Удо Хан
(профессор университета Фрайбурга
(Германия):
Искусство краткого изложения материала, иными словами,
извлечения наиболее важных или характерных
фрагментов из одного или многих источников
информации, стало неотъемлемой частью повседневной
жизни.
Мир
перенасыщен требующей
внимания человекаинформацией,
изучить которую выше его
возможностей.
Результаты
исследования IBM:
При информационном
избытке,
важные решения
топ-менеджеров основаны только на
7% необходимой
и доступной
информации.
В ситуации
"информационной усталости" и "информационного загрязнения"
становятся востребованы технологи
и
Data Mining.
Data Mining
Data Mining
(интеллектуальный
анализ данных)
- технологии оперативного анализа
информации, полученной по запросу для выбора дальнейшего направления ее
исследования.
Data Mining
востребованы растущим количеством требующей
внимания человека информации,
обработать которую становится выше человеческих возможностей.
В современных системах используется
двухуровневая технология аналитической обработки:
Knowledge Discovery
(обнаружение знаний) -
извлечение семантически значимых релевантных данных
из контента массива документов.
Примеры систем Data Mining:
ClearForest,
Convera RetrievalWare,
Hummingbird KM,
Медиалогия.
Медиалогия
Компания "
Медиалогия"
(http://www.mlg.ru/) - поставщик
Data Mining-решений
онлайн-анализа СМИ, ежедневно собирает и
обрабатывает материалы более
15 814
СМИ,
включая прессу, ТВ и др.
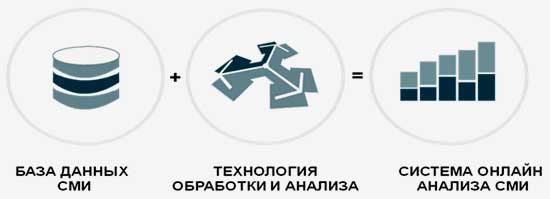
Система "Медиалогия"
состоит из базы данных СМИ и
аналитического модуля обработки и анализа
сообщений и формирует ИИБ .
ИИБ
- (Индекс Информационного Благоприятствования) -
показатель
оценки медиа-репутации компании, бренда или персоны,
на осове
качественного анализа упоминаемости объекта в СМИ с
учетом влиятельности источника, характера и яркости
упоминания.
Расчет ИИБ учитывает множество параметров, в
том числе:
влиятельность источника (индексы
цитируемости и качества
аудитории);
характер упоминания (позитивный, негативный,
нейтральный);
роль объекта в сообщении (главная, второстепенная,
эпизодическая);
наличие прямой или косвенной речи объекта-персоны, представителей объекта;
степень конфликтности контекста
упоминания объекта.
Применение ИИБ:
анализ влияния СМИ на медиа-репутацию компании;
анализ динамики изменения медиа-репутации
компании;
анализ эффективности PR-кампаний;
сравнение медиа-репутации конкурентов;
отслеживание негативных упоминаний в СМИ;
анализ СМИ в условиях информационных войн и
кризисов.
Text Mining
Text Mining -
та же добыча радия. В грамм добыча, в год труды,
Изводишь единого слова ради тысячи тонн словесной
руды.
Владимир
Маяковский,
первый теоретик Text Mining
До 85% новых знаний
аналитики до сих пор получают, изучая тексты.
Text Mining (интеллектуальный
анализ текста) - частный случай технологий Data Mining.
Text Mining основан на
алгоритмическом выявлении прежде не известных связей
и корреляций в текстовых данных,
извлечении из текста его характерных элементов или
свойств, которые могут использоваться как метаданные
документа, ключевых слов, аннотаций.
Области применения
Text Mining:
автоматической рубрикации документов,
интеллектуального
(семантического) поиска,
составления
авторефератов,
борьбы со спамом и
т.д.
Примеры систем Text Mining:
Intelligent Miner for Text (IBM);
Text Miner (SAS);
Oracle Text (Oracle);
Galaktika-ZOOM (корпорация "Галактика").
Основные задачи Text Mining
классификация (classification,
разбиение документов по заранее определенным
разделам),
кластеризация (clustering,
разбиение документов на группы, когда принципы
группировки заранее неизвестны),
построение
семантических сетей (выявление связейдескрипторов (ключевых
фраз) в документе),
извлечение фактов,
понятий (feature extraction),
суммаризация (summarization,
аннотирование и реферирование документов),
ответ на запросы (question answering),
тематическое индексирование (thematic indexing),
извлечение терминологии,
распознавание
именованных элементов,
аазрешение анафоры и кореференций
(поиск связей, относящихся к одному и тому же
объекту).
