|
Адресный и семантический
Адресный поиск
- поиск документов по их формальным признакам, указанным в запросе.
Семантический поиск
- поиск документов по их содержанию
(семантическому).
При адресном
поиске документ рассматривается как объект с точки зрения формы
(формальным признаком может быть любая текстовая реальность документа -
последовательность символов, их частота, параметры форматирования,
указатели и проч.), а при
семантическом поиске — с точки зрения семантики
документа (тематической (онтологической) интенциональности
(направленности) документа и содержащейся в документе информации о
внетекстовой реальности)
 Семантический
поиск - машинный поиск
в
ресурсах, информационное (семантическое) содержание которых распознаваемо машинами. Семантический
поиск - машинный поиск
в
ресурсах, информационное (семантическое) содержание которых распознаваемо машинами.
Семантический
поиск предполагает наличие сети
документов, содержащих метаданные о ресурсах Web и существующей
параллельно с ними.
Ресурсы Web предназначены для восприятия человеком,
а метаданные используются машинами (поисковыми роботами и другими
интеллектуальными агентами) для проведения логических заключений о
семантических свойствах этих ресурсов.
Концепция Semantic Web
представлена в
2002 году
Тимом Бернерсом-Ли.
|
Методы автоматизации
семантического анализа текстов
|
Основные методы автоматизации семантического
анализа естественно–языковых текстов:
-
интерпретация синтаксических и
поверхностно–семантических моделей (словарь понятий, на который
отображаются лексемы, словокомплексы и правила этого отображения).
Сложны, объемны и существенно изменяются от одной предметной области
к другой, что значительно снижает эффективность их практического
использования в организации семантического поиска, классификации,
автореферирования и т. п.
-
создание глубинно-семантической модели
(формализованной нотации системы однозначных структурированных
понятий) и и разметка текста на ее основе). Получает все большое
распространение за счет простоты, гибкости, расширяемости.
Условие
семантического поиска
-
перевод содержания
документов и запросов с естественного языка на информационно-поисковый
язык и составление поисковых образов документа и запроса.
Поисковый образ
документа
(Search pattern of a document)
- текст, состоящий из лексических единиц информационно-поискового
языка, выражающий основное смысловое содержание
документа или информационного запроса и предназначенный для реализации
информационного поиска.
21.04.2016
-
До конца 2016 года Роскомнадзор запустит
на всей территории РФ автоматизированную систему контроля СМИ (годовой
доклад)
-
Уже сегодня система позволяет
обрабатывать в постоянном режиме материалы 7 тыс. электронных
периодических и сетевых СМИ. Поиск нарушений основывается на
выявлении определённых
сочетаний конкретных слов, что позволяет на первом этапе
анализа выбрать только те материалы СМИ, в которых потенциально
содержатся признаки нарушений.
-
Некоторые крупные СМИ видят
в инициативе Роскомнадзора «элементы цензуры».
-
Система работы
СМИ может быть организована по
китайскому образцу, объяснил председатель
Следственного комитета Александр Бастрыкин. Это необходимо для
общественного блага: для борьбы с детской порнографией,
экстремизмом, расжиганием розни и растлением молодёжи, чтобы
оградить людей от вредоносной и опасной информации. (в условиях
информационного давления на Россию).
|
Семантическая
модель
|
В основе семантической модели лежит следующая идея:
человек представляет окружающий его мир в виде объектов, характеризуемых
свойствами (состояниями) и отношениями (взаимодействиями). Состояния и
отношения объектов постоянно изменяются.
Задача автоматизации семантической обработки
информации в Web решалась на основе связки XML + RDF, в которой:
-
язык XML играет роль синтаксиса
(формализованной нотации),
-
модель RDF — роль семантической модели
(структурированного набора смысловых понятий).
|
Языковая
основа
Semantic Web
|
В основе
Semantic Web лежат
языки описания и разметки, в том числе:
-
XML
синтаксически (без семантики) определяет структуру документа, подлежащего
машинной обработке.
