будут
гораздо умнее.
Согласно Google, даже сейчас уровень AutoML уже таков, что она может быть
эффективнее экспертов-людей в вопросе поиска лучших подходов для решения
конкретных проблем. В перспективе это позволит существенно упростить процесс
создания новых ИИ-систем, так как, по сути, их будут создавать себе же
подобные.
Предполагается,
что эта технология приведет к появлению новых
нейронных сетей и открытию возможностей, когда даже не эксперты смогут
создавать свои личные нейронные сети для своих определенных нужд. Это, в
свою очередь, увеличит способность технологий машинного обучения оказывать
влияние на нас всех.
См.
подробнее. |
Сетевые ресурсы
От автоматической обработки текста к машинному пониманию
|
Из
лекции
Владимира Селегея
- директора по
лингвистическим исследованиям компании ABBYY, заведующего кафедрами
компьютерной лингвистики РГГУ и МФТИ, председателя оргкомитета ведущей
российской конференции по компьютерной лингвистике «Диалог»
(прочитана 9 октября 2012 г. в Лектории
Политехнического музея).
-
Важно, что статистическая революция открыла путь к реальному многоязычию.
Но самое главное, что методы статистической оценки и машинного обучения
стали использоваться и в подходах, основанных на лингвистических
моделях. Появились гибридные системы, правда, направление соединения
может быть разным. Можно брать статистику и добавлять в нее лингвистику.
У нас другой подход: мы берем лингвистические модели и обучаем их на
корпусах. Наш подход нам кажется лучшим.
-
Хочу сказать несколько слов по поводу машинного обучения. Есть
математические методы, которые позволяют решать, например, задачу
классификации. У вас есть множество объектов интересующего вас типа, и
вы хотите иметь диагностическую процедуру, позволяющую решить, относится
или не относится к этому множеству новый объект. Есть несколько
областей, где это обучение может быть эффективным, например,
идентификация искусственно сгенерированных текстов или фильтрация спама.
Все мы являемся жертвами спаммеров, причем спам часто генерируется
роботами, и нужно придавать им некоторую вариативность, чтобы эти тексты
распознавались как натуральные. Если вы попытаетесь решить проблему
распознавания спама чисто лингвистическими методами, у вас ничего не
получится. Никто из лингвистов не способен дать четкий ответ на вопрос,
чем отличается натуральный текст от ненатурального.
-
Гораздо более эффективен метод машинного обучения. В чем он состоит? Вы
берете большое количество натуральных и ненатуральных текстов и
пытаетесь с помощью математических методов определить, какие параметры,
доступные вам для анализа в этих текстах, делают их натуральными или
ненатуральными. К сожалению, сегодня методы машинного обучения чаще
всего ориентируются на простые модели сочетаемости слов. Тем не менее,
даже это дает очень эффективные результаты. То есть спам-фильтры
работают хорошо.
-
Неплохо работают методы определения пола автора.
-
Но есть и более лингвистические задачи – например, задача
референциального выбора. Пример текста про
футбольную команду "Манчестер Юнайтед" – одним и тем же цветом показаны
одинаковые референты, и видно, как по-разному они упоминаются в тексте.
Понятно, что в языке есть некая стратегия использования референциальных
выражений – в одних случаях будет использовано местоимение, в других –
полная именная группа и т.д. Изучать такие вещи помогает метод машинного
обучения.
-
На эту тему есть отечественные работы, например,
представленная в прошлом году на "Диалоге" совместная работа групп А.А. Кибрика и Н.В. Лукашевич по применению таких методов для изучения
механизмов референции. Для этого нужен специально подготовленный корпус,
в котором произведена уже достаточно сложная разметка, и мы пытаемся
изучить, какие параметры этой разметки существенны для референциального
выбора. Что здесь важно? То, что если вы изучаете референцию, вы не
можете работать только с сочетаемостью – так у вас ничего не получится.
Для того чтобы ваши выводы из применения машинного обучения были
эффективны, у вас должны быть адекватные параметры.
-
Не верьте тому, кто
говорит, что с помощью машинного обучения можно получить знание из чего
угодно, – это не так. Все зависит от того, какие параметры разметки
представлены в обучающем корпусе. Если у вас там только
последовательность символов и ничего больше – вы не сможете научиться
ничему серьезному. Выбор пишущего зависит от большого количества
факторов и имеет вероятностную природу.
-
Выдумать из головы те факторы,
которые существенны для референциального выбора, невозможно. То есть в
языке присутствуют такие механизмы, изучение которых "из головы"
попросту невозможно. Здесь на помощь приходит компьютерная лингвистика.
Нужные факторы должны быть представлены в корпусе в виде разметки,
потому что если у вас адекватный фактор попросту отсутствует, то вы не
можете ничему обучиться.