поиск по ключевым словам (keyword searching).
Извлечение информации из текста
В иной, традиционной, парадигме развивается направление
information extraction.
Извлечение информации (information
extraction) — задача автоматического построения
структурированных данных из неструктурированных
или слабоструктурированных машиночитаемых
документов.
Тексты
на естественном языке могут потребовать некоего предварительного преобразования
на язык (например, RDF — Resource Description Framework), понятный для
компьютера.
Извлечение информации является
разновидностью информационного поиска.
Значение и
звлечения
информации, всё больше возрастает — из-за стремительного увеличения количества
неструктурированной (без метаданных) информации в Интернете.
Эта информация может быть сделана
более структурированной посредством добавления XML разметки.
Современные подходы извлечения информации используют
методы обработки естественного языка, направленные
лишь на ограниченный набор тем.
Крупномасштабный контент-анализ
15.12.2010
Международная группа исследователей провела первый в своём роде
крупномасштабный контент-анализ многоязычных текстов с использованием
искусственного интеллекта.
Системы машинного перевода и текстового анализа
проанализировали 1
370 874 статьи на 22 языках, увидевших свет в 27 странах с 1.08.2009 по 31.01.2010.
Неанглоязычных
- 1,2 млн.
Джастин Льюис
(Justin
Lewis,
проф.
Кардиффского университета,
Великобритания):
Такой подход способен революционизировать наше представление о средствах
массовой информации и информационных системах. Открывается возможность анализа медиасферы в глобальном масштабе с
огромным количеством материала. Кроме того, подход позволяет нам
использовать автоматизированные средства для выявления содержательных
кластеров и шаблонов и тем самым выходить на новый уровень объективности
анализа.
Выяснилось: Европейские СМИ отбирают информационные поводы на основе
национальных предубеждений, а
также культурных, экономических и
географических связей между странами.
Результаты в http://www.plosone.org/article/info:doi/10.1371/journal.pone.0014243).
Эволюция языка за 200 лет
17.12.2010
Ученые приспособили поисковый сервис Google для
проведения масштабных лингвистических исследований.
С его помощью,
используя 5,2 миллионов отсканированных книг
(на английском, французском, испанском, немецком, китайском и русском языках),
составлена база всех использованных в них слов (около 500
миллиардов).
В частности установлено, что за последние
100 лет
число часто используемых слов возросло вдвое (в 1900 году использовалось
около 544 000 слов, то в 2000 году до одного миллиона,
причем 52% новых слов стало активно употребляться после 1950-х годов).
Авторы и их коллеги полагают, что новый инструмент позволит ученым
исследовать слова и лингвистические тенденции, используя те же подходы и методы,
что и специалисты по естественным наукам.
выявлять источники угроз как со стороны внешнего окружения, так и внутри
компании. Формировать досье на физические и юридические лица.
Automatic Text Summarization
Automatic Text Summarization
(автоматическое реферирование)
- технология в составе
Text Mining.
Automatic Text Summarization
- программыавтоматического
составления рефератов, на основе оценки информативности (веса,
важности для описания содержимого текста)
элементов текста (имен, слов, предложений, фрагментов)с использованием формальных статистических и
лингвистических методов.
Реферат
- краткое изложение содержания текста.
Автореферат -
краткое
изложение содержания текста сделанное самим автором или машиной.
Статистические критерии оценки информативности:
частотный (частота встречаемостиэлемента в реферируемом тексте);
позиционный
(учет местоположенияэлемента в тексте
(в заглавии, заголовке);
синтаксический (учет синтаксических связей между
предложениями);
прагматический (повышенный вес получают термины -
имена собственные)
;
металексический (учет не только единичных терминов, но и словосочетаний).
Коэффициент сжатия
автореферата - процент отбора предложений исходного текста.
Отобранные в реферат предложения преобразуются для придания
большей связности результирующему реферату.
Качество
автореферата зависит от структурированности исходного
текста.
Примеры
систем автореферирования:
Inxight Summarizer
(использует
несколько алгоритмов
реферирования);
eXtragon
(ориентирована на аннотирование Web-документов);
TextAnalyst
(работает только с русским языком, выделяет именные группы и строит
структуру взаимозависимостей между ними);
Аннотатор
(работает с русским и английским
языками в среде Microsoft Word).