-
XML Schema
(один из языков описания структуры
XML документа) определяет
ограничения на структуру XML-документа в соответствии с его схемой.
-
RDF
(Resource Description Framework, язык для описания ресурсов,
и
метаданных о ресурсах) описывает данные в формате субъект-отношение-объект
идентификаторами ресурсов и
отображает эти описания на XML-документы.
-
RDF
Schema описывает набор отношений, для определения новых
типов RDF-данных.
-
OWL
(Web
Ontology Language, язык
онтологии для
Интернета на основе
XML/Web
стандарта) описывает новые типы данных RDF Schema в терминах
существующих.
В основе языка
OWL
— представление действительности в модели
данных объект — свойство. Каждому элементу описания в этом языке
ставится в соответствие
URL, связи между элементами организовывает на базе модели объект — свойство.
OWL пригоден не только для
описания web страниц, но и любых объектов
действительности.
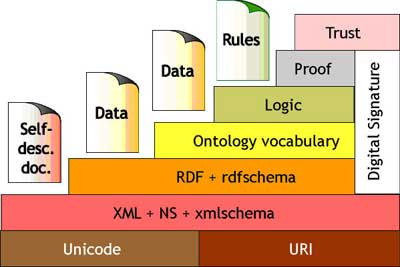
Ресурсы и их метаданные
являются
статической частью семантической паутины, а её динамическую часть представляют
семантические
Web-сервисы.
|
Семантико-прагматическая модель документа
|
Создание семантических моделей, расширяющих
возможности RDF породило концепцию Semantic Web
и, в частности, трехуровневую семантико–прагматическую модель документа:
-
модель контекста создания документа (описания
автора, адресата и свойств документа),
-
прагматическая модель (описания прагматических
блоков, составляющих документ; базируется на формализации (по типам
иллокутивных актов) соответствия целей автора документа в отношении
адресата типам поверхностно–семантической организации текста)
-
семантическая модель (модель динамического
описания глубинной семантики документа).
Пример.
Газета «Вестник БрГУ» сообщила:
«Появилась информация о том, что Ева Адамовна Олова получила высший
рейтинг в проекте Переведем Coursera. Доподлинно известно, что 12 апреля
Ева Адамовна Олова приглашена в ABBYY».
Тогда семантико–прагматическое представление
данного сообщения выглядит в нотации XML так:
<?xml version="1.0"
encoding="cp866"?>
<МЕТА–ДОКУМЕНТ>
<ДОКУМЕНТ>
<НАЗВАНИЕ>Сообщение газеты “Вестник БрГУ”</НАЗВАНИЕ>
<ДАТА>20.03.2000</ДАТА>
<УЧАСТНИК_ОБЩЕНИЯ Имя=”Вестник БрГУ” Тип=”Автор”>
<СОЦИАЛЬНЫЙ_СТАТУС>
<ХАРАКТЕРИСТИКА>Печатное издание</ХАРАКТЕРИСТИКА>
</СОЦИАЛЬНЫЙ_СТАТУС>
</УЧАСТНИК_ОБЩЕНИЯ>
</ДОКУМЕНТ>
<ПРАГМАТИЧЕСКАЯ_МОДЕЛЬ>
<ПРАГМА–БЛОК Имя=”Появилась информация”>
<ЦЕЛЬ Тип=”Передача_информации”/> <ЦЕЛЬ
Тип=”Изменение_эмоц_состония”/>
<СРЕДСТВО Тип=”Предположение”/>
<ТЕКСТ> Появилась информация о том, что Ева Адамовна Олова
получила высший рейтинг в проекте Переведем Coursera.
</ТЕКСТ>
</ПРАГМА–БЛОК>
<ПРАГМА–БЛОК Имя=”Доподлинно известно”>
<ЦЕЛЬ Тип=”Передача_информации”/> <ЦЕЛЬ
Тип=”Изменение_эмоц_состония”/>
<СРЕДСТВО Тип=”Утверждение”/>
<ТЕКСТ> Доподлинно известно, что 12 апреля Ева Адамовна Олова
приглашена в ABBYY.