-
Здесь мне хотелось бы провести аналогию с компьютерной медициной.
Представьте себе, что в мире существует огромное количество медицинских
учреждений и очень много больных. Их лечили, есть история болезни.
Представьте себе, что мы пишем обучающую программу для средств
медицинской диагностики. Вполне понятная задача. Теперь представьте
себе, что вы решаете ее примерно так, как это чаще всего делается в
компьютерной лингвистике: берете в истории болезни только данные о
температуре, давлении и цвете кожных покровов. Какой-то результат вы
получите. Но вряд ли без доступа к УЗИ или сканированию сосудов вы
получили бы какую-то реальную диагностику. Сейчас в компьютерной
лингвистике методы машинного обучения работают «с температурой и
давлением», а мы хотели бы, чтобы они работали и со всем остальным. То
есть, на наш взгляд, возникает новая парадигма компьютерной лингвистики.
|
Дерев ья
принятия решений
|
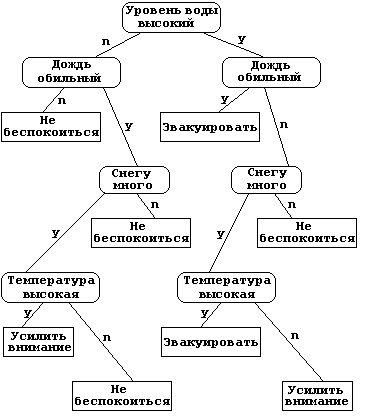
Дерево принятия
решений (Decision
tree
) — метод анализа
данных для прогнозных моделей.
Цель: создать
модель, которая предсказывает значение целевой переменной на основе
нескольких переменных на входе.
Структура дерева
представляет собой: «листья» и «ветки».
На ветках дерева
решения записаны атрибуты, от которых зависит целевая функция, в листьях
записаны значения целевой функции, а в остальных узлах — атрибуты, по
которым различаются случаи.
Чтобы
классифицировать новый случай, надо спуститься по дереву до листа и
выдать соответствующее значение.
Деревья решений
широко используются в интеллектуальном анализе данных.
Пример
(для
поискового ранжирования задачи - разбиения текста на предложения и
построения
сниппетов).
Сниппет
- небольшой отрывок текста из найденной поисковой машиной страницы
сайта, использующихся в качестве описания ссылки в результатах поиска.
В
некотором тексте есть потенциальный делитель - точка.
В
реальном Интернете (далеком от
литературного языка), очень много текстов, когда точка не
является знаком пунктуации "точка".
Поэтому нужно проанализировать контекст, который
находится около этой точки.
Пишется
анализатор, который начинает проверять простые правила:
-
есть ли пробел справа,
что говорит о том, что
это, скорее всего конец предложения.
-
есть ли большая
буква справа...
-
...................
-
таких правил на текущий момент около 40.
Необходимо скомбинировать
эти правила
между собой и произвести финальную оценку.
Здесь также применяется
машинное обучение
на деревьях
принятия решений.
Дерево принятия решений– бинарное дерево
с условием, которое проверяет, сработал или не сработал признак.
Признаки кодируются при помощи нуля и единицы.
Если признак не
сработал – нужно идти налево, если сработал – направо. После перехода может быть проверка нового
условия.
Получаются такие достаточно длинные цепочки условий,
оканчивающиеся листом дерева, в котором записывается вероятность
того, что это конец предложения.
Проблема
переобучения (с
ростом дерева рост качества замедляется и останавливается на недостаточном для решения задачи уровне)
преодолевается с помощью
бустинга.
Бустинг
(boosting — улучшение) — процедура последовательного построения
композиции алгоритмов машинного обучения, когда каждый следующий
алгоритм стремится компенсировать недостатки композиции всех предыдущих
алгоритмов. В течение последних 10 лет бустинг остаётся одним из
наиболее популярных методов машинного обучения.
Применение бустинга:
-
строится первое дерево, и для всех
элементов обучающего множества вычисляется ошибка.
-
строится
следующее дерево, только его задача уже не предсказывать концы
предложений, а указывать на ошибку предыдущего дерева.
-
по
цепочке, строится несколько десятков, а иногда и сотен деревьев.
-
получается достаточно гладкое решение.
|
Модель простейшей сети с одним слоем
|
Простейшая сеть с одним
скрытым слоем может быть представлена следующим образом:

На шаге 2 входной вектор значений X (набор чисел)
умножается на вектор весов W1, затем складывается с вектором смещений
B1, полученные значения весов передаются
сигма функции
возбуждения. Далее вычисленный вектор S1 умножается на веса скрытого
слоя W2 складывается с смещением B2, и вычисляется функция softmax которая
является ответом сети.