Copernic Summarizer
(коммерческая, есть бесплатная пробная версия, работает
с английским языком,
интегрируется в Internet Explorer, Netscape Navigator, Adobe
Acrobat, Acrobat Reader, Outlook Express, Microsoft Word).
Для
авторефереривания достаточно иметь подключение к Сети.
VisualWorld(http://www.visualworld.ru)
- бесплатный Web-сервис для реферирования текстов (выделения основных смысловых предложений).
Чтобы получить автореферат, надо воспользоваться одной из трех возможностей:
поместить текст в форму на Web-страничке;
указать адрес документа в Интернете;
загрузить на сайт документ со своего компьютера.
Поддерживаются документы
на русском и английском языках следующих форматов: Microsoft Word (doc, docx), Rich Text (rtf), Adobe Acrobat (pdf), текстовый файл (txt) или HTML-файл.
Размер файлов не должен превышать: 500 кб (doc, docx, rtf, pdf), 100 Кб (txt, html).
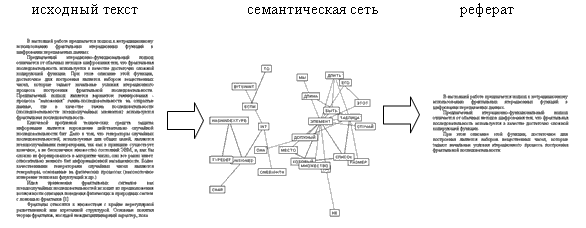
Сервис автореферирования VisualWorld использует
оригинальный авторский алгоритм построения семантической сети (ассоциативного
облака) по тексту, фильтрации семантической сети от малозначимых элементов и
обратного преобразования семантической сети в текст.
Test The Text: текст в
информационном стиле
Цель текста в информационном стиле — донести информацию до
читателя.
В информационных текстах нет лишних слов, эмоций, личного
мнения. Они читаются легко и быстро.
Test The Text выделяет в тексте слова нехарактерные для
информационного стиля и объясняет что с ними делать.
В настоящий моментBlackBerry
испытываетвесьмасерьезныепроблемы
—никомуне
понравился их первый флагманский телефон,один
изсо-основателей
сделал ставку натемную
лошадку, чтобы выкупить компанию, асамакомпанияможетбыть
разделена между участниками торгов, предлагающиминаиболеевысокиецены.
BlackBerry испытывает проблемы.
Продажи флагманского смартфона Z10 провалились.
Компанию распродают по частям на аукционе. Даг
Фрегин, со-основатель компании, пытался выкупить ее
инкогнито.
Текст стал на 37% короче и на 33%
информативнее
Сервис
Test The Text
ищет в тексте «стоп-слова», которых
журналисту следует избегать – междометия, модальные глаголы,
клише и канцеляризмы. Инструмент выделяет эти слова красным
цветом и дает автору повод поразмыслить над информативностью
своего текста.
AutoSummarize
(Автореферат,
из меню
Сервис)
- функцияавтоматического составления реферата документа
в
MS Word 97
и
MS Word 2003.
AutoSummarizeработает только
для английского языка
(для работы с русским надо по умолчанию установить Английский
(команда Язык в меню
Сервис):
Выберите команду
Язык в меню Сервис
и установите Английский (по умолчанию).
Выберите команду
Автореферат в меню Сервис.
Выберите необходимый тип реферата.
Введите нужную степень детализации в поле Процент от оригинала или выберите ее из списка.
Чтобы запретить изменение имеющихся заметок и ключевых слов, на вкладке Документ в диалоговом окне Свойства (меню Файл) при создании автореферата, снимите флажок Обновить сведения о документе.
Для работы с авторефератом
удобно использовать панель инструментов Автореферат,
которую можно вызвать
нажав клавишу ALT, а затем клавиши SHIFT+F10.
AutoSummarize не гарантирует получения осмысленного или удобочитаемого текста, но
дает пользователю добротную основу для начала работы над реферированием объемного документа.
В версии
MS Word 2007
AutoSummarizeвызывается так:
нажмите кнопку Office, затем Word options (Параметры Word);
выберите пункт Customize (Настройка);
в ниспадающем меню Choose commands from (Выбрать команды из), находящемся в левой верхней части экрана, выберите пункт Commands Not in the Ribbon (Команды не на ленте);
в находящемся ниже списке выберите пункт AutoSummary Tools (Автосуммирование) и нажмите кнопку Add (Добавить);
активизируйте функцию AutoSummarize
из инструментальной панели быстрого доступа.