</ТЕКСТ>
</ПРАГМА–БЛОК>
</ПРАГМАТИЧЕСКАЯ_МОДЕЛЬ>
<СЕМАНТИЧЕСКАЯ_МОДЕЛЬ>
<ОБЪЕКТ Имя=”Ева Адамовна Олова”>
<НАЧАЛЬНОЕ_СОСТОЯНИЕ>
<СВОЙСТВО> <ИМЯ>Место нахождения</ИМЯ>
<ЗНАЧЕНИЕ>Брест</ЗНАЧЕНИЕ>
</СВОЙСТВО>
</НАЧАЛЬНОЕ_СОСТОЯНИЕ>
<ПЕРЕХОД Характер=”Появление” UID=”Переход#1”>
<ВРЕМЯ> <ДО Измерение=”Время” Значение=”12.04.2014”/>
</ВРЕМЯ>
<ОТНОШЕНИЕ Имя =”Участие в проекте” UID=”Отношение#1”>
<РОЛЬ>Актер</РОЛЬ>
<СВОЙСТВО><ИМЯ>Место проекта</ИМЯ> <ЗНАЧЕНИЕ>ABBYY</ЗНАЧЕНИЕ>
</СВОЙСТВО>
</ОТНОШЕНИЕ>
</ПЕРЕХОД>
<ПЕРЕХОД Характер=”Изменение” UID=”Переход#2”>
<ВРЕМЯ> <В_МОМЕНТ Измерение=”Время” Значение=”12.04.2014”/>
</ВРЕМЯ>
<ПРИЧИНА> <ССЫЛКА UID=”Отношение#1”/> </ПРИЧИНА>
<СВОЙСТВО UID=”Свойство#1–2”>
<ИМЯ>Место нахождения</ИМЯ> <ЗНАЧЕНИЕ>Москва</ЗНАЧЕНИЕ>
</СВОЙСТВО>
</ПЕРЕХОД>
<КОНЕЧНОЕ_СОСТОЯНИЕ>
<СВОЙСТВО Ссылка=”Свойство#1–2”/> <ОТНОШЕНИЕ
Ссылка=”Отношение#1”/>
</КОНЕЧНОЕ_СОСТОЯНИЕ>
</ОБЪЕКТ>
</СЕМАНТИЧЕСКАЯ_МОДЕЛЬ>
</МЕТА–ДОКУМЕНТ>
Семантико–прагматическая модель позволяет создать
формальное XML-описание аналитической информации о смысловом содержимом
документа, допускающее различные алгоритмы его анализа стандартными
программными инструментами (XML–парсерами).
Предполагалось, что все будет XML, однако ... это
оказалось слишком сложно ... для практики информационного общества
потребления...
Новое направление в контексте становления
Semantic Web
открывает концепция
микроразметки.
|
Микроразметка
|
Микроразметка
(семантическая разметка) - разметка страницы с дополнительными тегами и
атрибутами в тегах, которые указывают поисковым роботам на то, о чем
написано на странице.
Микроразметка состоит из
словаря и синтаксиса:
-
словарь
(своеобразный «язык»
микроразметки) - набор классов и их свойств, с помощью
которых указывается суть содержимого на странице. Например, словарь
определяет, с помощью какого термина указывать название — «name»,
«title» или «n».
-
синтаксис
— это способ использования такого языка, т.е. словаря. Он определяет,
с помощью каких тегов и как будут указываться сущности и их свойства,
например, на веб-страницах.
Концепция семантической
разметки разными
инициативныи группами различно
реализовывалась на практике, что привело к винегрет из
разных словарей и синтаксисов.