Этот же алгоритм в графическом виде можно (вычисление
идет снизу-вверх):
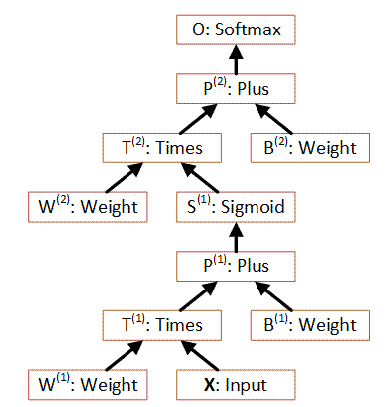
|
Sharky Neural Network
|
Sharky Neural Network -
приложение для демонстрации возможность
обучаемости нейросети.
SNN
позволяет
выбрать
общей вид
и модель работы
нейронной сети, другие параметры, после чего задать образ
распознания и понаблюдать за работой программы нейросети.
SNN
использует контролируемое машинное обучение с помощью алгоритма
обратного распространения ошибки.
Это
бесплатное программное обеспечение доступно на странице:
http://www.SharkTime.com
Нейронная сеть
SNN
относит
2D-точки
(вектора описывается двумя реальными
значениями: x и y) в два разных класса,
проводя визуализацию
данных пунктов (желтый и синий) классификации.
Нейроны
SNN
используют биполярный сигмоид функции
активации (f(x)=2/(1+e-βx)-1).
Пользователь может
добавлять, удалять, загружать или сохранять точки
обоих цветов (желтого и синего), очищать поле от точек.
Чтобы создать
логотип
"X"- нужно:
-
Ctrl + Левая Кнопка
Мыши
-
ввод множества точек
(режим спрея, распылителя)
-
[ -
уменьшение диапазона спрея
-
]
- увеличение диапазона спрея
-
заполнить синими
точками фон
в
режиме "спрей".
-
выбрать
подходящую структуру сети (закладка
Network
и раскрывающийся список Network
Structure),
-
настроить параметры обучения
(закладка
Learn)
-
нажать кнопку "Learn button".
Другие полезные сочетания клавиш:
-
F5 - Сброс сети.
-
F6 - Начать учить.
-
Esc - Перестать учиться.
|
PPAML
|
PPAML (Probabilistic Programming for Advanced Machine
Learning) -
новая (с
2013 г.) исследовательская
программа DARPA по вероятностному
программированию для машинного обучения.
DARPA
(Defense Advanced Research Projects Agency) — агентство
передовых оборонных исследовательских проектов Минобороны США.
К этлин
Фишер
(руководитель PPAML):
-
PPAML призвана сделать для
машинного обучения то, что появление языков высокого уровня
50 лет назад сделало для программирования в целом.
-
Не существует общепринятых
универсальных инструментов для создания интеллектуальных
систем. Из-за этого приходится постоянно изобретать
велосипеды (раз за разом реализовывать похожие алгоритмы, строить с нуля архитектуру).
-
Совокупность общих подходов и парадигм, используемых в машинном
обучении, получила название "вероятностное
программирование".
-
Инструменты, библиотеки и языки пока не
покидают стен университетов DARPA
намерено изменить эту ситуацию.
-
Среди целей программы — радикальное уменьшение трудоёмкости
создания систем машинного обучения, снижение порога
вхождения в программирование интеллектуальных приложений,
усовершенствование базовых алгоритмов машинного обучения,
максимальное использование современных аппаратных технологий
— многоядерных процессоров и GPU, облачных вычислений,
создание и стандартизация API для связи элементов
инфраструктуры машинного обучения в единую систему.
Здесь PDF с
кратким описанием программы.
Вероятностное программирование – ключ
к искусственному интеллекту?
http://habrahabr.ru/post/242993/
Классы
вероятностных языков программирования:
-
языки, допускающие задание генеративных моделей только в форме Байесовских
сетей (или других графических вероятностных моделей). Не открывая
возможности решения принципиально новых решений задач, является
высокоэффективным инструментом использования графических моделей.
Пример: язык
Infer.NET
(от Microsoft).
Большинство задач машинного обучения могут быть сформулированы в Байесовской
постановке
см.
байесовское программирование
-
Тьюринг-полные языки (позволяют выйти за рамки того класса задач, которые
существующие методы машинного обучения уже умеют решать). Проблема
эффективности вывода в таких языках, приводит к плохой масштабируемости на
задачи реального мира. Перспективны в исследованиях, связанных с когнитивным
моделированием и общим искусственным интеллектом.
Пример: язык
Church
(Чёрч, расширение диалекта Scheme для языка Лисп) с web-реализацией (web-church)
позволяющей экспериментировать без установки дополнительного программного
обеспечения.
|
Вероятностное программирование
|
Вероятностное программирование
- способ представления порождающих
вероятностных моделей и проведения статистического
вывода в них с
учетом данных с помощью обобщенных алгоритмов.