Наилучшие
результаты
AutoSummarize
дает при работе с документами, имеющими четкую структуру.
Для подготовки
правильно структурированного документа в MS Word удобно воспользоваться
инструментами Структура (из меню Вид).
Увы, в версии
MS Word 2010
AutoSummarizeне
используется :(
Квантовая математика в поиске ключевых слов
0
6.04.2009
Самый простой метод поиска ключевых слов в тексте основан на частоте его повторения.
Затем частота того же слова определяется для некоторого базового текста,
привязанного к изучаемому. Если частота в
исходном тексте оказывается выше, чем в базовом, то слово признается ключевым.
Ученые предложили
считать не только частоту вхождения слов, но их группировку, полагая,
что более важные слова обычно группируются автором вместе, в тех частях текста,
где он пытается донести основную мысль, а менее значимые слова
более равномерно распределены в тексте.
Для описания данной идеи использовалась
теория случайных матриц - раздел теории вероятности и статистики.
Метод опробован в нескольких известных текстах на
английском, немецком, испанском, итальянском языках и латыни. Опыт
оказался успешным. Список изучавшихся текстов доступен
Бенджамин Фунг
(Benjamin Fung, профессор инженерных информационных систем
университета Concordia (Монреаль)) создал эффективную
технологию идентификации отправителя на основе текстов
электронной почты, которая является доказанным экспертным
заключением и может быть использована в суде.
Доктор Фунг использовали методы, которые используются в
распознавании речи и интеллектуальном анализе данных с целью
выявления отличительных особенностей комбинаций, которые
повторяются в письмах подозреваемого.
Анализируя грамматические и стилистические ошибки, регистр
текста письма, манеру обращения, средства форматирования
текста и его объем, другие уникальные особенности программа
с высокой вероятностью определяеть пол, национальность,
возраст, уровень образования автора электронного письма.
Исследователи проанализировали коллекцию из 200 000 реальных
писем от 158 сотрудников Enron Corporation. Точность
идентификации составила 90%.
Бенджамин Фунг:
Это — результат
междисциплинарного исследования. В разработке метода
идентификации принимали участие эксперты электронной
судебной экспертизы. Мы использовали методики
интеллектуального анализа данных для решения конкретной
проблемы электронной судебной экспертизы.
Анекдот:
Интернет-брифинг президента ВВП.
Вопрос
анонимного
юзера:
– Вова, а тебе не западло отвечать на заранее отобранные вопросы?
Ответ
ВВП
анонимному
юзеру:
– Нет, Сидоров Николай Петрович из Ярославля, проживающий на улице Ленина, дом
16, кв 2, номер IP (такой-то), провайдер (такой-то), мне не в падлу отвечать на
заранее отобранные вопросы.
Реферирование (или аннотирование, или
суммаризация) — процесс получения
краткой версии документа, которая
раскрывала бы его суть. Вы наверняка
сталкивались с аннотациями книг,
газетных и новостных статей,
составленными людьми. Автоматическое же
реферирование происходит с помощью
компьютерной программы. Автоматическим
реферированием инженеры занимаются с
50-х. Одна из первых работ на эту тему —
статья Ханса Петера Луна 1958 года.
Автоматическая генерация протоколов совещаний https://habr.com/ru/company/digdes/blog/597657/ Автоматическое формирование итогов собрания
можно назвать задачей суммаризации. Существует
два разных подхода к автоматической суммаризации:
экстрактивный и абстрактивный. Экстрактивная суммаризация направлена на
выявление важной информации, ее извлечение и
группирование для формирования краткого резюме. Абстрактивная суммаризация предполагает
генерацию новых предложений на основе
информации, извлеченной из корпуса.
 Удо Хан
(профессор университета Фрайбурга
(Германия):
Искусство краткого изложения материала, иными словами,
извлечения наиболее важных или характерных
фрагментов из одного или многих источников
информации, стало неотъемлемой частью повседневной
жизни.
Удо Хан
(профессор университета Фрайбурга
(Германия):
Искусство краткого изложения материала, иными словами,
извлечения наиболее важных или характерных
фрагментов из одного или многих источников
информации, стало неотъемлемой частью повседневной
жизни.