Популярные
словари (языки) микроразметки:
-
Open Graph
(самый распространенный и простой словарь от Facebook. Распознается
также Вконтакте, Google+, Twitter,LinkedIn, Pinterest и др.. );
-
Schema.org
(самый функциональный и
перспективный);
-
Микроформаты
(создан в 2007 году сообществом энтузиастов для семантической
разметки сайтов на основе существующих технологий. Теряет
популярность);
-
FOAF
(от Friend of a Friend — «друг друга») специализируется на
отношениях между людьми, используется в поиске по блогам,
-
Dublin Core
(создан Google, разработка перешлоа в Schema.org),
-
Data Vocabulary
(создан для библиотечного и музейного дела в 1995 году, огромное
число классов и свойств).
-
Good Relations
(для описания отдельных продуктов электронной торговли).
|
Микроданные и микроформаты
|
Вопрос:
Есть ли различие между микроданными и микроформатами
и в чем оно?
Ответ:
Все зависит от контекста (винегрет значений). В
большинстве случает нет различия. В других случаях десятки различий.
|
Schema.org
|

Schema.org
– стандарт семантической разметки данных в в HTML5, объявленный
поисковыми системами Google, Bing и Yahoo! летом 2011 года.
С ноября 2011 года в
Schema.org
активно участвует Яндекс.
Объединение
ведущих поисковиков мира в проекте
Schema.org
стало самым значительным событием 2011
года в сфере интернет-поиска.
Цель
Schema.org
–
сделать Интернет более понятным,
структурированным и облегчить поисковым системам и специальным
программам извлечение и обработку информации для удобного её
представления в результатах поиска.
Метаданные на ресурсах,
использующие предлагаемые
Schema.org схемы,
представляют собой семантическую разметку, предназначенную для поисковых
роботов, и могут быть непосредственно проанализированы ими с целью
извлечения и обработки информации о содержимом веб-ресурсов.
В
качестве основного формата разметки веб-страницы метаданными
Schema.org
(микроразметки)
предлагаются microdata
(микроданные,
микроформаты) – теги
и атрибуты для разметки структурированной информации на веб-страницах,
появившиеся в стандарте HTML5.
Помимо
microdata,
существует возможность применения онтологии schema.org, выраженной в
формате RDFS при разметке RDF-данных.
Schema.org можно
использовать на веб-страницах на любом языке. |
Микроформаты
|
Микроформаты
(microdata)
– это сущности поверх HTML, с помощью которых можно описывать
любую информацию на Web-страницах.
Спецификация микроформатов HTML5
представляет собой способ пометки содержания для определения
любого
специального типа информации.
Наиболее обобщенный тип сущности –
это Thing (нечто), у которого есть четыре свойства: name (название),
description (описание), url (ссылка) и image.
Более специализированные, частные
типы имеют общие свойства с более универсальными.
Примеры
популярных типов сущностей:
-
CreativeWork (творческое
произведение),
-
Book (книга),
-
Movie (фильм),
-
MusicRecording (музыкальная
запись),
-
Recipe (рецепт),
-
TVSeries (телесериал),
-
AudioObject (аудио),
-
ImageObject (изображение),
-
VideoObject (видео),
-
Event (событие),
-
Organization (организация),
-
Person (человек),
-
Place (место),
-
Product (продукт),
-
Offer (предложение),
-
Review (отзыв)...
Разметка микроформатами не требует
создания отдельных экспортных файлов и происходит непосредственно в
HTML-коде страниц оборачиванием описания определенного типа в контейнер
и указанием схемы разметки отдельных свойств с помощью специальных
атрибутов.
Каждый тип информации описывает определенный тип элемента,
например, человека, мероприятие или отзыв.
Например, человек имеет
свойства: имя, место жительства, место работы, занимаемая должность и
т.д.
Schema.org
предусматривает возможность добавлять свойства и дочерние типы для
имеющихся типов сущностей.
Разметка
микроформатами не требует создания отдельных экспортных файлов и
происходит непосредственно в HTML-коде страниц оборачиванием
описания определенного типа в контейнер и указанием схемы разметки
отдельных свойств с помощью специальных атрибутов.