В
«обычном» программировании основой является алгоритм, обычно
детерминированный, который позволяет нам из входных данных
получить выхоные по четко установленным правилам.
Однако
часто мы зная только результат, заинтересованы в том, чтобы
узнать приведшие к нему неизвестные (скрытые) значения.
Для этого (с
помощью теории математического моделирования) создается
вероятностная модель, часть параметров которой не определены
точно.
В
машинном обучении (для решения задач вероятностного
программирования) используются
порождающие вероятностные модели, где модель
описывается как алгоритм, но вместо точных однозначных
значений скрытых параметров и некоторых входных параметров
мы используем вероятностные распределениях на них.
|
"обычное"
программирование |
вероятностное
программирование |
|
 |
 |
К лассы
вероятностных языков программирования:
-
языки, допускающие задание генеративных моделей только в форме Байесовских
сетей (или других графических вероятностных моделей). Не открывая
возможности решения принципиально новых решений задач, является
высокоэффективным инструментом использования графических моделей.
Пример: язык
Infer.NET
(от Microsoft).
Большинство задач машинного обучения могут быть сформулированы в Байесовской
постановке
см.
байесовское программирование
-
Тьюринг-полные языки (позволяют выйти за рамки того класса задач, которые
существующие методы машинного обучения уже умеют решать). Проблема
эффективности вывода в таких языках, приводит к плохой масштабируемости на
задачи реального мира. Перспективны в исследованиях, связанных с когнитивным
моделированием и общим искусственным интеллектом.
Пример: язык
Church
(Чёрч, расширение диалекта Scheme для языка Лисп) с web-реализацией (web-church)
позволяющей экспериментировать без установки дополнительного программного
обеспечения.
Языки
вероятностного программирования
(перечень с
кратким описанием каждого) здесь.
См. Вероятностное программирование – ключ к искусственному
интеллекту?
http://habrahabr.ru/post/242993/ |
ML на векторных моделях
|
Для обучения
нейронных сетей без учителя могут использоваться
представления слов в виде векторов в многомерном
пространстве.
Оценка
подобия (степени их совместного появления) слов на основе
данного векторного
представления используются в области машинного
перевода.
На рисунке: линейные
отображения векторных
представлений слов английского и испанского
языков спроецированы на двухмерное пространство с помощью метода
PCA
(principal component analysis, главных компонентов), а потом повернуты,
чтобы подчеркнуть сходство структур в двух языках.
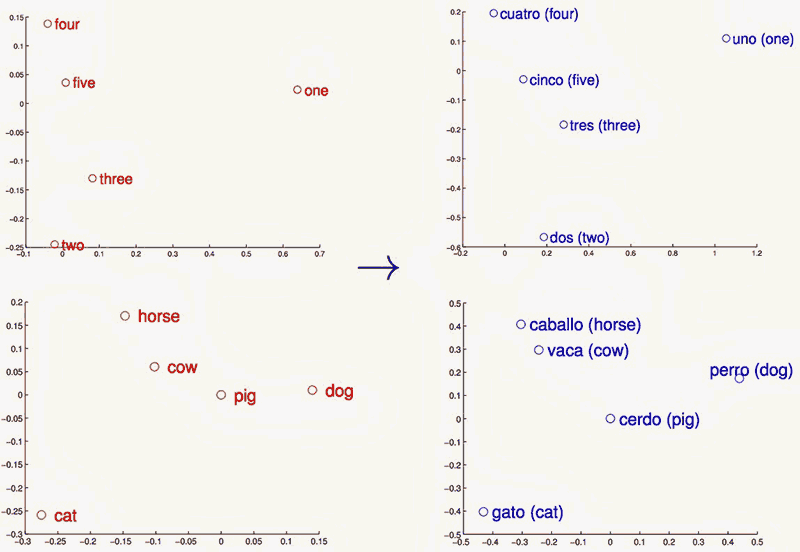
|
Machine Learning для формальных задач
|
17.10.2014
На сайте электронных препринтов arXiv.org
опубликована
статья ( Learning to Execute, Илья Сутскевер
и др. из Google)
с описанием результатов обучения нейронной сети пониманию текстов
программ.
Дмитрий Ветров
(специалист по ML,
к. ф.-м. н., рук. исследовательской группы
байесовских методов, нач. департамента больших данных и информационного
поиска факультета компьютерных наук НИУ ВШЭ.):
-
Нейронные сети успешно, если не сказать блестяще, показали себя в ряде
задач, традиционно считавшихся трудными для алгоритмов машинного обучения
(понимание изображений, распознавание речи, обработка текстов). Все эти задачи связаны
с анализом плохо формализуемой информации, в которой человек традиционно
ориентируется лучше компьютера.
-
Google,
сманивший к себе значительную часть ведущих мировых специалистов по
глубинному обучению нейросетей, явно пытается нащупать границы области
применимости методов глубинного обучения по большим объемам данных.
-
Решено было проверить, насколько нейронные сети способы решать задачи из противоположного спектра и
понимать четкие формальные инструкции программного кода? Такая задача
кажется даже более сложной для нейронной сети:
-
текст программы, как и
положено формальному описанию алгоритма на синтетическом
языке программирования, содержит минимальную избыточность,
поэтому небольшие изменения в нем, например изменение знака
«плюс» на знак «минус», будут приводить к сильным изменениям
выхода программы, а в традиционных задачах машинного обучения предполагается, что небольшие
изменения входных данных должны приводить к небольшим изменениям прогноза
(гипотеза компактности). Именно это предположение лежит в основе современных
моделей обучения и их способности обобщить результаты
обучения с известной обучающей выборки объектов на
произвольные данные, которые в каком-то смысле близки к
объектам обучающей выборки.
-
с точки зрения нейронной сети
текст программы — это просто набор символов, не имеющих
априори никакого смысла.
-
Авторы статьи использовали один из видов рекуррентных нейросетей с Long-Short Term Memory. Эта архитектура хорошо зарекомендовала
себя при анализе и генерации текстов на естественных языках. Она
представляет собой двуслойную динамическую нейросеть с блоком памяти
(внутренним набором переменных, значения которых влияют на поведение сети в
конкретный момент времени). Такая нейронная сеть просматривает текст
программы символ за символом, анализируя не только текущий наблюдаемый
символ, но и принимая во внимание выходы нейронов с разных слоев в
предыдущий момент времени (короткая память), а также значения переменных в
блоке памяти (длинная память). Целью обучения является минимизация ошибки
между результатом исполнения кода программы и выходом нейронной сети,
просмотревшей текст программы.
-
Авторы ограничили рассмотрение программами линейной
сложности по длине кода (то есть не содержащих рекурсии, вложенных циклов и
вызовов подпрограмм), справедливо полагая, что это слишком высокие уровни
абстракции для современных нейронных сетей (да и для многих людей тоже, как
показывают результаты экзаменов по технологиям программирования в
университетах).
-
Авторами был разработан специальный генератор текстов
программ, позволивший им создавать сколь угодно большие обучающие выборки
текстов программ варьируемой сложности.
Результаты экспериментов:
-
в ряде случаев нейронные сети действительно научились выдавать тот же ответ,
что и настоящие простые программы программа. Качество быстро падает при незначительном
усложнении/удлинении текста программы.
-
Вряд ли нейросети научились
правильно опознавать и сопоставлять алгоритмические блоки. Скорее речь идет о выучивании отдельных паттернов текстов программ
без понимания их смысла. Такой подход хорошо работает при обработке данных,
обладающих значительной избыточностью, например изображений или текстов на
естественном языке, но плохо применим для анализа формальных инструкций.
-
продемонстрировано, что при неограниченном объеме обучающей информации
нейронные сети
способны улавливать фантастически сложные скрытые закономерности в данных.
-
авторами предложен ряд
эвристических процедур, которые позволяют улучшить качество
обучения в условиях нетривиальных зависимостей, скрытых в
данных, и возможности варьировать их сложность в ходе
обучения — так называемая комбинированная процедура
обучения.
-
Данная статья
представляет собой очередной типичный пример научных статей от Google. Ряд
деталей реализации и планирования эксперимента в статье, как и во многих
других статьях сотрудников этой корпорации, опущен. Описание нетривиальной
математической модели занимает 12 строчек и одну формулу.
-
Приходится с
сожалением констатировать, что исследователи Google, пользуясь доступом к
практически неограниченным вычислительным возможностям, не утруждают себя
тем, чтобы описание их действительно очень интересных и нетривиальных
исследований допускало воспроизводимость независимыми научными группами.
|
RNN и LSTM в распознавании
речи и текста
|
С возникновением идеи рекуррентных сетей
появилась надежда на то что будет качественно решена
задача распознавание речи и текста на
естественных языках.
Рекуррентные сети (RNN)
позволяют помнить предыдущее состояние, тем самым снижая количество
данных подаваемых на вход сети.
Необходимость «зацикливания» и «обладания
памятью» нейронных сетей обусловлена тем, что данные голоса или текста
невозможно подать на вход сети в полном объёме, они возникают некоторыми
порциями, разделенными во времени.
Близкими в этом контексте являются
LSTM
сети, для которых разработан специальный тип нейронов, переводящий себя
в возбужденное состояние на основе некоторых значений и не меняющий его
пока на вход не придет деактивационый вектор.
LSTM сети в том числе помогают решить
задачу преобразования последовательности в последовательность
возникающую при переводе одного языка на другой.