Каждый тип
информации описывает определенный тип элемента, например, человека,
мероприятие или отзыв. Например, человек имеет свойства: имя, место
жительства, место работы, занимаемая должность и т.д.
Пример
(фрагмент документа с информацией об авторе, с разметкой на
основе микроформата hCard (vCard) – для публикации
контактной информации людей, компаний, организаций и мест):
<div itemscope
itemtype="http://data-vocabulary.org/Person">
Мое имя <span itemprop="name">Михаил Концевой</span>,
Вот главная страница моего университета:
<a href="http://www.brsu.by" itemprop="url">www.brsu.by</a>.
Я живу в
<span itemprop="address" itemscope
itemtype="http://data-vocabulary.org/Address">
<span itemprop="locality">Бресте</span>,
<span itemprop="country-name">Беларусь</span>
</span>
и работаю <span itemprop="title">преподавателем</span>
<span itemprop="role">информатики</span>
в <span
itemprop="affiliation">БрГУ
им.
А.С. Пушкина</span>.
</div>
В первой строке itemscope указывает, что <div> является элементом. itemtype="http://data-vocabulary.org/Person
указывает, что это элемент "человек".
Каждое свойство
элемента "человек" отмечается атрибутом itemprop. Например, itemprop="name"
описывает имя человека.
Свойство address
само по себе является элементом, содержащим собственный набор
свойств. Для их определения можно добавить в элемент атрибут itemscope, который объявляет свойство address, и с помощью атрибута itemtype указать тип описываемого элемента следующим образом: <span
itemprop="address" itemscope itemtype="http://data-vocabulary.org/Address">.
Свойство title
указывает на должность, role – на специализацию, affiliation –
название организации, с которой связан этот человек (например, место
работы).
Извлечение
данных поисковыми роботами из микроформатной разметки осуществляется
одновременно с проводимой им индексацией сайта.
Микроформаты –
полностью открытый формат. Данные, размеченные по
стандарту семантической разметки schema.org, становятся
общедоступными и могут быть извлечены и использованы любыми
сервисами.
|
Инструментарий микроразметки
|
Код
микроформатов прост для написания в любом текстовом редакторе, но
лучше воспользоваться специальными программами, которые позволяют
добавлять микроформатированный контент в создаваемые с их помощью
документы:
Многие CMS (WordPress,
Moveable Type, Drupal, TextPatternи др.) предоставляют инструменты,
способные добавлять различный микроформатированный контент в блоги и
сайты, созданные с использованием этих систем.
|
Валидация микроразметки
|
Существует
несколько специализированных сервисов, с помощью которых можно
Полезно
использовать инструменты
|
Особенности парсинга микроформатов
|
Парсинг
микроформатов имеет особенности в сравнении с XML-парсингом.
Причина:
микроформаты рассчитаны на работу с HTML, для которого не
обязательно документ должен быть корректно сформирован (допускается
отсутствие закрывающих тегов и т.п.).
Если
использовать для извлечения микроформатов XSLT, то необходимо,
прежде всего, откорректировать HTML-документ с помощью TIDY, HTMLlib
или loadHTML, после чего можно использовать шаблоны XSLT,
выполняющие большинство работы по извлечению микроформатных данных.
|
Knowledge
Graph
|
17.05.2012
Google запустила семантический инструмент
Knowledge Graph
(граф знаний), благодаря которому поисковая система соотносит запросы
пользователей с базой данных, содержащей 500 млн объектов (людей, мест и
объектов).
Сведения для новой функции поиска Google
берет из открытых онлайновых источников ("Википедии", справочника
CIA World Factbook, других проиндексированных поисковиком сайтов).
Knowledge Graph
собирает все возможные варианты значений и выдает краткое резюме в
правом блоке. В поисковой выдаче Google теперь отображаются ключевые «атрибуты», которые поисковик связывает с тем или иным запросом. Все данные постоянно обновляются. Семантический поиск пока работает только в англоязычной версии
Google.
В компании говорят, что это лишь первый
шаг в превращении из "поисковика информации" в "поисковик знаний".
|
 |