Возможности RNN и LSTM сетей в некоторых
случаях уже превосходят человека в распознавании коротких фраз и
рукописного ввода.
|
Azure ML
Studio
|
18.01.2016
Теоретическая часть машинного обучения требует глубокой математической
подготовки, что делает снижает популярность его инструментария среди
разработчиков.
Однако практическое использование машинного обучения в собственных
приложениях может быть достаточно простой задачей.
Azure
Machine Learning
– это облачная инструментальная среда разработки:
-
предоставляющая десятки
готовых алгоритмов машинного обучения – от простейшего
алгоритма линейной регрессии, до сложных и
специализированных
-
позволяющая в простой и
наглядной форме
-
с помощью готовых
компонентов
машинного обучения
-
собрать необходимый
процесс обработки данных
-
провести
экспериментальную проверку их эффективности
-
и в случае успеха
опубликовать все в виде сервиса
-
распространяя и монетизируя
полученные модели
-
посредством использования из
в мобильных приложениях
Построение модели машинного обучения в
Azure ML
Studio:
-
Определение
задачи (требуемого
результата)
-
Загрузка данных
(или использование готовых
данных репозитариев)
-
Создание нового эксперимента
-
Формирование выборки данных для дальнейшего обучения модели
-
Подготовка данных (формирования
характеристик, удаления выбросов и разделения выборки на
обучающую и тестовую.
-
Выбор моделей данных и
соответствующих алгоритмов обучения, которые могут дать
требуемый результат.
-
Обучение модели (поиск
скрытых закономерностей в выборке данных с целью отыскания
способа предсказания алгоритмом обучения на основе выбранной
модели).
-
Оценка модели (исследование
ее прогностическиз характеристик на тестовой выборке и
замеры уровеней ошибок.
-
Принятие модели в качестве
итоговой или повторное обучение после добавления новых
входных характеристик или изменения алгоритма обучения.
-
Публикация веб-сервиса
-
Тестирование сервиса
-
Разработка приложения
-
Мониторинг и монетизации модели
|
CNTK на
Github
|
В 2015 году многие
крупные компании опубликовали на Github свои разработки:
-
Google - TensorFlow,
-
Baidu -
warp-ctc.
-
Microsoft выложила в открытый доступ на
Github
исходный код
Computational Network Toolkit
- набора инструментов,
для проектирования и тренировки сетей
различного типа, которые можно использовать для распознавания
образов, понимания речи, анализа текстов и многого другого.
Computational Network Toolkit
победила в конкурсе ImageNet LSVR 2015 и
является самой быстрой среди существующих конкурентов.
Computational Network Toolkit является
попыткой систематизировать и обобщить основные подходы по построению
различных нейронных сетей, снабдить ученых и инженеров большим набором
функций и упростить многие рутинные операции. CNTK позволяет создавать сети
глубокого обучения (DNN),
сверточные сети (CNN),
рекуррентные сети и сети с памятью (RNN,
LSTM).
CNTK помогает решить задачи инфраструктурного
характера, в частности, у него уже есть подсистемы чтения данных из
различных источников. Это могут быть текстовые и бинарные файлы, изображения,
звуки.
Ядро CNTK создано на языке C++, но
предполагается создать интерфейсы на
Python bindings и C# .
Подробно о возможностях
и функциях CNTK: An
Introduction to Computational Networks and the Computational Network Toolkit.
Об использовании
CNTK узнать из CNTK
Wiki.
Краткое введение в CNTK в
материалах
NIPS 2015 опубликовано
здесь
Примеры
наиболее распространенных подходов
в решении задач применимых к нейронным сетям в папке
В CNTK входит несколько примеров анализа
речи, на основе
AN4 Dataset, Kaldi
Project, TIMIT,
и проект по трансляции на основе
работы.
Анализ текста представлен проектами по
анализу комментариев, новостей, и произнесенных фраз (spoken language
understanding,
SLU).
24.01.2016
Microsoft выложила в открытый доступ на
Github
исходный код
Computational Network Toolkit
- инструментов, которые используются в компании для глубинного обучения
в области искусственного интеллекта
(проектирования и тренировки сетей различного типа, которые можно
использовать для распознавания образов, понимания речи, анализа текстов
и многого другого).
 Сюэдун
Хуан
(Xuedong Huang, ведущий специалист Microsoft по системам распознавания
речи): Сюэдун
Хуан
(Xuedong Huang, ведущий специалист Microsoft по системам распознавания
речи):
-
Разработчики
в моей группе были озабочены проблемой, как ускорить процесс
распознавания речи компьютерами, а имеющиеся инструменты работали
слишком медленно. Поэтому группа добровольцев вызвалась решить
проблему самостоятельно, используя собственное решение, которое
ставило производительность на первое место.
-
Усилия окупились сполна. Во внутренних тестах
CNTK показал более
высокую производительность,
чем другие популярные вычислительные инструментарии, которые
разработчики используют для создания моделей глубинного обучения в
задачах вроде распознавания речи и распознавания образов, за счёт
лучших коммуникационных возможностей. Инструментарий CNTK просто
невероятно более эффективен, чем всё, что нам доводилось видеть
В компании Microsoft инструментарий CNTK используется на кластере
компьютеров для обработки алгоритмов синтеза и распознавания речи,
распознавания изображений и движения на видео.
|
"Войны" нейронных сетей
Generative adversarial networks
(GAN) -
соперничающие нейронные сети
-
Есть две нейронных сети. Первая сеть,
порождающая, обозначим ее как функцию yG=G(z),
на вход она принимает некое значение z,
а на выходе выдает значение yG.
Вторая сеть, различающая, и мы ее обозначим как функцию yD=D(х),
то есть на входе — x,
на выходе — yD.
-
Порождающая сеть должна научиться
генерировать такие образцы yG,
что различающая сеть D не
сможет их отличить от неких настоящих, эталонных образцов. А
различающая сеть, наоборот, должна научиться отличать эти
сгенерированные образцы от настоящих.
-
Изначально сети не знают ничего, поэтому
их надо обучить на основе набора обучающих данных — (Xi,
Yi).
На вход сети последовательно подаются Xi и
рассчитываются yi=N(Xi).
Затем по разнице между Yi (реальное
значение) и yi (результат
работы сети) перерассчитываются коэффициенты сети и так по
кругу.
На каждом шаге обучения вычисляется значение функции потерь (loss
function), по градиенту которой потом пересчитываются
коэффициенты сети. А вот функция потерь уже учитывает отличие Yi от yi.
-
Вместо минимизации функции потерь в ходе
обучения сети можно решать другую оптимизационную задачу -
максимизации функции успеха. И это используется в
GAN.
-
Обучение первой, порождающей, сети
заключается в максимизации функционала
D(G(z)). То есть эта сеть стремится
максимизировать не свой результат, а результат работы второй,
различающей, сети.
-
Порождающая сеть должна научиться для любого значения, поданного
на ее вход, сгенерировать на выходе такое значение, подав
которое на вход различающей сети, получим максимальное значение
на ее выходе (а это означает, что порождающая сеть порождает
правильные образцы).
-
Порождающая сеть будет учиться по
градиенту результата работы различающей сети.
-
Обучение различающей сети заключается в
максимизации функционала
D(x)(1 — D(G(z))). Она должна выдавать
1 для эталонных образцов и 0 для образцов, сгенерированных
порождающей сетью. Причем сеть ничего не знает о том, что ей
подано на вход: эталон или подделка. На каждом шаге
обучения различающей сети один раз рассчитывается результат
работы порождающей сети и два раза — результат работы
различающей сети: в первый раз ей на вход подается эталонный
образец, а во второй — результат порождающей сети.
-
Обе сети связаны в неразрывный круг
взаимного обучения. И чтобы вся эта конструкция работала нам
нужны эталонные образцы — набор обучающих данных(Xi).
Заметьте, что Yi здесь
не нужны. Хотя, понятно, что на самом деле по умолчанию
подразумевается, что каждому Xi соответствует Yi=1.
-
В процессе обучения на вход порождающей
сети на каждом шаге подаются какие-то значения, например,
совершенно случайные числа (или совсем даже неслучайные числа —
рецепты для управляемой генерации). А на вход различающей сети
на каждом шаге подается очередной эталонный образец и очередной
результат работы порождающей сети.
-
В результате порождающая сеть должна
научиться генерировать образцы как можно более близкие к
эталонным. А различающая сеть должна научиться отличать
эталонные образцы от порожденных.
|
A Visual and Interactive Guide to the Basics
of Neural Networks
TensorFlow
|
TensorFlow
- это библиотека с открытым исходным кодом программного обеспечения для
численных расчетов с помощью диаграмм потока данных. TensorFlow
предназначена для студентов, исследователей, любителей, хакеров,
инженеров, разработчиков, изобретателей. TensorFlow стремится стать
одним из лучших инструментарием для машинного обучения в мире и создать
открытый стандарт для обмена научными идеями в области нейронных сетей и
машинного обучения.
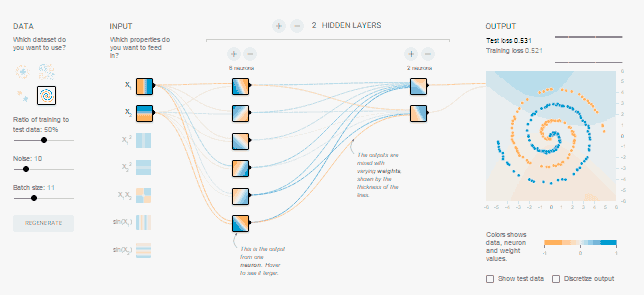
Для знакомства с работой нейронных сетей и экспериментов в области
машинного обучения
TensorFlow
предоставляет
Учебную нейросеть,
которая может быть использована непосредственно в браузере (в том
числе для реальных
приложений за счет связей с ресурсами библиотеки
TensorFlow).
Доступны
любые, предусмотренные
Apache License, применения
Учебной нейросети.
Учебная нейросеть:
-
имеет
входы и выходы,
-
реализует между нейронами,
-
содержит скрытые слои, в которых отображены весовые коэффициенты
межнейронных связей.
-
задается наборами входных данных
-
позволяет задавать уровень шума
(аналога дискурсивного наречия "почти")
-
содержит
простейшие средства управления процессом обучения.
«Удачные» связи отмечаются на обучаемых слоях синим, неудачные –
оранжевым.
П ри
всей кажущейся простоте варьирования параметров Учебной нейросети,
ее обучение не столько ремесло и наука, сколько искусство.
выращивания ИИ на простейшей когнитивной модели
Работе с нейросетями надо учиться.
Учебная нейросеть
инструмент, который дает возможность
поэкспериментировать с нейросетями и получить нужные для этого навыки.
30.03.2018
Состоялся
TensorFlow Developer Summit, 2018
Из нового:
|
Решения
DeepMind
|
DeepMind
основана в 2010 году в Лондоне, в 2014 году приобретена Google за $500
000 000.
Одним из условий сделки DeepMind с Google
было создание последней коллегии по этическим проблемам искусственного
интеллекта.
Цель компании — «решить проблему интеллекта»,
реализовать его в машинах и понять, как работает мозг человека.
Демис Хассабис
(основатель
DeepMind):
В начале
обучения система ИИ DeepMind ничего не знает о правилах игры и учится играть
самостоятельно, используя на входе только пиксельное изображение
игры и информацию об очках, получаемых в ходе игры. В основе ИИ
лежит глубинное
обучение с подкреплением (deep Q-network (DQN)) -
вариация обучения с подкреплением без модели с применением
Q-обучения, в котором функция полезности моделируется с помощью
глубинной нейронной сети. В качестве архитектуры нейросети выбрана
свёрточная нейронная сеть.
В
2015 AlphaGo от победила
DeepMind в го лучших игроков.
В
2017 AlphaZero в течение 24 часов достигла сверхчеловеческого уровня игры в
шахматы, сёги, и го, победив чемпионов мира среди программ.
Гарри
Каспаров:
-
AlphaZero - большой плюс для шахмат. Бояться этого не
надо: "Человек же не соревнуется в скорости с автомобилем. И
шахматистам искусственный интеллект не помешает играть друг с
другом. Главное - наслаждаться красотой шахмат.
-
С
помощью AlphaZero мы будем всё больше и больше открывать шахматы. Находка
ярко демонстрирует несовершенство наших шахматных знаний. Я смотрю партии и думаю: как много,
оказывается, я не понимаю! Выясняется, что какие-то идеи, которые
раньше считались неоспоримыми, могут не работать! Очень
увлекательно.
Публикации DeepMind затрагивают следующие темы: понимание
естественного языка машинами, генерация изображений по шаблону с
помощью нейронных сетей, распознавание речи, алгоритмы обучения
нейронных сетей.
В
2016 начато сотрудничество с Blizzard для обучения ИИ в Starcraft II.
Ведется работа над «Starcraft 2 API», которая позволяет ИИ полностью
взаимодействовать с интерфейсом игры, принять участие в разработке
может любой желающий |
Хм...
|
03.06.2016
-
Warner
Bros. отправили
уведомление видеохостингу Vimeo о нарушении авторских прав
согласно Закону об авторском праве в цифровую эпоху (Digital
Millennium Copyright Act, DMCA) и список нелегально закачанных
видеоматериалов, правами на которые владеет Warner. Заявление
было отозвано из-за ошибки - часть видео была не взята из фильма, а
в рамках проекта
Теренса
Броуда
[Terence Broad] воссоздана с помощью машинного обучения. Warner не
смогла отличить симуляцию и настоящую вещь.
Теренс Броуд
учил нейросеть смотреть кино – не так, как это делают люди, но так,
как это подходит машине. Научившись распознавать данные фильма,
кодировщик уменьшил каждый кадр до представления в виде числа из 200
цифр, и затем реконструировал это число обратно в новые кадры, с
целью добиться совпадения с оригиналом. Версия фильма от нейросети
полностью уникальна и создана на основе того, что она увидела в
оригинальном фильме – это интерпретация фильма системой основанная
на ограниченном понимании.
|
|